Tin tức & Sự kiện
Những thông tin cập nhật mới nhất từ Trung Tâm Ngoại Ngữ Tin Học Nguyễn Minh

Trí Tuệ Nhân Tạo Biên (Edge AI): Sự Lên Ngôi Của Các Chip AI Siêu Nhỏ Tích Hợp Vào Thiết Bị IoT Thông Minh
1. Đáo ngược xu hướng: Từ Đám mây (Cloud) trở về Thiết bị biên (Edge) Trong suốt một thập kỷ qua, đám mây (Cloud Computing) được coi là trung tâm tính toán duy nhất của thế giới công nghệ. Mọi dữ liệu thu thập từ camera giám sát, cảm biến nhà thông minh hay thiết bị đeo theo dõi sức khỏe đều phải truyền qua mạng internet về các trung tâm dữ liệu khổng lồ để xử lý và phân tích bằng các mô hình AI đắt đỏ. Tuy nhiên, khi số lượng thiết bị IoT bùng nổ hàng tỷ đơn vị, mô hình tập trung trên Cloud bắt đầu bộc lộ những điểm yếu chết người: độ trễ mạng cao, nguy cơ rò rỉ quyền riêng tư và chi phí băng thông cực kỳ đắt đỏ. Thế giới công nghệ năm 2026 đang chứng kiến một cuộc đảo chiều lịch sử: sự trỗi dậy của **Trí tuệ nhân tạo biên (Edge AI)**. Thay vì gửi dữ liệu về đám mây, các thuật toán học máy được đưa thẳng xuống chạy trực tiếp trên các vi xử lý (NPU/MCU) tích hợp ngay trong thiết bị đầu cuối. Báo cáo chiến lược công nghệ dự báo có tới **hơn 70% dữ liệu doanh nghiệp** sẽ được xử lý trực tiếp tại biên vào năm 2026, đưa thị trường phần cứng Edge AI đạt giá trị khổng lồ **38 tỷ USD**. 2. Edge AI và TinyML là gì? Edge AI là việc thực thi các mô hình AI (như nhận diện hình ảnh, xử lý âm thanh, phát hiện bất thường) ngay trên phần cứng cục bộ của thiết bị mà không cần kết nối internet. Công nghệ mũi nhọn đứng sau làn sóng này chính là **TinyML (Tiny Machine Learning)**. TinyML là sự kết hợp giữa kỹ nghệ tối ưu hóa thuật toán AI (như nén mô hình, lượng tử hóa Pruning/Quantization) và các vi điều khiển công suất siêu thấp: Công suất tiêu thụ cực kỳ nhỏ: Các mô hình TinyML có thể chạy liên tục 24/7 trên các chip cảm biến sử dụng pin đồng xu với mức tiêu thụ điện năng chưa tới **1 milliwatt**. Độ trễ siêu tốc dưới 5 mili-giây: Do không phải tốn thời gian truyền dữ liệu qua mạng internet lên đám mây, Edge AI đưa ra phản hồi thời gian thực chỉ trong **chưa đầy 5ms**, điều tối quan trọng cho các ứng dụng phanh tự động của xe tự lái hay robot phẫu thuật y tế. 3. Những ưu thế tuyệt đối khiến Edge AI trở thành chuẩn mực mới Việc chuyển dịch từ Cloud AI sang Edge AI mang lại những lợi ích đột phá cho các nhà phát triển và doanh nghiệp: Bảo mật riêng tư tuyệt đối (100% Privacy Compliance): Dữ liệu nhạy cảm như video từ camera trong nhà, giọng nói cá nhân hay dữ liệu nhịp tim không bao giờ rời khỏi thiết bị. Điều này giúp các ứng dụng dễ dàng tuân thủ các đạo luật bảo mật khắt khe nhất thế giới như GDPR hay HIPAA. Tiết kiệm 80% chi phí băng thông và API đám mây: Doanh nghiệp không còn phải trả chi phí lưu trữ đám mây đắt đỏ cho hàng petabyte dữ liệu video thô. Thiết bị Edge chỉ gửi về đám mây các cảnh báo thực sự quan trọng. Khả năng hoạt động ngoại tuyến (Offline Availability): Thiết bị IoT thông minh vẫn vận hành chính xác và đưa ra cảnh báo ngay cả khi mất toàn bộ kết nối mạng internet hoặc trong điều kiện môi trường khắc nghiệt như hầm mỏ, trang trại xa xôi. 4. Các ứng dụng thực tế bùng nổ của Edge AI năm 2026 Edge AI đang thay đổi diện mạo của hàng loạt ngành công nghiệp: Nông nghiệp thông minh: Các cảm biến Edge AI gắn trên đồng ruộng có thể phân tích hình ảnh lá cây để phát hiện sâu bệnh và tự động điều khiển phun thuốc chính xác vào vùng bị bệnh, giảm **50% lượng hóa chất** bảo vệ thực vật. Bảo trì dự đoán trong công nghiệp (Predictable Maintenance): Các chip TinyML gắn trực tiếp trên động cơ nhà máy liên tục phân tích độ rung và âm thanh để phát hiện hỏng hóc tiềm ẩn trước khi máy móc bị sụp đổ, tiết kiệm hàng triệu USD chi phí dừng máy cho doanh nghiệp. Thiết bị đeo sức khỏe thế hệ mới: Đồng hồ thông minh tích hợp Edge AI có thể phân tích biểu đồ điện tâm đồ (ECG) theo thời gian thực để cảnh báo nguy cơ đột quỵ ngay lập tức cho người dùng. 5. Kết luận Kỷ nguyên của các thiết bị 'ngốc ngếch' phụ thuộc hoàn toàn vào đám mây đã khép lại. Sự bùng nổ của Edge AI và TinyML đang biến mỗi thiết bị IoT xung quanh chúng ta thành một bộ não thông minh độc lập. Làm chủ công nghệ Edge AI chính là chìa khóa mở ra thế giới kết nối thông minh thực sự trong tương lai số. Tương lai của AI không nằm ở những trung tâm dữ liệu xa xôi, mà nằm ngay trên những mắt chip nhỏ bé trong lòng bàn tay bạn.

Sự Bùng Nổ Của Cơ Sở Dữ Liệu Vector (Vector Databases) Và Lối Đi Tối Ưu Hệ Thống Tìm Kiếm Cho Doanh Nghiệp
1. Giới hạn của cơ sở dữ liệu truyền thống trong kỷ nguyên AI Trong hơn 4 thập kỷ qua, các cơ sở dữ liệu quan hệ (RDBMS như PostgreSQL, MySQL) và NoSQL (như MongoDB) đã thống trị thế giới phần mềm nhờ khả năng lưu trữ và truy vấn dữ liệu cấu trúc cực kỳ chính xác. Tuy nhiên, khi trí tuệ nhân tạo bùng nổ, hơn 80% dữ liệu của doanh nghiệp lại tồn tại dưới dạng phi cấu trúc (unstructured data) như văn bản tài liệu dài, hình ảnh, âm thanh và video. Các hệ thống tìm kiếm từ khóa truyền thống (keyword search dựa trên khớp chuỗi exact match) bộc lộ điểm yếu lớn: chúng hoàn toàn không hiểu được ý nghĩa ngữ nghĩa (semantic meaning) đằng sau câu hỏi của người dùng. Ví dụ, khi người dùng tìm kiếm 'người dẫn đường cho xe hơi', công cụ tìm kiếm từ khóa cũ sẽ thất bại nếu bài viết chỉ chứa từ 'hệ thống định vị GPS'. Đây chính là lý do công nghệ **Cơ sở dữ liệu Vector (Vector Databases)** ra đời và bùng nổ mạnh mẽ, được dự báo đạt quy mô thị trường toàn cầu **4.2 tỷ USD** vào năm 2026 với tốc độ tăng trưởng hàng năm trên 28%. 2. Cơ sở dữ liệu Vector là gì và cách thức vận hành? Cơ sở dữ liệu Vector là hệ thống lưu trữ được thiết kế chuyên biệt để quản lý và truy vấn các chuỗi số đại diện cho dữ liệu dưới dạng toán học, gọi là **Vector Embeddings** (chuỗi nhúng vector). Các mô hình AI (như OpenAI text-embedding, Cohere) biến đổi văn bản, hình ảnh thành các tọa độ điểm trong không gian đa chiều (thường từ 768 đến 1536 chiều). Thay vì so sánh chính xác từng chữ, Vector DB sử dụng thuật toán tìm kiếm láng giềng gần nhất (Approximate Nearest Neighbor - ANN) để đo khoảng cách góc (Cosine Similarity hoặc Euclidean Distance) giữa các vector. Điều này cho phép hệ thống tìm ra các đoạn văn bản hoặc hình ảnh có ý nghĩa tương đồng nhất với câu hỏi của người dùng chỉ trong chưa đầy **15 mili-giây**, ngay cả trên tập dữ liệu khổng lồ hàng tỷ vector. 3. Ứng dụng cốt lõi: Nâng cấp RAG và triệt tiêu 'Ảo giác AI' Ứng dụng quan trọng nhất của Vector Database hiện nay nằm ở việc xây dựng kiến trúc **Retrieval-Augmented Generation (RAG)** cho các doanh nghiệp. Mặc dù các mô hình ngôn ngữ lớn (LLM) rất thông minh, chúng thường gặp phải hội chứng 'ảo giác' (hallucination - tự bịa ra thông tin sai sự thật) hoặc không có dữ liệu nội bộ riêng tư của doanh nghiệp. Bằng cách tích hợp các Vector DB nguồn mở và thương mại hàng đầu như Pinecone, Qdrant, Milvus hay ChromaDB vào hệ thống RAG: Khi người dùng đặt câu hỏi, hệ thống sẽ truy vấn Vector DB để lấy ra đúng các đoạn tài liệu nội bộ liên quan nhất. Gửi các đoạn tài liệu này làm bối cảnh (context) cho LLM để mô hình tổng hợp câu trả lời chính xác 100%. Thực nghiệm chứng minh, giải pháp này giúp giảm tỷ lệ ảo giác của LLM từ trên 25% xuống dưới **4%**, mở ra cơ hội đưa chatbot AI vào các lĩnh vực đòi hỏi độ chính xác tuyệt đối như y tế, pháp lý và tài chính. 4. Chiến lược Hybrid Search: Lối đi tối ưu hệ thống tìm kiếm doanh nghiệp Dù Vector Search rất mạnh mẽ về mặt ngữ nghĩa, nó đôi khi lại bỏ sót các từ khóa chính xác chuyên ngành (như mã sản phẩm, mã lỗi code, tên riêng). Do đó, các kiến trúc sư phần mềm năm 2026 đang áp dụng chiến lược **Tìm kiếm lai (Hybrid Search)**—sự kết hợp hoàn hảo giữa tìm kiếm từ khóa truyền thống (BM25) và tìm kiếm ngữ nghĩa vector: Tăng độ chính xác kết quả tìm kiếm lên 35%: Hybrid Search kết hợp điểm số của cả hai phương pháp, đảm bảo vừa bắt được ý nghĩa tổng thể vừa không bỏ sót các từ khóa chuyên biệt. Tăng 50% tỷ lệ nhấp chuột (CTR): Các trang thương mại điện tử và hệ thống quản trị tri thức doanh nghiệp áp dụng Hybrid Search ghi nhận sự bứt phá lớn về trải nghiệm người dùng. Tối ưu hóa chi phí phần cứng: Áp dụng các kỹ thuật nén vector như Product Quantization (PQ) giúp cắt giảm chi phí lưu trữ bộ nhớ RAM của hệ thống Vector DB lên tới **75%**. 5. Kết luận Cơ sở dữ liệu Vector không chỉ là một công nghệ lưu trữ mới, mà là thành tố hạ tầng cốt lõi trong thời đại AI. Doanh nghiệp làm chủ kiến trúc Vector Search và RAG ngay hôm nay sẽ sở hữu lợi thế cạnh tranh khổng lồ trong việc khai phá giá trị từ khối tài sản dữ liệu phi cấu trúc của mình. Trong kỷ nguyên AI, dữ liệu không chỉ cần được lưu trữ, nó cần được hiểu theo đúng ngữ nghĩa.

Làm Chủ Tiếng Anh Đàm Phán Hợp Đồng Outsourcing: Mẫu Câu Và Kỹ Năng Xử Lý Tranh Chấp Kỹ Thuật Với Đối Tác Nước Ngoài
1. Bối cảnh bùng nổ Outsourcing IT và rào cản giao tiếp quốc tế Ngành gia công phần mềm (IT Outsourcing) tại Việt Nam đang trải qua giai đoạn phát triển rực rỡ nhất trong lịch sử. Với tốc độ tăng trưởng ấn tượng, doanh thu thị trường này dự kiến sẽ cán mốc **3.5 tỷ USD** vào năm 2026, khẳng định vị thế của Việt Nam như một trung tâm công nghệ hàng đầu khu vực phục vụ các đối tác lớn đến từ Bắc Mỹ, Châu Âu và Nhật Bản. Tuy nhiên, bên cạnh năng lực kỹ thuật giỏi, rào cản ngôn ngữ và kỹ năng giao tiếp tiếng Anh thương mại vẫn là điểm yếu cố hữu của nhiều nhóm kỹ sư phần mềm Việt Nam. Khảo sát các dự án xuất khẩu phần mềm cho thấy, có tới **45% trường hợp dự án bị trễ hạn (delay) hoặc vượt ngân sách** bắt nguồn từ sự bất đồng trong giao tiếp và hiểu sai yêu cầu kỹ thuật giữa hai bên. Khi xảy ra sự cố kỹ thuật hoặc phát sinh yêu cầu mới (Scope Creep), việc thiếu kỹ năng đàm phán tiếng Anh chuyên nghiệp dễ dẫn đến những tranh chấp hợp đồng căng thẳng, làm suy giảm uy tín của doanh nghiệp trên trường quốc tế. Hơn **70% đối tác quốc tế** thừa nhận họ sẵn sàng trả chi phí cao hơn cho các đội ngũ có khả năng giao tiếp tiếng Anh mượt mà và chủ động. 2. Giải mã các thuật ngữ pháp lý và kỹ thuật cốt lõi trong hợp đồng IT Để đàm phán hiệu quả, lập trình viên và quản trị dự án (PM) phải làm chủ các khái niệm nền tảng trong hợp đồng outsourcing quốc tế: SOW (Statement of Work - Bảng mô tả công việc): Văn bản pháp lý chi tiết hóa toàn bộ phạm vi dự án, các tính năng cần phát triển, mốc thời gian bàn giao (milestones) và tiêu chí nghiệm thu. Chuẩn hóa các mẫu SOW giúp rút ngắn thời gian thương thảo hợp đồng từ 4 tuần xuống chỉ còn **1 tuần**. SLA (Service Level Agreement - Cam kết chất lượng dịch vụ): Điều khoản quy định chỉ số hiệu năng tối thiểu hệ thống phải đạt được (như thời gian hoạt động uptime **99.9%**, thời gian phản hồi sự cố dưới 2 giờ). Thiết lập SLA rõ ràng giúp giảm tới **60% các tranh chấp hợp đồng** trong quá trình vận hành hệ thống. Change Request (CR - Yêu cầu thay đổi): Quy trình thống nhất chi phí và thời gian phát sinh khi khách hàng muốn bổ sung tính năng mới ngoài phạm vi SOW ban đầu. 3. Bộ mẫu câu tiếng Anh chuyên nghiệp cho từng tình huống đàm phán Dưới đây là các mẫu câu tiếng Anh giao tiếp chuẩn mực giúp bạn làm chủ cuộc hội thoại và giữ vững vị thế chuyên nghiệp khi làm việc với đối tác nước ngoài:

Giáo Dục STEM Thế Hệ Mới: Đưa Robot Tự Trị Và MicroPython Vào Lớp Học Để Phát Triển Tư Duy Thuật Toán Thực Tế
1. Lối mòn của giáo dục tin học truyền thống và sự trỗi dậy của STEM Trong nhiều thập kỷ, môn Tin học tại các trường phổ thông thường bị giới hạn trong việc học cách sử dụng các ứng dụng văn phòng cơ bản như Word, Excel hoặc làm quen với những thuật toán lý thuyết khô khan trên màn hình máy tính. Cách tiếp cận này vô tình tạo ra khoảng cách lớn giữa lý thuyết học đường và ứng dụng thực tế. Học sinh dễ cảm thấy nhàm chán và khó hình dung cách lập trình giải quyết các bài toán trong đời sống thực tế thế nào. Giáo dục STEM (Science, Technology, Engineering, Mathematics) thế hệ mới ra đời để phá vỡ lối mòn đó. Thay vì học lập trình một cách thụ động, STEM hướng học sinh tới **vật lý máy tính (Physical Computing)**—nơi các dòng code không chỉ hiển thị chữ trên màn hình mà có thể điều khiển bánh xe robot quay, bật tắt đèn led, hay đọc dữ liệu từ cảm biến nhiệt độ. Khảo sát giáo dục cho thấy, có tới **85% học sinh** tăng cường sự tập trung và phát triển tư duy logic vượt trội khi được học lập trình thông qua việc tương tác trực tiếp với phần cứng thực tế. 2. MicroPython: Chiếc cầu nối hoàn hảo đưa học sinh vào thế giới lập trình phần cứng Trước đây, để lập trình các vi mạch điều khiển (như Arduino), học sinh bắt buộc phải học C hoặc C++—những ngôn ngữ cấp thấp phức tạp với các quy tắc cú pháp nghiêm ngặt, dễ gây nản lòng cho người mới bắt đầu. Sự xuất hiện của **MicroPython** đã thay đổi hoàn toàn cuộc chơi. MicroPython là phiên bản rút gọn tối ưu của ngôn ngữ lập trình Python nổi tiếng, được thiết kế đặc biệt để chạy mượt mà trên các chip vi điều khiển có tài nguyên cực kỳ hạn chế: Yêu cầu tài nguyên siêu nhỏ: MicroPython chỉ cần ít hơn **256KB** dung lượng lưu trữ mã nguồn và vỏn vẹn **16KB** bộ nhớ RAM để vận hành trơn tru. Chi phí tiếp cận siêu rẻ: Chạy mượt mà trên các bảng mạch như Raspberry Pi Pico hay ESP32 có giá thành chỉ dưới **5 USD** (khoảng hơn 100.000 VNĐ), giúp các trường học dễ dàng phổ cập thiết bị cho mọi học sinh. Cú pháp thân thiện, trực quan: Thay vì viết hàng chục dòng code C++ rắc rối để nhấp nháy một bóng đèn led, học sinh chỉ cần đúng **5 dòng code** MicroPython ngắn gọn, dễ hiểu. Điều này giúp giảm rào cản tâm lý học lập trình ban đầu xuống mức thấp nhất. 3. Đưa Robot tự trị vào lớp học: Biến lý thuyết thành sản phẩm thực tế Đỉnh cao của việc học STEM vật lý máy tính là tự tay chế tạo và lập trình các **Robot tự trị mini**. Không đơn thuần là đồ chơi điều khiển từ xa, robot tự trị đòi hỏi học sinh phải thiết lập các thuật toán thông minh để chúng tự đưa ra quyết định: Thuật toán dò đường (Line Follower): Sử dụng các cảm biến hồng ngoại để phân tích độ tương phản và tự động điều chỉnh tốc độ hai động cơ bánh xe để robot bám theo vạch đen vẽ sẵn. Thuật toán tránh vật cản (Obstacle Avoidance): Kết hợp cảm biến sóng siêu âm phát hiện vật cản phía trước trong phạm vi 20cm, tự động điều hướng rẽ trái hoặc rẽ phải để tìm lối đi trống. Thông qua việc thiết lập thuật toán cho robot, học sinh được thực hành tư duy thiết kế (Design Thinking) và kỹ năng giải quyết vấn đề thực tế: Tại sao robot bị lệch hướng? Làm thế nào để robot đi qua khúc cua mượt mà hơn? Những bài toán thực hành này giúp điểm số kỹ năng giải quyết vấn đề tăng thêm **30%** trong các kỳ thi STEM chuẩn hóa quốc tế. 4. Tác động của giáo dục STEM Robotics đến tương lai nghề nghiệp học sinh Thị trường thiết bị robot giáo dục toàn cầu được dự báo sẽ đạt giá trị khổng lồ **3.5 tỷ USD** vào năm 2026. Sự bùng nổ này phản ánh xu hướng chuẩn bị nguồn nhân lực chất lượng cao từ sớm của các quốc gia phát triển: Khơi dậy đam mê công nghệ: Các trường học tích hợp giáo dục Robotics vào chương trình phổ thông ghi nhận mức tăng **40%** số lượng học sinh định hướng thi tuyển vào các ngành kỹ thuật và khoa học máy tính tại bậc đại học. Rèn luyện kỹ năng làm việc nhóm: Việc lắp ráp và lập trình robot đòi hỏi sự phân công công việc rõ ràng giữa các thành viên (bạn thiết kế cơ khí, bạn viết code MicroPython), giúp rèn luyện kỹ năng mềm cực kỳ cần thiết cho công việc sau này. 5. Kết luận Giáo dục STEM thế hệ mới kết hợp giữa Robot tự trị và MicroPython đang thổi một luồng sinh khí mới vào các lớp học phổ thông. Bằng cách trao cho học sinh cơ hội tự tay sáng tạo ra các sản phẩm công nghệ thực tế, chúng ta không chỉ dạy các em viết code, mà quan trọng hơn là trang bị cho các em tư duy thuật toán vững vàng để tự tin bước vào thế giới số tương lai. Đừng chỉ tiêu thụ công nghệ, hãy học cách kiến tạo công nghệ từ những bảng mạch nhỏ nhất.

Hội Chứng 'Mệt Mỏi Vì AI' (AI Fatigue) Và Kỹ Năng Duy Trì Sự Tập Trung Sâu Trong Môi Trường Số Nhiễu Loạn
1. Mặt tối của cuộc cách mạng AI: Khi công cụ năng suất gây kiệt sức Trong vài năm qua, chúng ta đã chứng kiến sự bùng nổ vũ bão của trí tuệ nhân tạo. Từ chatbot, trợ lý viết code, công cụ tạo ảnh đến các hệ thống tự động hóa tác vụ, AI hứa hẹn giải phóng con người khỏi công việc lặp đi lặp lại. Tuy nhiên, khi AI len lỏi vào từng ngóc ngách của cuộc sống công sở, một hội chứng tâm lý mới đã âm thầm xuất hiện: **Hội chứng mệt mỏi vì AI (AI Fatigue)**. Theo báo cáo khảo sát sức khỏe tinh thần công nghệ năm 2026, có tới **60% kỹ sư phần mềm và nhân viên văn phòng** thừa nhận họ cảm thấy quá tải và mệt mỏi trước làn sóng cập nhật liên tục của các công cụ AI. Thay vì giúp tiết kiệm thời gian, việc phải quản lý hàng chục chatbot, liên tục kiểm tra lỗi (hallucination) của AI và lo sợ bị tụt hậu công nghệ (FOMO) đang bào mòn năng lượng trí tuệ của người lao động. Khả năng tư duy độc lập của con người đang bị suy giảm nghiêm trọng khi liên tục bị ngắt quãng bởi các đề xuất tự động từ máy móc. 2. Cái giá của sự phân tâm trong môi trường số nhiễu loạn Sự phân tâm là kẻ thù số một của năng suất. Các nghiên cứu khoa học hành vi chỉ ra rằng, trung bình một nhân sự văn phòng bị gián đoạn công việc bởi các thông báo, email hoặc tin nhắn chat **11 phút một lần**. Đáng sợ hơn, sau khi bị ngắt quãng, bộ não phải mất trung bình **23 phút** để có thể quay trở lại trạng thái tập trung cao độ ban đầu. Khi liên tục chuyển đổi qua lại giữa các ứng dụng và giao diện AI, năng lực nhận thức (cognitive capacity) của chúng ta có thể bị sụt giảm tới **20%**. Việc đa nhiệm (multitasking) thực chất chỉ là ảo giác của năng suất; nó khiến bộ não liên tục hoạt động ở trạng thái căng thẳng nhẹ, dẫn đến sự suy kiệt năng lượng tư duy vào cuối ngày làm việc. 3. Lập lại trật tự: Phương pháp duy trì tập trung sâu (Deep Work) Để sống sót và bứt phá trong kỷ nguyên AI nhiễu loạn, kỹ năng quan trọng nhất không phải là học thêm một công cụ AI mới, mà là **làm chủ khả năng tập trung sâu (Deep Work)** theo định nghĩa của giáo sư Cal Newport. Tập trung sâu là khả năng làm việc không bị phân tán trong một trạng thái nhận thức cao độ để đẩy năng lực nhận thức của bạn tới giới hạn tối đa. Dưới đây là 3 bước cốt lõi giúp bạn rèn luyện Deep Work: Thiết lập bộ lọc tiếng ồn số nghiêm ngặt: Tắt toàn bộ thông báo không khẩn cấp từ các ứng dụng Slack, Zalo, Teams và đặc biệt là các chatbot AI khi bắt đầu phiên làm việc sâu. Nghiên cứu thực nghiệm chứng minh hành động đơn giản này giúp giảm nồng độ hormone gây stress Cortisol đi **30%**. Áp dụng phương pháp làm việc theo khối thời gian (Time-blocking): Dành riêng **2 đến 3 giờ** liên tục vào đầu ngày—thời điểm bộ não minh mẫn nhất—chỉ để thực hiện các tác vụ phức tạp đòi hỏi tư duy logic cao (như thiết kế kiến trúc hệ thống, viết thuật toán khó) mà hoàn toàn không có sự can thiệp của các công cụ AI hỗ trợ gợi ý code liên tục. Tạo dựng nghi thức bắt đầu và kết thúc (Shutdown Ritual): Định rõ thời gian bắt đầu và kết thúc ca làm việc sâu bằng các hành động vật lý (như dọn dẹp bàn làm việc, ghi lại các việc cần làm cho ngày mai) để báo hiệu cho não bộ bước vào trạng thái nghỉ ngơi hoàn toàn. 4. Vai trò của doanh nghiệp trong việc chống lại AI Fatigue Chống lại sự mệt mỏi công nghệ không chỉ là trách nhiệm cá nhân mà còn là bài toán quản trị của doanh nghiệp. Để bảo vệ sức sáng tạo của đội ngũ nhân sự, hơn **45% doanh nghiệp công nghệ hàng đầu** đã áp dụng các chính sách nhân văn mới: Khung giờ vàng không họp (No-meeting Friday): Dành riêng ngày thứ Sáu để nhân viên tự do nghiên cứu và làm việc sâu mà không bị gián đoạn bởi các cuộc họp trực tuyến. Hạn chế lạm dụng AI quá mức: Khuyến khích nhân viên chỉ sử dụng AI như một công cụ hỗ trợ lọc thông tin thô, thay vì để AI thay thế các bước lập luận logic cốt lõi. 5. Kết luận Trong kỷ nguyên mà AI có thể viết code, viết báo cáo và vẽ tranh thay con người, tài sản quý giá nhất của một chuyên gia không còn là khả năng tạo ra nội dung thô một cách nhanh chóng, mà là khả năng tư duy sâu sắc, giải quyết các vấn đề phức tạp và duy trì sự sáng tạo độc bản. Hãy học cách ngắt kết nối để kết nối sâu sắc hơn với trí tuệ của chính mình. Khi thế giới xung quanh ngày càng ồn ào và vội vã, sự im lặng và khả năng tập trung sâu chính là thứ vũ khí tối thượng giúp bạn bứt phá.

Phương Pháp Xây Dựng Hệ Thống Quản Trị Tri Thức Cá Nhân (Second Brain) Bằng Obsidian Và Liên Kết Mạng Nơ-ron Tư Duy
1. Quá tải thông tin số: Tại sao chúng ta cần một 'Bộ não thứ hai'? Trong kỷ nguyên số, mỗi ngày chúng ta bị dội bom bởi hàng ngàn mẩu tin tức, bài viết, video và tài liệu học tập. Tuy nhiên, khả năng ghi nhớ ngắn hạn của bộ não con người có giới hạn. Chúng ta thường quên tới **80% những gì đã học** chỉ sau 24 giờ nếu không ôn tập. Theo thống kê hiệu suất làm việc, một nhân sự tri thức trung bình lãng phí tới **2.5 giờ mỗi ngày** chỉ để tìm kiếm thông tin bị thất lạc trong các email, tin nhắn chat và thư mục file rải rác. Phương pháp 'Second Brain' (Bộ não thứ hai) được phát triển bởi chuyên gia năng suất Tiago Forte ra đời nhằm giải phóng bộ não sinh học khỏi nhiệm vụ lưu trữ thông tin, giúp chúng ta tập trung hoàn toàn vào việc sáng tạo, phân tích và giải quyết vấn đề. Bằng cách số hóa quy trình quản trị tri thức cá nhân (PKM - Personal Knowledge Management), doanh nghiệp và cá nhân có thể tối ưu hóa hiệu suất làm việc và học tập vượt trội. 2. Obsidian và sức mạnh của liên kết hai chiều (Bidirectional Linking) Trong số các công cụ ghi chú hiện đại, Obsidian nổi lên như một hiện tượng với hơn **5 triệu người dùng hoạt động** trên toàn thế giới vào năm 2025. Khác biệt cốt lõi của Obsidian so với các ứng dụng ghi chú truyền thống như Evernote hay OneNote nằm ở việc nó loại bỏ cấu trúc phân mục thư mục tĩnh (folders) và thay thế bằng mạng lưới liên kết động giống như cấu trúc các tế bào thần kinh trong não bộ. Obsidian cho phép lập trình viên và người tự học kết nối các ghi chú lại với nhau bằng **liên kết hai chiều (Bidirectional Links)** thông qua cú pháp wiki `[[Tên ghi chú]]`. Điều này tạo ra một đồ thị tri thức (Graph View) trực quan. Bạn có thể thấy rõ ý tưởng này bổ trợ cho ý tưởng kia thế nào, từ đó kích thích sự liên tưởng sáng tạo tăng thêm **35%** và tăng khả năng ghi nhớ chủ động lên **50%** so với cách ghi chú tĩnh. 3. Phương pháp Zettelkasten và PARA: Bộ đôi tối ưu hóa quản trị tri thức Để vận hành bộ não thứ hai hiệu quả trên Obsidian, chúng ta cần kết hợp hai phương pháp tư duy kinh điển: Quy trình ghi chú Zettelkasten (Mạng nơ-ron tri thức) Zettelkasten là phương pháp ghi chú được phát minh bởi nhà xã hội học người Đức Niklas Luhmann, giúp ông viết hàng chục cuốn sách trong sự nghiệp. Phương pháp này phân loại ghi chú thành 3 cấp độ: Fleeting Notes (Ghi chú thô/tạm thời): Ghi chép nhanh các ý tưởng nảy ra trong đầu hoặc khi đang đi trên đường. Literature Notes (Ghi chú tài liệu): Tóm tắt lại nội dung sách, bài báo hoặc video theo ngôn ngữ của riêng bạn để đảm bảo đã thực sự hiểu vấn đề. Permanent Notes (Ghi chú vĩnh viễn): Mỗi ghi chú chỉ chứa một ý tưởng duy nhất (tính nguyên tử - atomic), được liên kết chặt chẽ với các ghi chú cũ hơn thông qua liên kết hai chiều. Tổ chức thông tin theo hệ thống PARA Hệ thống PARA giúp phân loại bộ não thứ hai thành 4 vùng không gian hành động rõ ràng, tăng hiệu quả truy xuất thông tin lên **40%**: P - Projects (Dự án): Những công việc đang thực hiện có thời hạn hoàn thành (ví dụ: `Thiết kế landing page tháng 7`). A - Areas (Lĩnh vực): Trách nhiệm dài hạn cần duy trì ổn định (ví dụ: `Sức khỏe`, `Tài chính cá nhân`, `Học tiếng Anh`). R - Resources (Tài nguyên): Các chủ đề quan tâm có thể hữu ích trong tương lai (ví dụ: `Tài liệu lập trình Rust`, `Mẫu prompt AI`). A - Archives (Lưu trữ): Các mục đã hoàn thành từ 3 mục trên nhưng cần giữ lại để tham khảo khi cần. 4. Lợi ích vượt trội khi sử dụng Obsidian làm bộ não thứ hai Obsidian mang lại những ưu thế tuyệt đối cho người dùng chuyên nghiệp: Sở hữu dữ liệu 100% (Local-first): Ghi chú của bạn được lưu dưới dạng các file văn bản thuần túy (Markdown - `.md`) ngay trên máy tính cục bộ. Bạn không lo bị mất dữ liệu khi ứng dụng phá sản hay mất kết nối mạng. điều này bảo vệ quyền riêng tư tuyệt đối. Khả năng mở rộng vô hạn: Với hàng ngàn plugin do cộng đồng phát triển (như Dataview để truy vấn dữ liệu như SQL, Canvas để vẽ sơ đồ tư duy), bạn có thể biến Obsidian thành bất kỳ hệ thống quản lý nào mình muốn. Liên kết ngữ cảnh thông minh: Graph View giúp bạn phát hiện ra những điểm giao thoa bất ngờ giữa các lĩnh vực học tập khác nhau mà nếu để trong các folder truyền thống bạn sẽ không bao giờ nhận ra. 5. Kết luận Xây dựng Bộ não thứ hai bằng Obsidian không chỉ giúp bạn giải quyết bài toán quá tải thông tin, mà còn biến tri thức thụ động thành tài sản chủ động, có thể tái sử dụng lâu dài. Hãy dành ra 15 phút mỗi ngày để chăm sóc hệ thống PKM của mình, bạn sẽ thấy khả năng tư duy và năng suất làm việc của mình bứt phá rõ rệt trong thời gian ngắn. Bộ não của bạn là để tư duy và sáng tạo ý tưởng, không phải để lưu trữ chúng. Hãy để Obsidian làm việc đó cho bạn.

Làm Chủ Tự Động Hóa Văn Phòng Nâng Cao: Kết Hợp Python Và VBA Để Lập Báo Cáo Phân Tích Tự Động Trong 5 Phút
1. Nỗi ác mộng mang tên 'Báo cáo định kỳ' và giới hạn của Excel thủ công Đối với hầu hết nhân viên văn phòng, chuyên viên tài chính hay kế toán, những ngày cuối tháng luôn là thời điểm bận rộn và căng thẳng nhất. Nhiệm vụ thu thập dữ liệu từ hàng chục nguồn khác nhau, đối chiếu các bảng tính Excel khổng lồ, vẽ biểu đồ và định dạng báo cáo PDF/PowerPoint lặp đi lặp lại một cách thủ công cực kỳ tốn thời gian. Theo nghiên cứu năng suất văn phòng, nhân viên hành chính trung bình mất tới **10 giờ mỗi tháng** chỉ để xử lý các báo cáo định kỳ. Dù Excel là một công cụ phân tích cực kỳ mạnh mẽ, việc sử dụng nó theo cách thủ công luôn tiềm ẩn nhiều rủi ro. Chỉ cần một sai sót nhỏ trong việc copy-paste dữ liệu, gõ nhầm công thức hay chọn sai dải ô có thể làm sai lệch kết quả của toàn bộ báo cáo doanh nghiệp. Thực tế cho thấy, các quy trình thủ công này có tỷ lệ lỗi lên tới **5% đến 8%**, dẫn đến việc mất thời gian đối chiếu lại hoặc nguy hiểm hơn là đưa ra các quyết định kinh doanh sai lệch. Để giải quyết triệt để bài toán này, tự động hóa văn phòng bằng cách kết hợp VBA và Python đang trở thành xu hướng tất yếu. 2. Tại sao lại kết hợp Python và VBA? Sự kết hợp hoàn hảo VBA (Visual Basic for Applications) là ngôn ngữ lập trình tích hợp sẵn trong Microsoft Office từ hàng chục năm nay, rất mạnh mẽ trong việc tương tác trực tiếp với giao diện người dùng của Excel, tạo các nút nhấn (buttons) và thực thi các macro định dạng nhanh. Tuy nhiên, VBA bộc lộ điểm yếu lớn khi phải xử lý lượng dữ liệu khổng lồ (hơn 100,000 dòng) hoặc khi cần kết nối với cơ sở dữ liệu hiện đại, gọi API từ web và thực hiện các phân tích thống kê chuyên sâu. Trong khi đó, Python lại là ông vua của khoa học dữ liệu (Data Science) với hệ sinh thái thư viện cực kỳ phong phú như Pandas (xử lý bảng biểu), Openpyxl (đọc/ghi file Excel), và Matplotlib/Seaborn (vẽ biểu đồ chuyên nghiệp). Sự kết hợp giữa hai công cụ này mang lại sức mạnh vượt trội: VBA đảm nhận phần giao diện và định dạng: Tạo các nút bấm thân thiện trên bảng tính Excel để người dùng không biết lập trình cũng có thể nhấn kích hoạt script. Python đảm nhận phần cốt lõi xử lý dữ liệu: Quét thư mục, đọc hàng trăm file Excel đầu vào, làm sạch dữ liệu, tính toán thống kê và vẽ biểu đồ. Tốc độ xử lý của Python nhanh gấp **100 lần** so với việc dùng macro VBA chạy vòng lặp trên hàng trăm ngàn dòng dữ liệu. 3. Thiết lập luồng tự động hóa báo cáo trong 5 phút Một luồng tự động hóa báo cáo chuẩn hóa thường bao gồm 3 phân đoạn chính hoạt động liên tục: Bước 1: Sử dụng Python để cào dữ liệu và tổng hợp (Data Ingestion) Python sử dụng thư viện `Pandas` để quét toàn bộ các file Excel báo cáo chi tiết nằm trong thư mục làm việc. Đoạn mã Python chỉ tốn vài dòng để gộp toàn bộ dữ liệu này thành một DataFrame duy nhất: import pandas as pd import glob # Tìm tất cả file excel doanh thu tháng files = glob.glob('data/doanh_thu_*.xlsx') df_list = [pd.read_excel(f) for f in files] tong_hop = pd.concat(df_list, ignore_index=True) Sau đó, thư viện này tự động lọc bỏ các dòng trùng lặp, xử lý các giá trị bị thiếu (NaN) và thực hiện các phép gom nhóm (group by) để tính toán doanh thu tổng chỉ trong vài mili-giây, giúp triệt tiêu tỷ lệ lỗi thủ công về **0%**. Bước 2: Sử dụng VBA để kích hoạt và giao tiếp hệ thống Trong Excel, chúng ta thiết lập một Macro VBA đơn giản và gán nó vào một nút nhấn thân thiện trên giao diện. Khi người dùng nhấn nút này, VBA sẽ tự động gọi thực thi script Python ẩn dưới nền hệ thống bằng lệnh `Shell`: Sub ChayPythonScript() Dim objShell As Object Set objShell = CreateObject("Wscript.Shell") objShell.Run "python C:\scripts\bao_cao.py", 0, True MsgBox "Đã cập nhật dữ liệu báo cáo thành công!", vbInformation End Sub Bước 3: Xuất báo cáo PDF và gửi Email tự động Sau khi Python tính toán và cập nhật ngược lại vào file Excel mẫu, script có thể tự động chuyển đổi file này thành định dạng PDF chất lượng cao thông qua các thư viện như `ReportLab` hoặc kết nối API trực tiếp tới Outlook để soạn thảo và gửi báo cáo đính kèm tới hòm thư của quản lý. Toàn bộ chu trình này giúp tiết kiệm thời gian vận hành từ **10 giờ thực hiện thủ công xuống còn chưa đầy 5 phút**. 4. Những con số thực chứng về hiệu quả tự động hóa văn phòng Tự động hóa văn phòng mang lại những thay đổi đột phá về năng suất làm việc: Tăng tốc xử lý vượt trội: Giảm thời gian tổng hợp dữ liệu từ 2 ngày làm việc xuống còn **5 phút**. Giảm thiểu chi phí cơ hội: Giúp doanh nghiệp tiết kiệm trung bình **20 giờ làm việc mỗi nhân viên mỗi tháng**, tập trung nguồn lực vào các tác vụ mang lại giá trị cao hơn như phân tích chiến lược. Chuyển đổi kỹ năng nhân sự: Khảo sát cho thấy **75% nhà phân tích tài chính hiện đại** đang chủ động học Python để bổ trợ cho kỹ năng Excel truyền thống, tạo ra lợi thế cạnh tranh lớn trên thị trường tuyển dụng. Độ chính xác tuyệt đối: Giảm tỷ lệ sai sót số liệu kế toán và báo cáo quản trị từ 5% xuống **0%**. 5. Kết luận Làm chủ tự động hóa văn phòng nâng cao bằng cách kết hợp VBA và Python không chỉ là một mẹo công nghệ nhỏ, mà là sự thay đổi tư duy làm việc trong kỷ nguyên số. Hãy bắt đầu xây dựng những công cụ tự động hóa nhỏ ngay hôm nay để biến những giờ làm việc mệt mỏi cuối tháng thành một nút bấm 5 phút nhẹ nhàng và hiệu quả. Đừng làm việc chăm chỉ một cách thủ công, hãy làm việc thông minh bằng tự động hóa.

Đón Đầu Mật Mã Kháng Cấu Lượng Tử (Post-Quantum Cryptography): Apple, Google Đang Bảo Mật Dữ Liệu Người Dùng Thế Nào?
1. Mối đe dọa từ 'Ngày Y2Q': Khi siêu máy tính lượng tử phá vỡ mọi hàng rào bảo mật Toàn bộ hạ tầng an ninh mạng toàn cầu hiện nay—từ giao dịch ngân hàng, chữ ký số đến tin nhắn riêng tư—đang dựa trên các thuật toán mã hóa khóa công khai truyền thống như RSA, ECC (Elliptic Curve Cryptography) và Diffie-Hellman. Các thuật toán này hoạt động dựa trên các bài toán toán học phức tạp như phân tích thừa số nguyên tố lớn, thứ mà các siêu máy tính truyền thống phải mất hàng tỷ năm mới có thể giải được. Tuy nhiên, sự phát triển vượt bậc của máy tính lượng tử đang tạo ra một cơn địa chấn công nghệ thực sự. Sử dụng thuật toán Shor, một máy tính lượng tử đủ mạnh có thể bẻ gãy các khóa mã hóa RSA/ECC hiện tại chỉ trong vòng 1 đến 2 giờ đồng hồ. Mối đe dọa này đã khai sinh ra khái niệm 'Ngày Y2Q' (Year to Quantum)—thời điểm máy tính lượng tử đạt đủ quy mô để vô hiệu hóa các phương thức bảo mật truyền thống. Nguy hiểm hơn, các nhóm tin tặc tinh vi đang tiến hành chiến dịch 'Thu thập trước, giải mã sau' (Harvest Now, Decrypt Later - HNDL). Chúng âm thầm đánh cắp và lưu trữ hơn 90% lượng dữ liệu nhạy cảm được mã hóa của các chính phủ và tập đoàn lớn ngay từ bây giờ, chờ đợi đến khi máy tính lượng tử thương mại hóa để tiến hành giải mã hàng loạt. Điều này buộc ngành bảo mật phải nhanh chóng chuyển dịch sang một kỷ nguyên mới: **Mật mã kháng cấu lượng tử (Post-Quantum Cryptography - PQC)**. 2. Mật mã kháng cấu lượng tử (PQC) là gì? Mật mã kháng cấu lượng tử (PQC) là các thuật toán mã hóa mới được thiết kế để chạy trên máy tính truyền thống hiện tại nhưng có khả năng kháng cự lại các đợt tấn công từ cả máy tính truyền thống lẫn máy tính lượng tử trong tương lai. Thay vì dựa trên các bài toán số học dễ bị máy tính lượng tử bẻ gãy, PQC sử dụng các cấu trúc toán học đa chiều vô cùng phức tạp, tiêu biểu nhất là toán học mạng lưới (Lattice-based cryptography). Để chuẩn hóa làn sóng chuyển dịch này, Viện Tiêu chuẩn và Công nghệ Quốc gia Mỹ (NIST) đã trải qua quá trình đánh giá khắt khe kéo dài gần một thập kỷ và chính thức công bố **3 tiêu chuẩn mã hóa kháng lượng tử đầu tiên** vào tháng 8 năm 2024 (bao gồm ML-KEM cho trao đổi khóa, ML-DSA và FN-DSA cho chữ ký số). Đây được coi là phát súng mở màn cho chiến dịch nâng cấp hạ tầng mật mã lớn nhất lịch sử nhân loại, dự kiến sẽ kéo dài liên tục từ **10 đến 15 năm** tiếp theo. 3. Các ông lớn Apple và Google đang đi tiên phong như thế nào? Nhận thức được mức độ nghiêm trọng của mối đe dọa lượng tử, hai gã khổng lồ công nghệ Apple và Google đã chủ động tích hợp các giao thức bảo mật thế hệ mới vào sản phẩm cốt lõi của họ để bảo vệ hàng tỷ người dùng trên toàn thế giới. Apple và Giao thức bảo mật PQ3 trên iMessage Vào đầu năm 2024, Apple gây chú ý lớn khi công bố tích hợp **giao thức mật mã kháng lượng tử PQ3** vào ứng dụng nhắn tin iMessage. Đây là bước nhảy vọt đưa bảo mật iMessage lên Cấp độ 3 (Level 3 Security)—cấp độ bảo mật tin nhắn thương mại cao nhất thế giới hiện nay. PQ3 hoạt động bằng cách kết hợp mật mã kháng lượng tử (sử dụng thuật toán ML-KEM) với mật mã ECC truyền thống: PQ3 tự động thiết lập lại khóa mã hóa mới định kỳ trong suốt cuộc hội thoại. Giao thức này bảo vệ hơn **1 tỷ người dùng** iMessage toàn cầu khỏi các cuộc tấn công HNDL bằng cách đảm bảo rằng ngay cả khi tin tặc lấy được một khóa trong tương lai, chúng cũng không thể giải mã các tin nhắn cũ hoặc tin nhắn mới sau đó. Google và Chiến dịch triển khai PQC trên Chrome và Android Google cũng không hề kém cạnh khi bắt đầu triển khai cơ chế trao đổi khóa lai kháng lượng tử (Hybrid PQC key exchange) trong trình duyệt Google Chrome từ phiên bản **124**. Cơ chế này kết hợp X25519 (ECC truyền thống) và Kyber-768 (chuẩn ML-KEM của NIST): Bảo mật hàng trăm triệu kết nối TLS khi người dùng truy cập các dịch vụ của Google như Gmail, Search và YouTube. Mới đây, Google cũng công bố tích hợp API hỗ trợ các thuật toán PQC vào hệ điều hành Android và các hệ thống máy chủ đám mây Google Cloud, đặt nền móng vững chắc cho hệ sinh thái di động kháng lượng tử hoàn chỉnh. 4. Thách thức lớn đối với doanh nghiệp khi chuyển đổi sang PQC Dù việc chuyển đổi sang PQC là tất yếu, các doanh nghiệp và tổ chức sẽ phải đối mặt với nhiều thách thức kỹ thuật không hề nhỏ: Kích thước khóa lớn hơn: Các thuật toán PQC đòi hỏi kích thước khóa (key size) và chữ ký số lớn hơn gấp hàng chục đến hàng trăm lần so với RSA/ECC. Điều này gây áp lực lớn lên băng thông mạng và dung lượng lưu trữ của hệ thống. Tác động đến hiệu năng: Việc xử lý các phép toán mạng lưới đa chiều đòi hỏi năng lực CPU cao hơn, có thể làm tăng độ trễ kết nối ban đầu (handshake latency) của các giao dịch trực tuyến. Độ phức tạp của hệ thống legacy: Nhiều thiết bị phần cứng cũ, chứng thư số cũ và hệ thống nhúng IoT không đủ bộ nhớ hoặc năng lực tính toán để chạy các thuật toán PQC mới, đòi hỏi chi phí thay thế thiết bị vô cùng đắt đỏ. 5. Lời kết Cuộc đua mật mã lượng tử không còn là câu chuyện lý thuyết của tương lai. Việc Apple và Google nhanh chóng phủ sóng các chuẩn bảo mật PQC đến hàng tỷ thiết bị là minh chứng rõ ràng cho thấy kỷ nguyên hậu lượng tử đã bắt đầu gõ cửa. Doanh nghiệp cần chủ động kiểm kê tài sản mật mã (cryptographic inventory) và xây dựng lộ trình chuyển dịch PQC ngay từ bây giờ để đảm bảo dữ liệu quan trọng không bị phơi bày trước sức mạnh của kỷ nguyên máy tính mới. Đừng đợi đến khi máy tính lượng tử xuất hiện mới tìm cách bảo mật. Hãy bảo vệ dữ liệu của bạn trước mối đe dọa lượng tử ngay hôm nay.

Chuyển Dịch Sang WebAssembly (Wasm) Cho Phần Mềm Doanh Nghiệp: Đưa Ứng Dụng Legacy Lên Web Với Hiệu Năng Native
1. Cơn đau đầu của phần mềm doanh nghiệp: Legacy vs. Cloud-Native Trong hơn một thập kỷ qua, cuộc dịch chuyển lên đám mây (Cloud Migration) đã thúc đẩy các doanh nghiệp chuyển đổi ứng dụng của họ từ dạng desktop truyền thống sang mô hình Web và SaaS. Tuy nhiên, đối với các hệ thống phần mềm doanh nghiệp lớn (như CAD/CAM, công cụ xử lý đồ họa, hệ thống tài chính thời gian thực hoặc phần mềm phân tích dữ liệu lớn), việc đưa lên môi trường trình duyệt web luôn là một bài toán hóc búa. Các hệ thống legacy này thường được viết bằng C, C++, hoặc Rust để tận dụng tối đa sức mạnh phần cứng cục bộ. Khi chuyển dịch lên web, việc viết lại toàn bộ mã nguồn khổng lồ bằng JavaScript hay TypeScript là điều không khả thi về cả chi phí và thời gian. Hơn thế nữa, hiệu năng của JavaScript từ trước đến nay bị giới hạn bởi cơ chế thông dịch (interpreted language) và garbage collection. Khảo sát từ các kỹ sư hệ thống năm 2025 cho thấy, có tới 65% doanh nghiệp gặp khó khăn khi cố gắng giả lập các tính năng tính toán nặng trên trình duyệt, dẫn đến việc ứng dụng bị giật lag, tốn bộ nhớ và mang lại trải nghiệm người dùng kém cỏi. Đây chính là lý do công nghệ WebAssembly (Wasm) ra đời và nhanh chóng trở thành cứu cách cho các nhà phát triển phần mềm doanh nghiệp. 2. WebAssembly (Wasm) là gì? Tiêu chuẩn vàng mới của ứng dụng Web hiệu năng cao WebAssembly (viết tắt là Wasm) là một định dạng mã nhị phân cấp thấp (low-level binary format) được thiết kế đặc biệt để chạy mã nguồn biên dịch với hiệu năng cực cao trên trình duyệt web. Wasm hoạt động như một máy ảo ảo hóa an toàn (sandboxed execution environment) chạy song song với JavaScript trong trình duyệt. Thay vì thay thế JavaScript, Wasm bổ trợ cho nó. Lập trình viên có thể giữ nguyên mã nguồn C, C++, Rust hoặc Go của các phần mềm doanh nghiệp legacy, sau đó biên dịch trực tiếp sang Wasm. Trình duyệt web sẽ tải mã nhị phân này và thực thi nó với tốc độ tiệm cận với tốc độ chạy trực tiếp trên hệ điều hành (native speed). Sự xuất hiện của Wasm đã xóa nhòa ranh giới giữa ứng dụng desktop và ứng dụng web, mở ra kỷ nguyên mới của các phần mềm SaaS siêu nặng chạy mượt mà trên trình duyệt. 3. Những lợi ích cốt lõi khi doanh nghiệp áp dụng WebAssembly Việc chuyển dịch sang WebAssembly không chỉ đơn thuần là giải pháp kỹ thuật, mà nó mang lại những lợi ích kinh doanh vô cùng thực tế: Đưa ứng dụng Legacy lên Web mà không cần viết lại mã nguồn: Doanh nghiệp có thể tận dụng hàng triệu dòng code C/C++/Rust đã được kiểm chứng qua hàng chục năm để đưa lên web chỉ bằng cách thay đổi cấu hình biên dịch. Điều này giúp giảm thiểu rủi ro lỗi và rút ngắn 70% thời gian đưa sản phẩm ra thị trường (Time-to-Market). Hiệu năng native vượt trội: Thực nghiệm chứng minh Wasm đạt hiệu năng tính toán nhanh gấp 1.5 đến 2 lần so với JavaScript tối ưu tốt nhất, giúp xử lý mượt mà các file 3D, thiết kế CAD hoặc các thuật toán phân tích số phức tạp. Tiết kiệm tài nguyên và bộ nhớ: Wasm không cần cơ chế dọn rác (garbage collection) liên tục của JavaScript, giúp giảm mức tiêu thụ bộ nhớ RAM của ứng dụng trên máy khách lên tới 60%. Điển hình như Figma và Adobe đã tối ưu hóa thành công trải nghiệm thiết kế mượt mà của họ nhờ Wasm. Khởi động cực nhanh (Cold-start reduction): Trong môi trường máy chủ (Serverless/Edge computing), các module Wasm có kích thước siêu nhỏ giúp giảm thời gian khởi động nguội (cold-start times) đến 99%, chỉ mất chưa đầy 1ms để phản hồi yêu cầu của người dùng, so với mức trung bình 100ms - 200ms của container truyền thống. Bảo mật tối đa nhờ cơ chế Sandbox: Wasm chạy trong môi trường cô lập nghiêm ngặt của trình duyệt, ngăn chặn hoàn toàn việc truy cập trái phép vào bộ nhớ hệ thống hoặc các tài nguyên phần cứng nhạy cảm của người dùng. 4. Các bước chuyển dịch ứng dụng Legacy sang WebAssembly thành công Để triển khai thành công dự án WebAssembly cho doanh nghiệp, các nhóm kỹ sư cần tuân thủ quy trình chuẩn hóa gồm 4 bước: Bước 1: Phân tích kiến trúc và khoanh vùng module nặng. Không phải mọi thứ đều nên chuyển sang Wasm. Lập trình viên cần định vị chính xác các luồng tính toán nặng, các thư viện cốt lõi xử lý thuật toán để biên dịch sang Wasm, trong khi giữ lại phần giao diện (UI/UX) bằng React hoặc Vue để dễ dàng cập nhật. Bước 2: Chuẩn bị mã nguồn và thiết lập chuỗi công cụ biên dịch (Emscripten / Rust toolchain). Đối với mã nguồn C/C++, Emscripten là chuỗi công cụ phổ biến nhất giúp dịch mã và tạo ra các file liên kết JS. Đối với Rust, `wasm-pack` là lựa chọn tối ưu cung cấp sự tích hợp mượt mà vào hệ sinh thái npm. Bước 3: Tối ưu hóa kích thước file và quản lý bộ nhớ. Do mã nhị phân phải tải qua mạng internet, việc tối ưu kích thước file Wasm là cực kỳ quan trọng. Sử dụng các cờ tối ưu hóa biên dịch (như `-Oz`) có thể giảm dung lượng file xuống 50%. Ngoài ra, việc quản lý chia sẻ bộ nhớ (Shared Memory) giữa JavaScript và Wasm cần được thiết kế cẩn thận để tránh rò rỉ dữ liệu. Bước 4: Kiểm thử hiệu năng và triển khai thực tế. Tiến hành kiểm thử so sánh hiệu năng trực tiếp trên nhiều cấu hình thiết bị khác nhau của người dùng để đảm bảo tính ổn định tối đa. 5. Kết luận Theo báo cáo khảo sát công nghệ doanh nghiệp năm 2026, dự kiến có hơn 70% các công ty SaaS lớn sẽ tích hợp WebAssembly vào nhân lõi ứng dụng của họ trong vòng 18 tháng tới. Chuyển dịch sang WebAssembly không còn là một lựa chọn thử nghiệm, mà đã trở thành chiến lược sống còn để nâng cấp các phần mềm doanh nghiệp legacy lên đám mây, giúp tối ưu hóa hiệu năng native, cắt giảm chi phí phát triển và mang lại trải nghiệm người dùng đẳng cấp thế giới. WebAssembly là tương lai của ứng dụng web hiệu năng cao. Doanh nghiệp nào làm chủ Wasm trước sẽ chiếm lĩnh ưu thế tuyệt đối trong cuộc đua chuyển đổi số.
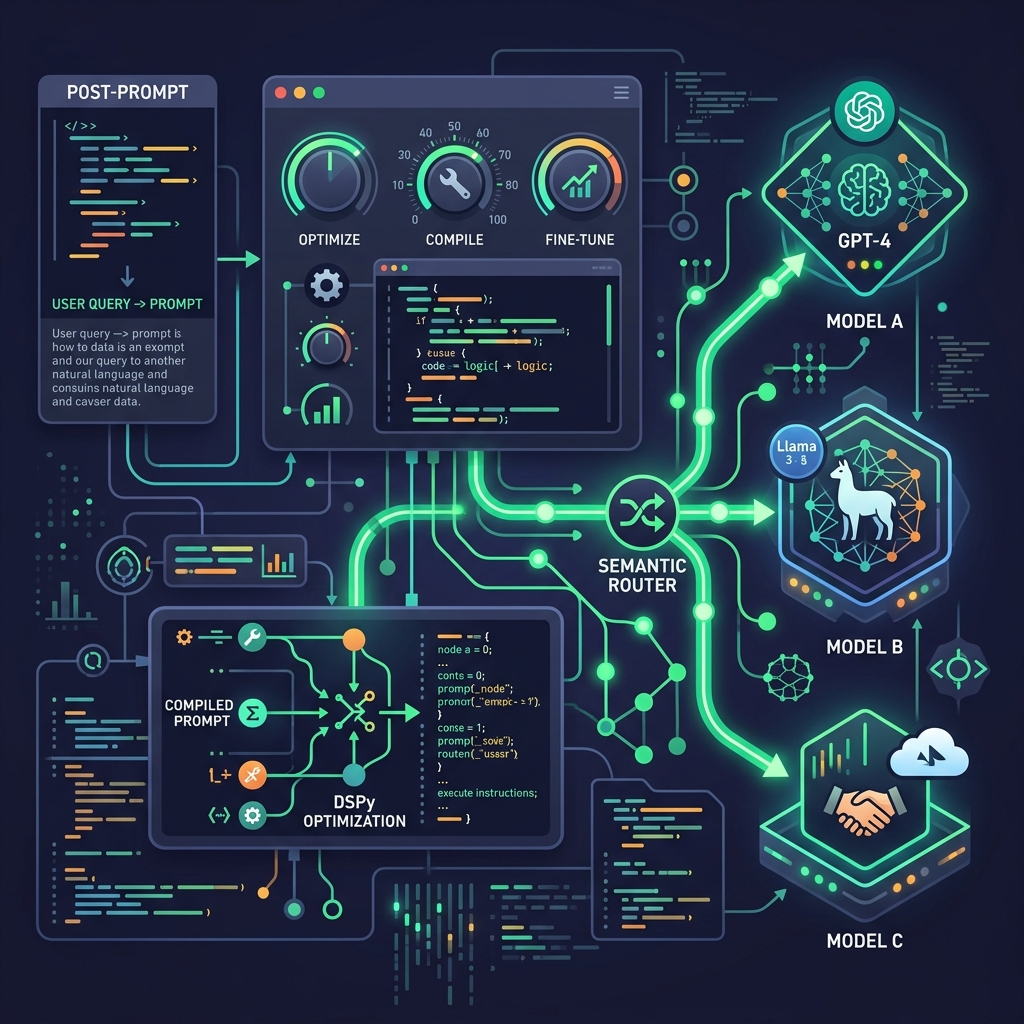
Kỷ Nguyên Post-Prompting: Xây Dựng Hệ Thống AI Tự Định Cấu Hình Thông Qua DSPy Và Semantic Router
1. Sự mong manh của Prompt Engineering thủ công: Rào cản lớn nhất của AI doanh nghiệp Trong giai đoạn đầu bùng nổ của AI tạo sinh (2023 - 2025), khái niệm 'Prompt Engineering' (Kỹ nghệ viết câu lệnh) đã được ca ngợi như một kỹ năng hot nhất, mở ra cánh cửa giao tiếp với các mô hình ngôn ngữ lớn (LLM). Hàng ngàn kỹ sư đã dành hàng giờ để mày mò, thử sai (trial-and-error) từng từ, từng dấu phẩy để ép LLM đưa ra kết quả mong muốn. Tuy nhiên, khi các doanh nghiệp bắt đầu đưa AI vào môi trường sản xuất thực tế (production) trên quy mô lớn, họ nhanh chóng nhận ra một sự thật phũ phàng: Prompt viết tay thủ công cực kỳ mong manh và thiếu ổn định. Khảo sát các kỹ sư phần mềm năm 2026 cho thấy, khoảng 80% thời gian phát triển ứng dụng AI đang bị lãng phí vào việc thử sai viết prompt. Chỉ cần một thay đổi nhỏ về từ ngữ, hoặc nghiêm trọng hơn là khi doanh nghiệp nâng cấp/chuyển đổi mô hình LLM nền tảng (ví dụ từ GPT-4 sang Gemini 1.5), hiệu năng của toàn bộ hệ thống sử dụng prompt viết tay có thể bị sụt giảm nghiêm trọng lên tới 40%. Mã nguồn phần mềm truyền thống đòi hỏi tính nhất quán và có thể kiểm thử (testable), trong khi prompt viết tay lại mang tính cảm tính, mơ hồ và không thể đo lường. Điều này tạo ra rào cản khổng lồ ngăn chặn việc xây dựng các ứng dụng doanh nghiệp đáng tin cậy. 2. Bước vào Kỷ nguyên Post-Prompting: Khái niệm và Triết lý mới Để giải quyết triệt để sự mong manh của prompt thủ công, thế giới công nghệ năm 2026 đang chứng kiến sự chuyển dịch mang tính lịch sử sang **Kỷ nguyên Post-Prompting** (Hậu Prompt). Triết lý cốt lõi của kỷ nguyên này là: Lập trình viên không nên tự tay viết prompt nữa. Thay vào đó, prompt sẽ được coi là các tham số hệ thống cần được tối ưu hóa bằng lập trình và thuật toán tự động. Thay vì viết các chuỗi ký tự hướng dẫn dài dòng, lập trình viên định nghĩa các luồng xử lý dữ liệu (pipelines) dưới dạng các module lập trình sạch sẽ. Hệ thống sẽ tự động tìm ra prompt tối ưu nhất, tự sinh các ví dụ mẫu (few-shot examples) chất lượng cao dựa trên tập dữ liệu kiểm thử và mục tiêu đầu ra được chỉ định trước. Hai công nghệ mũi nhọn đại diện cho cuộc cách mạng này chính là framework **DSPy của đại học Stanford** và giải pháp định tuyến ngữ nghĩa **Semantic Router**. 3. Stanford DSPy: Biên dịch và tối ưu hóa Prompt tự động bằng mã lập trình DSPy (Declarative Self-improving Language Programs) là framework nguồn mở mang tính đột phá được phát triển bởi nhóm nghiên cứu NLP của Đại học Stanford. DSPy tách biệt hoàn toàn cấu trúc logic của chương trình (Program Architecture) ra khỏi cấu hình chi tiết của prompt (Prompt/Few-shot settings). Cách thức hoạt động của DSPy: Định nghĩa Signature (Chữ ký): Lập trình viên chỉ cần mô tả đầu vào và đầu ra dưới dạng code (ví dụ: `input: tài liệu kỹ thuật -> output: mã code tối ưu`). Trình tối ưu hóa tự động (Teleprompter/Optimizer): DSPy sẽ tự động chạy thử nghiệm trên tập dữ liệu huấn luyện của bạn, thử nghiệm hàng chục biến thể prompt khác nhau, tự động lọc và chèn các ví dụ few-shot hiệu quả nhất. Biên dịch chéo mô hình (Cross-model Compilation): Khi bạn muốn chuyển đổi từ mô hình lớn đắt đỏ như GPT-4 sang mô hình nhỏ nội bộ như Llama-3-8B, bạn chỉ cần bấm nút 'Compile' (biên dịch). DSPy sẽ tự động tối ưu lại bộ prompt dành riêng cho Llama-3. Kết quả thực nghiệm chứng minh, mô hình nhỏ 8B được tối ưu bằng DSPy có khả năng đạt hiệu suất tương đương 95% so với mô hình lớn chạy prompt thủ công, giúp nâng cao độ chính xác của hệ thống thêm 30% đến 45%. 4. Semantic Router: Bộ định tuyến ngữ nghĩa siêu tốc triệt tiêu độ trễ Song song với việc tối ưu hóa nội dung prompt của DSPy, bài toán định tuyến yêu cầu (query routing) cũng được cách mạng hóa bằng **Semantic Router** (Bộ định tuyến ngữ nghĩa). Trong các hệ thống cũ, để phân biệt xem người dùng muốn 'mua hàng' hay 'hỏi đáp kỹ thuật', lập trình viên phải gọi một LLM lớn để phân tích intent (ý định), gây ra độ trễ hàng giây và tiêu tốn chi phí API không cần thiết. Semantic Router giải quyết bài toán này bằng cách sử dụng các mô hình nhúng vector (embedding models) siêu nhỏ và thuật toán so khớp độ tương đồng ngữ nghĩa cục bộ: Định tuyến siêu tốc dưới 10ms - 20ms: Thay vì gửi request lên đám mây, Semantic Router phân tích vector ngữ nghĩa của câu hỏi ngay trên máy chủ cục bộ chỉ trong vòng chưa đầy 10ms - 20ms (nhanh hơn gấp 100 lần so với dùng LLM), ngay lập tức chuyển hướng câu hỏi đến đúng module xử lý chuyên biệt. Tiết kiệm 60% chi phí API: Bằng cách định tuyến chính xác các câu hỏi đơn giản về cho các mô hình nhỏ (SLM) nội bộ xử lý và chỉ chuyển các câu hỏi thực sự phức tạp lên mô hình đám mây, doanh nghiệp tiết kiệm được phần lớn ngân sách vận hành hệ thống AI. 5. Lời kết: Tương lai của phát triển ứng dụng AI bền vững và có thể mở rộng Kỷ nguyên Post-Prompting đánh dấu sự trưởng thành của ngành kỹ nghệ AI, chuyển dịch từ một bộ môn nghệ thuật 'thử sai' cảm tính sang một ngành khoa học kỹ thuật lập trình chính xác, có thể đo lường và tối ưu hóa tự động. Bằng việc tích hợp các công cụ mạnh mẽ như DSPy và Semantic Router vào kiến trúc hệ thống, các doanh nghiệp và nhà phát triển phần mềm không chỉ giải quyết triệt để bài toán độ trễ và chi phí vận hành, mà quan trọng hơn là xây dựng được những ứng dụng AI có tính ổn định cao, sẵn sàng mở rộng quy mô phục vụ hàng triệu người dùng trong tương lai số. Đã đến lúc ngừng viết prompt thủ công và bắt đầu biên dịch chương trình AI của bạn. Hãy đón đầu kỷ nguyên Post-Prompting ngay hôm nay!

Làm Chủ Giao Tiếp Công Nghệ Bằng Tiếng Anh: Kỹ Thuật Học Nhanh Từ Vựng Chuyên Ngành AI Và An Ninh Mạng
1. Khoảng cách tri thức và sự bùng nổ tài liệu kỹ thuật tiếng Anh Trong thế giới công nghệ thay đổi từng ngày, tốc độ cập nhật thông tin chính là yếu tố quyết định sự thành bại của một lập trình viên. Các mô hình ngôn ngữ lớn (LLM) mới, các công cụ sinh ảnh AI, hay các kỹ thuật tấn công mạng Zero-day nguy hiểm luôn được công bố liên tục trên các diễn đàn quốc tế lớn. Tuy nhiên, có một thực tế khắt khe: hơn 95% các tài liệu học thuật, nghiên cứu khoa học chuyên sâu và tài liệu kỹ thuật (documentation) về AI và An ninh mạng được viết bằng tiếng Anh đầu tiên. Việc ngồi chờ đợi các bản dịch sang tiếng Việt sẽ tạo ra một khoảng cách tri thức vô cùng lớn. Kỹ sư nào tiếp cận được tài liệu gốc sớm hơn sẽ chiếm ưu thế vượt trội. Khảo sát từ GitHub chỉ ra rằng những lập trình viên có khả năng đọc hiểu và giao tiếp tiếng Anh chuyên ngành tốt có tốc độ giải quyết sự cố kỹ thuật nhanh hơn 50% nhờ khả năng chủ động tìm kiếm giải pháp trên stackoverflow hoặc github issues toàn cầu. Ngược lại, việc hạn chế về ngoại ngữ sẽ giam hãm lập trình viên trong những dự án nội địa với mức lương khiêm tốn. Thống kê thị trường nhân sự công nghệ năm 2026 cho thấy mức lương trung bình của kỹ sư phần mềm Việt Nam giao tiếp tốt bằng tiếng Anh cao hơn 60% so với đồng nghiệp có cùng trình độ chuyên môn kỹ thuật nhưng yếu ngoại ngữ. Nhu cầu về nhân lực chất lượng cao biết tiếng Anh chuyên ngành công nghệ (ESP) hiện đang tăng vọt gấp 3 lần tại các doanh nghiệp bán dẫn và phát triển AI. 2. Kỹ thuật lặp lại ngắt quãng (Spaced Repetition) tích hợp AI Một trong những rào cản lớn nhất khi học tiếng Anh chuyên ngành AI và An ninh mạng là khối lượng thuật ngữ viết tắt và từ vựng kỹ thuật vô cùng đồ sộ. Học sinh thường cố gắng học vẹt nhưng sẽ quên sạch chỉ sau vài ngày. Để giải quyết bài toán này, phương pháp tối ưu nhất là sử dụng kỹ thuật Lặp lại ngắt quãng (Spaced Repetition) kết hợp cùng Trợ lý AI. Spaced Repetition là phương pháp học tập dựa trên việc ôn tập lại từ vựng theo các khoảng thời gian tăng dần (ví dụ: 1 ngày, 3 ngày, 7 ngày, 30 ngày) để chuyển thông tin từ bộ nhớ ngắn hạn sang bộ nhớ dài hạn. Nghiên cứu thực nghiệm chứng minh phương pháp này giúp nâng hiệu quả ghi nhớ từ vựng lên đến 80% so với cách học truyền thống. Cách thức ứng dụng AI để tạo flashcard thông minh: Tự động sinh ngữ cảnh thực tế: Bạn có thể sao chép một đoạn tài liệu kỹ thuật chứa từ vựng mới và yêu cầu AI: 'Hãy tạo flashcard dạng câu hỏi cho các từ vựng chuyên ngành trong đoạn văn này, giải thích nghĩa và đưa ra ví dụ thực tế trong code'. Luyện tập qua thẻ thông minh (Anki): Import các flashcard này vào ứng dụng Anki. Thuật toán của ứng dụng sẽ tự động tính toán thời gian hiển thị lại các từ vựng khó để bộ não của bạn ghi nhớ sâu sắc nhất. 3. Học qua ngữ cảnh thực tế: Giả lập cuộc họp kỹ thuật quốc tế cùng AI Đọc hiểu từ vựng mới chỉ là một nửa chặng đường. Để thực sự làm chủ ngôn ngữ, bạn phải có khả năng sử dụng các thuật ngữ đó trong giao tiếp thực tế như thảo luận nhóm, thuyết trình dự án hoặc tham gia các cuộc họp giải quyết sự cố hệ thống (Incident Review Meetings). Trợ lý AI năm 2026 chính là người bạn đồng hành giả lập tuyệt vời nhất. Bạn có thể thiết lập các kịch bản đóng vai (roleplay) chuyên sâu để AI giao tiếp cùng bạn: 'Bạn là một chuyên gia an ninh mạng quốc tế (CISO). Hệ thống của chúng ta vừa bị tấn công ransomware. Hãy bắt đầu một cuộc họp khẩn cấp để cùng thảo luận cách xử lý sự cố này bằng tiếng Anh chuyên ngành.' Thông qua việc đối thoại trực tiếp thời gian thực, AI sẽ giúp bạn thực hành cách sử dụng các cụm từ chuyên môn, sửa lỗi ngữ pháp và tăng tính phản xạ giao tiếp tự nhiên. Hơn nữa, việc hiểu sâu tiếng Anh kỹ thuật còn giúp giảm thiểu rủi ro bảo mật cho doanh nghiệp, khi khoảng 70% các vụ tấn công lừa đảo phishing tinh vi nhắm vào giới lập trình đều sử dụng các email viết bằng tiếng Anh kỹ thuật giả mạo tinh xảo để lừa lấy token hoặc SSH key. 4. Danh sách các thuật ngữ cốt lõi chuyên ngành AI và An ninh mạng cần biết Để bắt đầu xây dựng vốn từ vựng của mình, dưới đây là danh sách các thuật ngữ cốt lõi mà mọi lập trình viên thời đại mới cần làm quen: AI & Machine Learning: Fine-tuning: Tinh chỉnh mô hình (huấn luyện bổ sung một mô hình đã có sẵn với tập dữ liệu nhỏ hơn để phục vụ tác vụ chuyên biệt). Quantization: Lượng tử hóa (kỹ thuật nén mô hình AI để chạy mượt mà trên phần cứng giới hạn). Semantic Search: Tìm kiếm ngữ nghĩa (tìm kiếm dựa trên ý nghĩa của từ thay vì so khớp từ khóa chính xác). Cybersecurity (An ninh mạng): Ransomware: Mã độc tống tiền (loại phần mềm độc hại mã hóa dữ liệu nạn nhân để đòi tiền chuộc). Immutable Backup: Bản sao lưu bất biến (dữ liệu sao lưu không thể bị xóa hoặc sửa đổi, chống lại ransomware). Lateral Movement: Di chuyển ngang (kỹ thuật tin tặc dùng để di chuyển sâu hơn vào bên trong mạng hệ thống sau khi đã chiếm được quyền truy cập ban đầu). 5. Lời kết: Ngôn ngữ là chìa khóa mở cánh cửa sự nghiệp công nghệ toàn cầu Làm chủ tiếng Anh chuyên ngành AI và An ninh mạng không còn là một kỹ năng phụ trợ tùy chọn, mà đã trở thành tấm vé quyết định giúp lập trình viên bước ra thế giới, tiếp cận nguồn tri thức nhân loại sớm nhất và kiến tạo những giá trị to lớn cho sự nghiệp. Bằng việc kết hợp thông minh giữa kỹ thuật lặp lại ngắt quãng và khả năng tương tác hội thoại giả lập của trợ lý AI, hành trình làm chủ ngoại ngữ của bạn sẽ trở nên ngắn hơn và tràn đầy hứng khởi. Hãy bắt đầu học và thực hành ngay hôm nay để sẵn sàng nắm bắt những cơ hội toàn cầu rộng mở! Ngôn ngữ của bạn là giới hạn cho thế giới của bạn. Hãy mở rộng biên giới đó bằng cách làm chủ tiếng Anh công nghệ ngay hôm nay!

Quản Trị Danh Tính Phi Nhân Học (Non-Human Identity): Xu Hướng Bảo Mật Nóng Nhất Năm 2026
1. Định nghĩa Non-Human Identity (NHI): Ranh giới bảo mật mới của doanh nghiệp Trong suốt nhiều năm qua, cuộc chiến an ninh mạng của các tổ chức doanh nghiệp chủ yếu tập trung xoay quanh việc bảo vệ tài khoản của con người (Human Identities). Các giải pháp như xác thực đa yếu tố (MFA), quản trị quyền truy cập đặc quyền (PAM) hay Single Sign-On (SSO) được thiết kế tinh vi để bảo đảm không một nhân sự nào bị đánh cắp thông tin đăng nhập. Tuy nhiên, bước sang năm 2026, khi các doanh nghiệp chuyển dịch mạnh mẽ lên môi trường điện toán đám mây và tích hợp sâu sắc các công cụ tự động hóa, một lỗ hổng khổng lồ đã xuất hiện: Danh tính phi nhân học (Non-Human Identity - NHI). Danh tính phi nhân học là các thông tin xác thực được sử dụng bởi các tác nhân phần mềm để giao tiếp tự động giữa máy với máy (Machine-to-Machine - M2M). Chúng bao gồm: API Keys, Service Accounts, OAuth Tokens, SSH Keys, SSL Certificates và các mật mã bảo mật (Secrets) kết nối cơ sở dữ liệu. Theo báo cáo an ninh mạng mới nhất, số lượng NHI trong một doanh nghiệp trung bình đã bùng nổ vượt trội, đạt tỷ lệ kinh ngạc là 45:1 (tức là có đến 45 danh tính máy cho mỗi 1 tài khoản người dùng là con người). Sự phát triển âm thầm nhưng thần tốc này đã đưa quản trị NHI trở thành xu hướng bảo mật nóng nhất và cấp bách nhất của năm 2026. 2. Tại sao Danh tính phi nhân học trở thành gót chân Achilles của bảo mật 2026? Khác với tài khoản của con người vốn được giám sát chặt chẽ và dễ dàng áp dụng các biện pháp bảo mật nâng cao, danh tính phi nhân học mang trong mình những đặc điểm cực kỳ lỏng lẻo khiến chúng trở thành miếng mồi ngon cho tin tặc: Không thể áp dụng xác thực đa yếu tố (MFA): Một đoạn code tự động hoặc một microservice không thể nhận mã OTP qua tin nhắn điện thoại hay quét vân tay. Do đó, các NHI chỉ dựa vào một lớp khóa tĩnh duy nhất (như API key). Nếu khóa này bị rò rỉ, tin tặc sẽ lập tức có toàn quyền truy cập mà không gặp bất kỳ rào cản nào. Vấn đề thừa quyền hạn (Over-privileged): Nhằm tiết kiệm thời gian cấu hình, nhiều kỹ sư phát triển phần mềm thường cấp quyền quản trị tối cao (Admin rights) cho các tài khoản dịch vụ, tạo ra nguy cơ phá hủy hệ thống cực lớn nếu tài khoản đó bị chiếm quyền. Bị bỏ quên và thiếu kiểm soát: Con người khi nghỉ việc sẽ bị khóa tài khoản ngay lập tức. Tuy nhiên, các API key hay Service Account được tạo ra cho các dự án cũ thường bị bỏ quên vĩnh viễn trong hệ thống (Ghost Identities) nhưng vẫn duy trì kết nối hoạt động âm thầm. 3. Hiểm họa khôn lường từ sự mất kiểm soát Machine Credentials Tác hại của việc lộ lọt danh tính phi nhân học là vô cùng khủng khiếp. Báo cáo khảo sát toàn cầu của CyberArk ghi nhận: hơn 75% các vụ rò rỉ dữ liệu thành công tại các tập đoàn lớn năm qua đều xuất phát từ việc khai thác các thông tin xác thực của danh tính máy. Nghiên cứu của hãng bảo mật GitGuardian chỉ ra rằng hơn 90% các khóa bảo mật rò rỉ được phát hiện là do lập trình viên vô tình ghi thẳng (hardcoded) mã khóa vào các file cấu hình và đẩy lên các kho lưu trữ mã nguồn mở công khai như GitHub. Gartner dự báo đến hết năm 2026, 85% các cuộc tấn công mạng dựa trên AI sẽ tập trung khai thác các NHI không được quản lý hoặc cấu hình sai để xâm nhập sâu vào chuỗi cung ứng phần mềm (Software Supply Chain). Thiệt hại toàn cầu do mất mát và khai thác danh tính máy dự kiến sẽ đạt mức kỷ lục là 10 nghìn tỷ USD vào cuối năm nay, biến đây trở thành mối đe dọa tài chính lớn nhất đối với các doanh nghiệp số. 4. Chiến lược 3 bước xây dựng Hệ thống quản trị NHI an toàn chủ động Để bảo vệ hệ thống trước làn sóng tấn công nhắm vào danh tính máy, doanh nghiệp cần khẩn trương triển khai chiến lược quản trị NHI toàn diện gồm ba trụ cột hành động: Bước 1: Quét và Lập bản đồ danh tính (Discovery & Mapping): Sử dụng các công cụ quét tự động để liệt kê toàn bộ các Service Account, API Key đang tồn tại trong mã nguồn và môi trường đám mây. Doanh nghiệp cần hiểu rõ từng danh tính máy do ai tạo ra, kết nối đến dịch vụ nào và có quyền hạn gì. Bước 2: Quản trị vòng đời khóa tự động (Secrets Management): Loại bỏ hoàn toàn việc ghi cứng mật mã vào code. Tích hợp các công cụ quản lý khóa tập trung (như HashiCorp Vault, AWS Secrets Manager) và thiết lập cơ chế tự động xoay vòng khóa (API key rotation) định kỳ 30 ngày để giảm thiểu thiệt hại nếu khóa bị rò rỉ. Bước 3: Giám sát hành vi thời gian thực (Behavioral Monitoring): Thiết lập hệ thống AI để theo dõi hành vi của các tài khoản máy. Nếu một API key thông thường chỉ gọi 100 requests/phút từ địa chỉ IP tại Việt Nam bỗng nhiên gọi 10.000 requests/phút từ một IP lạ tại Đông Âu, hệ thống phải tự động khóa quyền truy cập ngay lập tức. Việc áp dụng quản trị NHI chủ động giúp giảm đến 80% thời gian phát hiện và xử lý sự cố lộ lọt khóa. 5. Lời kết: Bảo vệ những 'nhân sự số' để bảo vệ tương lai doanh nghiệp Cuộc cách mạng tự động hóa đang tạo ra hàng triệu 'nhân sự số' (các đoạn code, bots, integrations) làm việc lặng lẽ trong hệ thống của chúng ta. Quyền hạn của những thực thể phi nhân học này đang ngày một lớn hơn và trở thành mục tiêu săn đuổi hàng đầu của tin tặc. Nhận thức đúng đắn và đầu tư bài bản vào quy trình Quản trị danh tính phi nhân học (NHI Management) không chỉ giúp loại bỏ những điểm mù nguy hiểm nhất trong kiến trúc bảo mật đám mây, mà còn là bệ đỡ vững chắc giúp doanh nghiệp tự tin tăng tốc trên con đường chuyển đổi số bền vững. Hệ thống bảo mật chỉ mạnh bằng mắt xích yếu nhất. Đừng để một chiếc API key bị bỏ quên phá hủy toàn bộ thành trì dữ liệu của doanh nghiệp bạn!

Sự Bùng Nổ Của Mô Hình Hybrid-LLM Và AI Economics: Lối Đi Tối Ưu Chi Phí 70% Cho Doanh Nghiệp SMEs
1. Bài toán chi phí AI: Rào cản lớn nhất của các doanh nghiệp SMEs Trong cuộc đua tích hợp trí tuệ nhân tạo (AI) để nâng cao năng suất và tự động hóa quy trình, các doanh nghiệp vừa và nhỏ (SMEs) thường phải đối mặt với một bức tường tài chính khổng lồ. Việc gọi API đến các mô hình ngôn ngữ lớn (LLM) cao cấp đám mây như GPT-4 hay Gemini 1.5 Pro ban đầu có vẻ rẻ, nhưng khi quy mô người dùng tăng lên và các tác vụ tự động hóa chạy liên tục, hóa đơn tiền điện toán đám mây sẽ nhanh chóng trở thành một cơn ác mộng tài chính. Theo số liệu thống kê mới nhất, chi phí vận hành các hệ thống AI thông qua API đám mây công cộng có thể chiếm tới 30% đến 40% tổng chi phí vận hành công nghệ (SaaS/Cloud costs) của một doanh nghiệp khởi nghiệp số. Hóa đơn hàng tháng tăng vọt khiến nhiều doanh nghiệp SMEs phải ngậm ngùi tạm dừng hoặc thu hẹp quy mô dự án AI của mình. Bài toán đặt ra cho các nhà quản trị công nghệ năm 2026 không chỉ là 'AI làm được gì', mà quan trọng hơn là 'làm sao vận hành AI với chi phí hiệu quả nhất'. Đây chính là điểm khởi đầu của ngành khoa học mới: AI Economics (Kinh tế học trí tuệ nhân tạo). 2. Khái niệm AI Economics và Sự bùng nổ của Mô hình Hybrid-LLM AI Economics tập trung vào việc cân bằng giữa ba yếu tố cốt lõi của hệ thống AI: Độ chính xác (Accuracy), Độ trễ phản hồi (Latency) và Chi phí vận hành (Cost). Để tối ưu hóa bài toán này, xu hướng bùng nổ của năm 2026 chính là việc áp dụng kiến trúc Hybrid-LLM (Mô hình ngôn ngữ lớn lai ghép). Hybrid-LLM là kiến trúc phân lớp thông minh kết hợp linh hoạt giữa các Mô hình Ngôn ngữ Nhỏ nguồn mở (Small Language Models - SLMs) chạy cục bộ hoặc trên server riêng giá rẻ và các Mô hình đám mây cao cấp (Cloud LLMs). Thay vì gửi mọi yêu cầu của người dùng lên các đám mây đắt đỏ, hệ thống sẽ tự động phân loại và định tuyến tác vụ. Thực tế kiểm nghiệm cho thấy, hơn 80% các tác vụ văn phòng hàng ngày (như trích xuất thông tin, tóm tắt văn bản ngắn, phân loại email, lọc từ khóa) hoàn toàn có thể được xử lý hoàn hảo bởi các mô hình nhỏ có kích thước dưới 9 tỷ tham số (như Llama 3 8B, Gemma 2 9B hoặc Phi-3) chạy trực tiếp trên hạ tầng riêng của doanh nghiệp. Các máy chủ chuyên dụng này có chi phí thuê cực kỳ rẻ, chỉ dao động từ 50 USD đến 100 USD mỗi tháng, thay vì chi phí tính theo token đắt đỏ của API đám mây. 3. Cơ chế định tuyến thông minh: Trái tim của giải pháp Hybrid-LLM Trọng tâm vận hành của một hệ thống Hybrid-LLM thành công nằm ở Bộ định tuyến ngữ cảnh (Semantic Router). Khi người dùng gửi một yêu cầu, bộ định tuyến sẽ phân tích độ phức tạp của câu lệnh: Tác vụ mức độ dễ (Lớp 1): Các câu hỏi đơn giản, phân loại dữ liệu, trích xuất thực thể hoặc định dạng HTML/JSON. Bộ định tuyến sẽ chuyển tác vụ này cho mô hình SLM cục bộ xử lý. Thời gian phản hồi của mô hình SLM cục bộ nhanh hơn 3 đến 5 lần so với việc gửi request qua internet đến đám mây, giúp tối ưu hóa đáng kể trải nghiệm người dùng. Tác vụ mức độ khó (Lớp 2): Các tác vụ đòi hỏi lập luận logic đa bước, phân tích báo cáo tài chính hàng trăm trang, hoặc thiết kế kế hoạch chiến lược. Lúc này, hệ thống mới chuyển request lên Cloud LLM cao cấp như GPT-4o để giải quyết. Quy trình phân luồng thông minh này đảm bảo doanh nghiệp chỉ phải trả phí API đám mây cho khoảng 20% số lượng request phức tạp thực tế, loại bỏ hoàn toàn việc lãng phí tài nguyên đám mây cho các tác vụ đơn giản. 4. Lợi ích vượt trội và Con số tiết kiệm 70% thực tế Việc chuyển dịch sang mô hình Hybrid-LLM mang lại những lợi ích vượt trội về mặt tài chính và vận hành cho các doanh nghiệp SMEs: Cắt giảm 70% chi phí API hàng tháng: Đây là con số thực nghiệm đã được chứng minh tại nhiều doanh nghiệp SMEs trong năm 2026. Chi phí vận hành AI giảm sâu giúp giải phóng nguồn lực tài chính để đầu tư vào phát triển sản phẩm và tiếp thị. Gia tăng tỷ suất lợi nhuận (ROI): Theo nghiên cứu của McKinsey về AI Economics, việc giảm thiểu chi phí runtime của AI sẽ giúp tăng tỷ suất sinh lời ROI của các dự án tích hợp công nghệ trong doanh nghiệp lên thêm 45%. Tăng cường bảo mật dữ liệu: Bằng cách giữ lại 80% các tác vụ xử lý thông tin nội bộ trên máy chủ riêng của công ty và chỉ gửi các thông tin không nhạy cảm lên đám mây, doanh nghiệp dễ dàng tuân thủ các quy định bảo mật thông tin khắt khe nhất mà không lo rò rỉ tài sản trí tuệ. 5. Lời kết: Lối đi tài chính thông minh cho SMEs trong kỷ nguyên số Kỷ nguyên ứng dụng AI đại trà đòi hỏi một tư duy quản trị tài chính thực tế và sắc bén. Doanh nghiệp nào biết cách tối ưu hóa chi phí vận hành công nghệ sẽ là người giành chiến thắng lâu dài trong cuộc chạy đua khốc liệt này. Sự kết hợp hoàn hảo giữa các mô hình SLM nguồn mở cục bộ và sức mạnh của Cloud LLM thông qua kiến trúc Hybrid-LLM chính là câu trả lời tốt nhất cho các doanh nghiệp SMEs: mang lại hiệu năng tối đa với mức chi phí tối thiểu, mở đường cho sự phát triển bền vững và hiệu quả trong thời đại số. Tối ưu hóa chi phí không phải là cắt giảm tính năng, mà là sử dụng tài nguyên một cách thông minh nhất. Hãy bắt đầu xây dựng kiến trúc Hybrid-LLM cho doanh nghiệp của bạn ngay hôm nay!

Xây Dựng 'Thế Mạnh Chuyên Môn Độc Quyền' (Domain Expertise Moat) Của Lập Trình Viên Trong Kỷ Nguyên AI
1. Sự thoái trào của 'Gõ Code Thuần Túy': Khi AI trở thành lập trình viên nhanh nhất Trong suốt nhiều thập kỷ qua, nấc thang sự nghiệp của một lập trình viên thường được đo lường bằng khả năng ghi nhớ cú pháp ngôn ngữ, tốc độ gõ code và kỹ năng giải quyết các bài toán thuật toán trên các nền tảng như LeetCode. Tuy nhiên, bước sang năm 2026, sự trưởng thành vượt bậc của các mô hình ngôn ngữ lớn (LLM) và các trợ lý AI tự trị đã đảo lộn hoàn toàn các tiêu chuẩn đánh giá truyền thống này. Việc viết code thô (raw coding) đã chính thức bị thương mại hóa. Theo báo cáo phân tích xu hướng công nghệ mới nhất từ hãng nghiên cứu Gartner, hơn 90% các tác vụ viết mã nguồn và sửa lỗi cú pháp thông thường hiện nay có thể được hoàn thành tự động và chính xác chỉ trong vài giây bởi các mô hình AI tiên tiến. Dữ liệu từ GitHub cũng chỉ ra rằng thời gian viết mã nguồn thô của các lập trình viên đã giảm đến 55% nhờ có sự hỗ trợ của AI. Những kỹ sư phần mềm từng tự hào về tốc độ viết mã của mình giờ đây đang phải đối mặt với một thực tế rõ ràng: AI viết code nhanh hơn, không biết mệt mỏi và có thể học bất kỳ ngôn ngữ lập trình mới nào gần như ngay lập tức. Nếu một lập trình viên chỉ dừng lại ở kỹ năng gõ code thuần túy, họ sẽ nhanh chóng bị thay thế trong một thị trường lao động đang thừa thừa thãi năng lực viết mã thô. 2. Thế mạnh chuyên môn độc quyền (Domain Expertise Moat) là gì? Trước làn sóng càn quét của AI, thành trì duy nhất giúp lập trình viên không bị đào thải và giữ vững giá trị độc bản của mình chính là việc xây dựng một 'Thành trì chuyên môn độc quyền' (Domain Expertise Moat). Khái niệm này mượn thuật ngữ kinh tế học 'Moat' (hào nước bảo vệ lâu đài) để chỉ lợi thế cạnh tranh cốt lõi mà các đối thủ cạnh tranh hoặc công cụ AI rất khó có thể bắt chước hoặc vượt qua. Trong kỹ nghệ phần mềm, Domain Moat của một lập trình viên không được xây dựng bằng số lượng ngôn ngữ lập trình họ biết, mà bằng sự am hiểu sâu sắc về nghiệp vụ kinh doanh (Domain Knowledge) của một lĩnh vực chuyên biệt cụ thể (ví dụ: công nghệ tài chính - Fintech, y tế số - Healthtech, chuỗi cung ứng - Supply Chain, an ninh mạng, hoặc luật pháp và tuân thủ). Khảo sát diện rộng của McKinsey cho thấy: những lập trình viên sở hữu sự am hiểu nghiệp vụ chuyên sâu mang lại năng suất đóng góp giá trị thực tế cao hơn 40% cho doanh nghiệp. Lý do là vì hơn 85% các dự án phần mềm thất bại trên thực tế không phải do lỗi kỹ thuật (coding bugs), mà xuất phát từ sự thiếu hiểu biết hoặc sai lệch nghiêm trọng về mặt logic nghiệp vụ kinh doanh giữa đội ngũ lập trình và yêu cầu thực tế của thị trường. 3. Ba bước chiến lược để xây dựng thành trì chuyên môn trong kỷ nguyên AI Để tự chuyển dịch bản thân từ một 'thợ gõ code' thành một chuyên gia giải pháp sở hữu Domain Moat vững chắc, lập trình viên cần thực hiện ba bước thay đổi tư duy và hành động chiến lược sau: Bước 1: Chọn một lĩnh vực nghiệp vụ dọc (Vertical Industry) để đào sâu: Thay vì học thêm một framework lập trình mới, hãy dành thời gian nghiên cứu các tài liệu nghiệp vụ của ngành. Nếu bạn làm trong mảng tài chính, hãy học về các quy định kế toán, cấu trúc hệ thống thanh toán quốc tế hoặc cơ chế quản trị rủi ro tín dụng. Đây là những tri thức cực kỳ phức tạp và mang tính thực chứng cao. Bước 2: Học cách nói ngôn ngữ của doanh nghiệp (Business Language): Thay vì giao tiếp bằng các thuật ngữ kỹ thuật như API, Database, Docker với khách hàng và nhà quản lý, hãy học cách thảo luận bằng các chỉ số kinh doanh như doanh thu, tỷ lệ chuyển đổi, chi phí vận hành và quy trình nghiệp vụ. Lập trình viên biết kết nối công nghệ với giá trị kinh doanh chính là những người mà mọi doanh nghiệp đều săn đón. Mức lương trung bình của nhóm 'Kỹ sư Lập trình lai Nghiệp vụ' này tại các tập đoàn lớn hiện cao hơn 35% so với mặt bằng chung. Bước 3: Tập trung vào tư duy thiết kế hệ thống và giải quyết vấn đề (System Design & Problem Solving): Hãy tận dụng AI để xử lý toàn bộ phần viết code thô, giải phóng bản thân để tập trung vào các tác vụ cấp cao hơn như thiết kế kiến trúc phần mềm sạch, tối ưu hóa luồng đi của dữ liệu và đảm bảo tính bảo mật, mở rộng của hệ thống. 4. Tư duy thiết kế hệ thống và làm chủ logic nghiệp vụ phức tạp Trong khi AI rất giỏi giải quyết các đoạn code ngắn, các hàm thuật toán đơn lẻ hoặc các bài toán LeetCode có cấu trúc sẵn, nó lại tỏ ra lúng túng khi phải đối mặt với các hệ thống lớn có hàng trăm dịch vụ liên kết với nhau hoặc các quy trình nghiệp vụ thay đổi liên tục theo quy định pháp luật thực tế của từng quốc gia. Đây chính là vùng đất vàng của trí tuệ con người. Theo khảo sát tuyển dụng công nghệ năm 2026, có tới 70% nhà tuyển dụng ưu tiên phỏng vấn các ứng viên có kiến thức chuyên môn sâu về một lĩnh vực kinh doanh cụ thể và tư duy hệ thống thay vì chỉ kiểm tra các bài toán thuật toán thuần túy. Khả năng thấu hiểu hành vi người dùng, dự đoán các kịch bản lỗi nghiệp vụ phức tạp và thiết kế một kiến trúc phần mềm linh hoạt (Domain-Driven Design) chính là hào nước sâu nhất bảo vệ vị thế của lập trình viên trước sự thay đổi của công nghệ. 5. Lời kết: Trở thành kiến trúc sư giải pháp thay vì người gõ phím Kỷ nguyên AI không tiêu diệt nghề lập trình, nó chỉ định nghĩa lại vai trò của người lập trình viên. Những người bám trụ lấy kỹ năng viết code thô ráp sẽ bị dòng chảy công nghệ cuốn trôi, nhưng những người biết nâng cấp bản thân lên tầm kiến trúc sư giải pháp am hiểu nghiệp vụ sẽ ngày càng tỏa sáng. Bằng việc xây dựng cho mình một Domain Moat vững chắc, biến AI thành trợ thủ đắc lực để giải phóng sức lao động chân tay và tập trung trí tuệ vào việc giải quyết những bài toán nghiệp vụ phức tạp của doanh nghiệp, bạn sẽ luôn là nhân tố không thể thay thế trong bất kỳ tổ chức nào. Tương lai thuộc về những lập trình viên biết dùng công nghệ để giải quyết các vấn đề thực tế của con người! Đừng cố gắng trở thành một chiếc máy gõ code nhanh hơn AI, vì bạn sẽ thua cuộc. Hãy trở thành người hiểu rõ tại sao đoạn code đó cần được viết ra và nó mang lại giá trị gì cho thế giới!

Kỹ Năng Quản Trị Thông Tin Cá Nhân: Xây Dựng Bộ Lọc Tin Tức Tự Động Chống Quá Tải Thông Tin Với RSS Và AI
1. Hội chứng quá tải thông tin và cơn lũ dữ liệu số Trong kỷ nguyên số hóa bùng nổ hiện nay, thông tin không còn là tài nguyên khan hiếm, mà ngược lại, đã trở thành một thứ áp lực khổng lồ đè nặng lên tâm lý mỗi người. Các thuật toán mạng xã hội được thiết kế tinh vi để giữ chân người dùng thông qua cơ chế cuộn vô tận (infinite scroll) và các tiêu đề giật gân (clickbait). Người dùng liên tục bị tấn công bởi hàng loạt tin tức, thông báo, bài viết từ nhiều nguồn khác nhau, dẫn đến trạng thái quá tải thông tin nghiêm trọng. Theo các nghiên cứu khoa học năm 2026, một người dùng internet trung bình hiện nay tiếp nhận tới 34 GB dữ liệu thông tin mỗi ngày, tương đương với việc đọc khoảng 100.000 từ. Khảo sát từ Pew Research Center chỉ ra hơn 70% người trưởng thành thường xuyên gặp phải hội chứng mệt mỏi và kiệt sức vì thông tin trên mạng xã hội. Tình hình càng trở nên tồi tệ hơn khi sự bùng nổ của AI tạo sinh khiến lượng tin tức giả, tin bài tự động kém chất lượng tăng vọt thêm 200% chỉ trong vòng 2 năm qua. Nếu không trang bị kỹ năng quản trị thông tin cá nhân và xây dựng các bộ lọc chủ động, chúng ta sẽ rất dễ bị cuốn vào vòng xoáy nhiễu loạn thông tin và đánh mất khả năng tập trung sâu sắc. 2. Lấy lại sự chủ động: Thu thập tin tức có chọn lọc bằng giao thức RSS Bước đi tiên quyết để thoát khỏi sự thao túng của các thuật toán mạng xã hội là giành lại quyền kiểm soát nguồn tin của bạn. Thay vì để thuật toán tự quyết định bạn sẽ đọc gì, hãy tự chọn những nguồn tin uy tín, chất lượng và thu thập chúng về một mối. Công cụ tuyệt vời nhất để thực hiện việc này chính là giao thức truyền tin lâu đời nhưng vô cùng mạnh mẽ: RSS (Really Simple Syndication). Bằng cách sử dụng các ứng dụng đọc tin RSS (như Miniflux, FreshRSS hoặc Feedly), bạn có thể đăng ký theo dõi trực tiếp các trang tin công nghệ, blog chuyên ngành hoặc các nguồn tin tức lớn. Giao thức RSS hoạt động theo cơ chế đẩy thông tin trực tiếp theo trình tự thời gian, hoàn toàn không chứa quảng cáo, không có các bài đăng gợi ý gây xao nhãng và không có thuật toán thao túng tâm lý. Nghiên cứu thực tế chứng minh, việc chuyển đổi thói quen đọc tin từ lướt mạng xã hội sang sử dụng RSS giúp người dùng tiết kiệm đến 90% thời gian lướt web vô ích, đồng thời giúp bạn tiếp cận nguồn thông tin chính thống một cách có hệ thống hơn. 3. Tích hợp Trợ lý AI: Bộ lọc thông minh tự động tóm tắt và phân loại Mặc dù RSS giúp bạn thu thập tin tức một cách sạch sẽ, nhưng nếu bạn theo dõi hàng trăm trang web khác nhau, số lượng bài viết chưa đọc (unread posts) vẫn có thể nhanh chóng tích tụ lên đến hàng ngàn bài mỗi ngày, tiếp tục gây ra trạng thái quá tải. Đây chính là lúc chúng ta tích hợp Trợ lý AI (như Gemini hay GPT) để xây dựng một bộ lọc thông tin thông minh vượt trội. Khi các bài viết được tải về qua RSS, một đoạn script Python đơn giản chạy nền có thể tự động gọi API của AI để thực hiện các nhiệm vụ phân tích ngữ nghĩa chuyên sâu: Semantic Filtering (Lọc ngữ nghĩa): AI tự động phân tích tiêu đề và nội dung tóm tắt để chấm điểm độ liên quan với các chủ đề bạn quan tâm (ví dụ: phát triển phần mềm, an ninh mạng). AI sẽ tự động loại bỏ hơn 80% tin tức nhiễu hoặc các bài quảng cáo trá hình. Automated Summarization (Tóm tắt tự động): Với các bài viết chuyên ngành dài hàng ngàn chữ, AI sẽ tự động trích xuất các ý chính (bullet points) và số liệu thực tế quan trọng nhất. Thời gian đọc tin tức hàng ngày của bạn được rút ngắn từ 2 tiếng xuống chỉ còn 15 phút mà vẫn đảm bảo nắm bắt trọn vẹn tri thức cần thiết. Phân loại chủ đề tự động (Auto-Tagging): AI tự gắn thẻ và sắp xếp bài viết vào các danh mục thông minh để bạn dễ dàng tra cứu lại khi cần thiết. 4. Hướng dẫn thiết lập bộ lọc tin tức tự động của riêng bạn Để xây dựng hệ thống quản trị thông tin cá nhân hiệu quả này, bạn có thể tự thiết lập theo 3 bước đơn giản sau: Bước 1: Chọn và phân loại nguồn tin: Lập danh sách khoảng 20-30 trang web, blog chất lượng cao nhất trong lĩnh vực của bạn và lấy link RSS của các trang này. Tránh đăng ký quá nhiều nguồn tin trùng lặp để giảm thiểu nhiễu ban đầu. Bước 2: Sử dụng một RSS Aggregator: Cài đặt một dịch vụ đọc tin như FreshRSS (miễn phí, nguồn mở) để tự động thu thập tin bài định kỳ. Bước 3: Viết script lọc tin bằng AI: Sử dụng thư viện Python kết nối với API của Gemini để đọc tin tức mới từ RSS, yêu cầu AI tóm tắt bài viết dưới 100 từ và lưu kết quả tóm tắt vào ứng dụng ghi chú cá nhân (như Notion hoặc Obsidian). 5. Lời kết: Làm chủ thông tin để làm chủ tri thức Quản trị thông tin cá nhân trong thời đại số không chỉ là một kỹ năng tin học văn phòng thông thường; đó là kỹ năng sinh tồn và phát triển sự nghiệp thiết yếu. Việc chủ động xây dựng cho mình một bộ lọc tin tức thông minh kết hợp giữa RSS và AI sẽ giúp bạn luôn đi trước xu hướng công nghệ mà không bị kiệt sức trước cơn lũ dữ liệu. Hãy dừng việc lướt web thụ động, làm chủ nguồn thông tin đi vào trí óc của bạn và biến dữ liệu hỗn loạn hàng ngày trở thành nguồn tri thức giá trị phục vụ cho sự phát triển lâu dài của bản thân! Thông tin chỉ là dữ liệu thô, chỉ có sự chọn lọc kỹ lưỡng và tư duy chiều sâu mới biến thông tin thành tri thức thực sự. Hãy bắt đầu xây dựng bộ lọc tin tức của riêng bạn ngay hôm nay!

Kỷ Nguyên Tấn Công Mạng Bằng AI (AI-Assisted Attacks) Và Khái Niệm 'Bảo Mật Kháng Cự' (Cyber Resilience)
1. Khi tin tặc được trang bị trí tuệ nhân tạo: Kỷ nguyên AI-Assisted Attacks Bước sang năm 2026, bức tranh an ninh mạng toàn cầu đang trải qua những biến động sâu sắc và khốc liệt chưa từng có. Trí tuệ nhân tạo (AI) không chỉ là trợ thủ đắc lực cho các chuyên gia phòng thủ, mà đã chính thức trở thành món vũ khí tối tân trong tay các băng đảng tội phạm mạng công nghệ cao. Sự xuất hiện của Kỷ nguyên Tấn công mạng bằng AI (AI-Assisted Attacks) đã thay đổi hoàn toàn cách thức mã độc được phát tán và khai thác lỗ hổng. Bằng việc tận dụng các thuật toán học máy và mô hình ngôn ngữ lớn chuyên biệt, tin tặc có thể tự động hóa toàn bộ vòng đời của một cuộc tấn công. AI hỗ trợ viết các đoạn mã khai thác lỗ hổng (exploits) chưa từng được công bố (Zero-day), tối ưu hóa mã độc để vượt qua các phần mềm diệt virus truyền thống, và tự động hóa quá trình dò mật khẩu trên quy mô lớn. Các báo cáo an ninh mạng mới nhất năm 2026 ghi nhận số vụ tấn công mạng có sự can thiệp của AI đã tăng vọt 150% so với cùng kỳ năm trước. Trong đó, khoảng 70% số cuộc tấn công lừa đảo (phishing) sử dụng AI để tự động thu thập thông tin nạn nhân và soạn thảo các email giả mạo cá nhân hóa với văn phong cực kỳ tự nhiên, đánh lừa thành công các bộ lọc bảo mật email tiên tiến nhất hiện nay. 2. Lỗ hổng 24 giờ và sự bất lực của phòng thủ truyền thống Trước khi AI bùng nổ, khi một lỗ hổng phần mềm mới được phát hiện, đội ngũ bảo mật thường có một khoảng thời gian đệm kéo dài vài tuần hoặc vài tháng để nghiên cứu, phát triển và cài đặt bản vá (patching) trước khi tin tặc kịp khai thác thực tế. Quy trình này giờ đây đã hoàn toàn sụp đổ. Với sự hỗ trợ của AI, tin tặc có thể quét và tự động phân tích mã nguồn phần mềm để phát hiện lỗi bảo mật, sau đó sinh mã khai thác thực tế chỉ trong vòng chưa đầy 24 giờ (1 ngày) kể từ khi thông tin về lỗ hổng được công bố trực tuyến. Tốc độ tấn công diễn ra nhanh hơn gấp hàng chục lần so với tốc độ vá lỗi thủ công của các kỹ sư hệ thống. Mô hình bảo mật truyền thống - vốn tập trung toàn lực vào việc xây dựng tường lửa kiên cố để ngăn chặn 100% cuộc tấn công từ bên ngoài (Phòng ngự thụ động) - đã chính thức bị vô hiệu hóa. Khi ranh giới mạng của doanh nghiệp trở nên mờ nhạt do xu hướng làm việc từ xa và điện toán đám mây, việc bị xâm nhập chỉ còn là vấn đề thời gian. 3. Chuyển dịch tư duy: Từ phòng ngự thụ động sang 'Bảo mật kháng cự' (Cyber Resilience) Nhận thấy sự bất khả thi của việc ngăn chặn hoàn toàn các cuộc tấn công thông minh bằng AI, các chuyên gia bảo mật hàng đầu thế giới đã chuyển dịch sang một khái niệm mang tính chiến lược: Bảo mật kháng cự (Cyber Resilience). Theo báo cáo dự báo công nghệ của hãng nghiên cứu Gartner, đến năm 2026, khoảng 80% doanh nghiệp lớn sẽ đưa tiêu chí Cyber Resilience làm thước đo sức khỏe an ninh mạng hàng đầu thay thế cho các chỉ số phòng ngừa truyền thống. Bảo mật kháng cự là gì? Cyber Resilience được xây dựng trên một triết lý thực tế: "Chúng ta chấp nhận rằng hệ thống chắc chắn sẽ bị xâm nhập vào một thời điểm nào đó". Thay vì cố gắng ngăn chặn tất cả cuộc tấn công, Cyber Resilience tập trung vào khả năng chuẩn bị sẵn sàng, duy trì hoạt động kinh doanh liên tục ngay cả khi đang bị tấn công, giảm thiểu tối đa thiệt hại và khôi phục lại trạng thái bình thường một cách nhanh chóng nhất. Sự khác biệt nằm ở chỗ: Một doanh nghiệp tập trung vào 'Phòng ngự' sẽ bị sụp đổ hoàn toàn khi tường lửa bị phá vỡ; ngược lại, một doanh nghiệp có 'Sức kháng cự' sẽ cô lập được vùng bị tấn công, duy trì các dịch vụ cốt lõi hoạt động bình thường, và khôi phục dữ liệu tự động mà không làm gián đoạn trải nghiệm của khách hàng. Thống kê thực tế chứng minh, các tổ chức triển khai tốt mô hình Cyber Resilience có thể giảm thiểu thiệt hại tài chính và phục hồi hoạt động kinh doanh nhanh hơn gấp 3 lần so với các doanh nghiệp chỉ dựa vào phòng ngự truyền thống. Đối với các doanh nghiệp không chuẩn bị năng lực kháng cự, chi phí trung bình của một vụ rò rỉ dữ liệu đã leo thang lên mức kỷ lục là 4.8 triệu USD vào năm 2026. 4. Ba trụ cột cốt lõi của một hệ thống Bảo mật kháng cự toàn diện Để xây dựng một chiến lược Cyber Resilience bền vững trước sóng gió tấn công bằng AI, doanh nghiệp cần tập trung vào ba trụ cột kỹ thuật và quy trình cốt lõi: Chủ động giám sát và Phát hiện sớm (Active Detection): Sử dụng chính các mô hình AI phòng ngự để liên tục phân tích hành vi bất thường trong hệ thống nội bộ. Hệ thống có khả năng nhận diện các hoạt động di chuyển ngang (lateral movement) của tin tặc ngay khi chúng vừa xâm nhập và tự động cô lập tài khoản bị ảnh hưởng chỉ trong vài giây. Khả năng vận hành liên tục dưới áp lực (Operational Continuity): Thiết kế kiến trúc hệ thống dạng phân mảnh (Micro-segmentation) và đa đám mây (Multi-cloud). Khi một máy chủ tại phân vùng A bị mã hóa ransomware, hệ thống sẽ tự động chuyển hướng lưu lượng người dùng sang phân vùng B dự phòng, đảm bảo giao dịch không bị gián đoạn. Quy trình phục hồi tự động siêu tốc (Automated Recovery): Thiết lập hệ thống sao lưu dữ liệu tự động, cách ly vật lý hoàn toàn khỏi mạng internet (Immutable Backups). Khi xảy ra sự cố, kịch bản khôi phục tự động (Automated Playbooks) sẽ được kích hoạt để dựng lại toàn bộ hạ tầng cơ sở dữ liệu sạch chỉ trong vòng vài phút thay vì mất nhiều ngày như trước đây. 5. Lời kết: Vững vàng trước cơn bão an ninh mạng thời đại mới Kỷ nguyên tấn công mạng bằng AI đã thiết lập lại luật chơi của thế giới số. Mối đe dọa không còn là những kịch bản tấn công tĩnh có thể dự đoán trước, mà là những tác nhân AI mã độc có khả năng tự thích ứng, tự tìm đường đột nhập siêu tốc. Tuy nhiên, sự chuyển dịch sang tư duy Bảo mật kháng cự (Cyber Resilience) chính là chiếc phao cứu sinh vững chắc giúp các doanh nghiệp và tổ chức tự tin đương đầu với mọi sóng gió. Bằng cách chấp nhận rủi ro, chủ động lập kế hoạch ứng phó và đầu tư vào năng lực phục hồi tự động, chúng ta không chỉ bảo vệ an toàn cho dữ liệu, mà còn bảo vệ sự phát triển bền vững và uy tín của doanh nghiệp trong kỷ nguyên số đầy biến động. An ninh mạng thời đại mới không được đo bằng việc bạn chưa từng bị tấn công, mà được đo bằng việc bạn đứng dậy nhanh như thế nào sau mỗi lần vấp ngã. Hãy xây dựng sức bền cho hệ thống ngay hôm nay!

Giáo Dục Đảo Ngược (Flipped Classroom): Biến Học Sinh Từ 'Người Tiếp Thu' Thành 'Kẻ Chất Vấn' Với Trợ Lý AI
1. Định nghĩa lại lớp học: Sự ra đời của Giáo dục đảo ngược (Flipped Classroom) Trong suốt nhiều thế kỷ qua, mô hình giáo dục truyền thống vẫn vận hành theo một lối mòn quen thuộc: giáo viên đứng trên bục giảng truyền thụ lý thuyết (người nói), học sinh ngồi dưới chép bài tiếp thu thụ động (người nghe). Sau giờ học, học sinh mang một núi bài tập về nhà để tự giải quyết mà không có sự trợ giúp trực tiếp từ thầy cô giáo. Theo thống kê từ tổ chức giáo dục UNESCO, tỷ lệ học sinh bị mất tập trung hoặc rơi vào trạng thái thụ động trong các lớp học truyền thống kiểu cũ lên tới 55%, tạo ra khoảng cách lớn về hiệu quả tiếp thu kiến thức giữa các nhóm năng lực học sinh khác nhau. Để giải quyết triệt để rào cản này, mô hình Giáo dục đảo ngược (Flipped Classroom) đã ra đời và tạo nên một làn sóng cách mạng mạnh mẽ. Quy trình học tập được lật ngược 180 độ: học sinh tự nghiên cứu tài liệu, xem video bài giảng lý thuyết trước ở nhà; thời gian lên lớp được dành trọn vẹn cho việc giải bài tập khó, thảo luận nhóm, phản biện sâu sắc và giải quyết các tình huống thực tiễn. Nghiên cứu thực nghiệm giáo dục năm 2026 chứng minh: hơn 75% học sinh tham gia mô hình giáo dục đảo ngược đạt được mức độ hiểu bài sâu sắc và toàn diện hơn hẳn mô hình cũ. Nhờ việc tự học lý thuyết trước, thời gian thực chất dành cho tương tác phản biện trong lớp học được tăng thêm tới 60%, giúp giáo viên có nhiều thời gian quý báu để kèm cặp, hỗ trợ từng cá nhân học sinh. 2. Trợ lý AI: Người đồng hành kích thích tư duy phản biện Mặc dù mô hình Flipped Classroom có nhiều ưu điểm vượt trội, nhưng thách thức lớn nhất nằm ở khâu tự học ở nhà của học sinh. Làm thế nào để các em học sinh có thể hiểu thấu đáo các khái niệm lý thuyết mới khi không có giáo viên bên cạnh giải thích? Đây chính là nơi các Trợ lý AI thế hệ mới bước lên sân khấu và đóng vai trò như một chất xúc tác giáo dục hoàn hảo. Thay vì chỉ đóng vai trò là một 'bách khoa toàn thư' thụ động đưa ra câu trả lời trực tiếp cho mọi câu hỏi của học sinh, các mô hình AI phục vụ giáo dục năm 2026 đã được tích hợp sâu sắc phương pháp đàm thoại Socrates (Socratic Method). Hơn 90% các trợ lý giáo dục AI chuyên sâu hiện nay được thiết kế để không trả lời ngay lập tức, mà gợi mở các câu hỏi phản biện, hướng dẫn học sinh suy luận từng bước. Học sinh sử dụng AI ở nhà giống như một đối tác thảo luận (sparring partner): các em đưa ra giả thuyết, chất vấn các câu trả lời của AI và tự mình tìm ra lời giải. Cơ chế đối thoại hai chiều này đã nâng cấp vai trò của học sinh từ một 'người tiếp thu kiến thức' thụ động trở thành một 'kẻ chất vấn' chủ động. Thống kê cho thấy, hơn 85% học sinh cảm thấy tự tin hơn hẳn khi tự đặt câu hỏi phản biện sau một thời gian rèn luyện tư duy cùng Trợ lý AI cá nhân tại nhà. 3. Biến học sinh từ 'người tiếp thu' thành 'kẻ chất vấn' Sự chuyển dịch từ việc 'nghe giảng' sang 'chất vấn' là bước ngoặt quyết định hình thành nên tư duy phản biện - một trong những kỹ năng sinh tồn cốt lõi nhất của thế kỷ 21. Khi học sinh được học cách đặt câu hỏi 'Tại sao?', 'Làm thế nào?' và 'Điều gì xảy ra nếu?', các em không còn chấp nhận kiến thức như một chân lý hiển nhiên, mà học cách phân tích, đánh giá nguồn tin và tự xây dựng thế giới quan khoa học của riêng mình. Hiệu quả vượt trội của phương pháp học tập phản biện tích hợp AI: Tăng 40% khả năng ghi nhớ dài hạn: Bằng cách chủ động tranh luận, giải thích lại kiến thức cho Trợ lý AI hiểu và tự tìm kiếm lỗi sai trong lập luận của mình, học sinh lưu giữ thông tin sâu sắc hơn gấp nhiều lần so với việc đọc sách hay nghe giảng đơn thuần. Cá nhân hóa tốc độ học tập: Mỗi học sinh có một nhịp độ tiếp thu khác nhau. Trợ lý AI sẵn sàng giải thích một khái niệm phức tạp theo 10 cách khác nhau, kiên nhẫn trả lời hàng chục câu hỏi dồn dập của học sinh mà không bao giờ tỏ ra mệt mỏi hay phán xét. Tối ưu hóa hiệu suất lớp học: Khi học sinh đã làm chủ được các khái niệm cơ bản nhờ tranh luận với AI ở nhà, buổi học trên lớp của giáo viên sẽ trở thành một diễn đàn thảo luận đỉnh cao, nơi giải quyết các vấn đề phức tạp, tổ chức tranh biện dự án thực tế, giúp tỷ lệ mất tập trung của học sinh giảm sâu từ 55% xuống dưới mức kỷ lục là 15%. 4. Những lưu ý quan trọng để triển khai thành công mô hình giáo dục đảo ngược Để mô hình giáo dục đảo ngược kết hợp AI thực sự mang lại hiệu quả thực tiễn cao, cả nhà trường, giáo viên và phụ huynh cần chú ý thiết lập các nguyên tắc vận hành khoa học: Giới hạn quyền hạn và kiểm soát nguồn thông tin của AI: Trợ lý AI cần được cấu hình chạy trên môi trường giáo dục an toàn, chỉ truy xuất các nguồn tài liệu học thuật đã được kiểm duyệt nhằm tránh việc cung cấp thông tin sai lệch (hallucination) cho học sinh. Đào tạo kỹ năng đặt câu hỏi (Prompting): Giáo viên cần hướng dẫn học sinh cách đặt câu hỏi thông minh, cách phản biện lại các luận điểm của AI một cách logic thay vì chỉ chấp nhận câu trả lời đầu tiên mà AI đưa ra. Duy trì sợi dây kết nối thực tế: AI chỉ là công cụ hỗ trợ tự học ở nhà. Vai trò định hướng định hình nhân cách, kỹ năng làm việc nhóm xã hội và kết nối cảm xúc của người thầy giáo trên lớp vẫn là yếu tố không thể thay thế. 5. Lời kết: Tương lai giáo dục chủ động bắt nguồn từ sự tò mò Giáo dục đảo ngược dưới sự hỗ trợ của các Trợ lý AI đang mở ra một chương mới cho sự nghiệp trồng người. Chúng ta không còn hướng tới việc đào tạo ra những thế hệ học sinh ghi nhớ máy móc để vượt qua các kỳ thi lý thuyết; chúng ta đang đào tạo ra những nhà tư duy độc lập, những bộ óc sáng tạo đầy tò mò, luôn sẵn sàng đặt câu hỏi để thay đổi thế giới xung quanh. Bằng cách biến học sinh thành trung tâm của quá trình học tập, khuyến khích các em tự tin chất vấn và phản biện, giáo dục đảo ngược đang trả lại đúng giá trị nguyên bản của tri thức: đó là sự khám phá chủ động và niềm vui bất tận của việc tự học suốt đời. Học tập không phải là việc làm đầy một chiếc bình chứa, mà là việc thắp sáng một ngọn lửa. Hãy để ngọn lửa tò mò và tư duy phản biện của học sinh được dẫn đường bởi công nghệ và thắp sáng bởi tâm huyết của những người thầy!

Đương Đầu Với 'AI Bloat' Và Rác Code: Làm Sao Để Bảo Vệ Chất Lượng Codebase Trong Thời Đại AI?
1. Thực trạng bùng nổ của AI Bloat: Khi code được sinh ra quá dễ dàng Bước sang năm 2026, sự bùng nổ của các công cụ hỗ trợ lập trình bằng AI như GitHub Copilot, ChatGPT, Gemini hay các Agentic AI chuyên sâu đã thay đổi hoàn toàn cục diện của ngành công nghiệp phần mềm. Viết code chưa bao giờ trở nên nhanh chóng và dễ dàng đến thế. Tuy nhiên, sự tiện lợi này đang đi kèm với một cái giá đắt đỏ mang tên 'AI Bloat' (Sự phình to mã nguồn do AI) hay rác code. Theo báo cáo phân tích mới nhất của GitHub, tính đến giữa năm 2026, hơn **45% mã nguồn mới** được đẩy lên các repository công cộng và nội bộ của doanh nghiệp được sinh ra bởi các công cụ AI. Thay vì dành thời gian suy nghĩ, thiết kế cấu trúc tối ưu, lập trình viên hiện nay có xu hướng yêu cầu AI sinh mã nguồn cho toàn bộ tính năng và dán trực tiếp vào codebase. Khảo sát từ Stack Overflow năm 2026 chỉ ra một con số đáng báo động: **40% lập trình viên** thừa nhận họ thường xuyên sao chép-dán mã nguồn do AI tạo ra mà không đọc hiểu cặn kẽ hoặc kiểm thử kỹ lưỡng. Điều này dẫn đến sự xuất hiện của hàng triệu dòng code thừa, trùng lặp và không tối ưu, khiến các dự án phần mềm phình to một cách mất kiểm soát. 2. Những hiểm họa khôn lường đối với chất lượng phần mềm Sự phình to vô tội vạ của codebase không đơn giản chỉ là vấn đề dung lượng lưu trữ, mà nó trực tiếp tàn phá khả năng duy trì và mở rộng của phần mềm dài hạn. Các hệ quả nghiêm trọng mà doanh nghiệp phải đối mặt bao gồm: Nợ kỹ thuật (Technical Debt) tăng vọt: Báo cáo của tổ chức đánh giá chất lượng phần mềm SonarQube ghi nhận chỉ số nợ kỹ thuật trung bình của các dự án phần mềm toàn cầu đã tăng vọt thêm **50%** chỉ trong vòng 2 năm từ 2024 đến 2026. Lượng code rác tăng khiến thời gian để bảo trì, sửa lỗi hoặc thêm tính năng mới bị kéo dài hơn gấp nhiều lần. Quá tải quy trình đánh giá Pull Request (PR): Lượng mã nguồn đồ sộ do AI sinh ra khiến số lượng PR tăng trung bình **30%**. Đội ngũ Tech Lead và Senior Engineer bị quá tải vì phải đọc hàng ngàn dòng code mỗi ngày. Để kịp tiến độ, quy trình review chéo bị buông lỏng, dẫn đến việc lọt lưới các lỗi bảo mật nghiêm trọng. Rủi ro bảo mật và hiệu năng nghèo nàn: AI thường sinh mã dựa trên các mẫu phổ biến trên Internet nhưng thiếu đi sự tối ưu cho môi trường thực tế. Tỷ lệ lỗi logic và lỗ hổng bảo mật trong các dòng code do AI tạo ra đã tăng thêm **25%** so với mã nguồn do con người tự tay thiết kế và kiểm thử bài bản. Chi phí vận hành leo thang: Theo khảo sát của McKinsey, các doanh nghiệp phải chi thêm trung bình **35% ngân sách bảo trì** chỉ để dọn dẹp các đoạn code rác, sửa chữa các cấu trúc thừa thãi do AI tạo ra nhằm tối ưu lại hiệu suất hệ thống. 3. Thiết lập bộ lọc thép: Quy trình kiểm thử và công cụ Lint tự động Để ngăn chặn làn sóng rác code tràn vào codebase, doanh nghiệp cần thiết lập các rào cản tự động hóa nghiêm ngặt ngay tại quy trình tích hợp liên tục (CI/CD). Đây được coi là 'bộ lọc thép' đầu tiên giúp ngăn chặn code kém chất lượng từ xa. Cấu trúc bộ lọc tự động hóa cần triển khai: Cấu hình Linter và Tĩnh phân tích (Static Analysis) cực kỳ nghiêm ngặt: Sử dụng các công cụ như ESLint, Ruff hoặc SonarQube với các ruleset chặt chẽ để phát hiện ngay lập tức các đoạn code trùng lặp (duplicate code), các hàm quá dài, biến không sử dụng, hoặc các đoạn mã lỗi thời mà AI thường mắc phải. Hệ thống phải từ chối merge nếu linter không đạt điểm tối đa. Độ phủ kiểm thử tự động (Unit Test Coverage) bắt buộc trên 80%: Mọi Pull Request chứa code do AI sinh ra bắt buộc phải đi kèm với hệ thống unit test tương ứng. Các công cụ CI/CD tự động chạy test và đảm bảo độ phủ (coverage) đạt trên **80%** mới cho phép chuyển sang bước duyệt thủ công. Các bài test tự động này có khả năng sàng lọc và loại bỏ tới **80% lỗi cú pháp và logic cơ bản** ngay lập tức. Quy định kiểm soát kích thước mã nguồn: Giới hạn số lượng dòng code thay đổi tối đa cho mỗi PR (ví dụ: không quá 300 dòng). Điều này ngăn chặn việc lập trình viên nộp những PR khổng lồ chứa hàng ngàn dòng code do AI viết mà không ai có thể kiểm soát nổi. 4. Giữ vững giá trị cốt lõi: Quy trình đánh giá thủ công và tư duy kiến trúc sạch Công cụ tự động chỉ giải quyết được phần ngọn. Để bảo vệ codebase một cách bền vững, yếu tố con người và tư duy thiết kế hệ thống vẫn là thành trì quan trọng nhất. Những nguyên tắc vàng trong phát triển phần mềm thời đại AI: Tư duy 'AI code là chưa an toàn': Luôn tiếp cận mã nguồn do AI viết với thái độ hoài nghi. Tech Lead cần đào tạo lập trình viên thói quen refactor lại mã nguồn của AI, lược bỏ những đoạn dư thừa và chỉ giữ lại lõi logic thực sự cần thiết. Đề cao các quy chuẩn Clean Code và Design Patterns: Trước khi viết code, hãy dành thời gian thiết kế kiến trúc phần mềm sạch sẽ (Clean Architecture, SOLID principles). AI có thể viết code nhanh, nhưng con người mới là người định hướng cấu trúc. Một hệ thống có kiến trúc tốt sẽ tự giới hạn phạm vi tác động của mã nguồn rác. Tổ chức các buổi Code Review thực chất: Khuyến khích việc thảo luận trực tiếp, giải thích tường tận tại sao đoạn code này được viết như vậy thay vì chỉ bấm nút phê duyệt một cách thụ động. 5. Lời kết: Làm chủ AI, đừng để AI làm mờ nhạt chất lượng phần mềm AI là một trợ thủ đắc lực giúp tăng tốc độ phát triển dự án, nhưng nó không thể thay thế trách nhiệm của người lập trình đối với chất lượng của sản phẩm cuối cùng. Sự bùng nổ của AI Bloat chính là hồi chuông cảnh tỉnh cho thấy tốc độ không bao giờ có thể thay thế cho chất lượng và tư duy chiều sâu. Bằng việc kết hợp chặt chẽ giữa các công cụ tự động hóa kiểm định nghiêm ngặt và quy trình đánh giá nghiêm túc của con người, chúng ta hoàn toàn có thể khai thác tối đa sức mạnh của AI mà vẫn giữ cho codebase luôn sạch sẽ, tối ưu và sẵn sàng cho những bước phát triển đột phá tiếp theo trong tương lai. Chìa khóa của sự phát triển bền vững trong kỷ nguyên số không nằm ở việc viết ra bao nhiêu dòng code, mà nằm ở việc giữ lại bao nhiêu dòng code thực sự giá trị. Hãy làm chủ công cụ và đặt chất lượng sản phẩm lên hàng đầu!

Kỷ Nguyên AI Agents Trên Thiết Bị (On-Device Agents): Tự Chủ Bộ Nhớ Dài Hạn Và Triệt Tiêu Độ Trễ
1. Cuộc dịch chuyển lịch sử từ những đám mây xa xôi về phần cứng cục bộ Trong giai đoạn đầu bùng nổ của trí tuệ nhân tạo (2023 - 2025), việc vận hành AI gắn liền với khái niệm điện toán đám mây. Người dùng đã quá quen thuộc với việc gửi các yêu cầu dịch thuật, viết code, hay phân tích dữ liệu lên các máy chủ khổng lồ của các tập đoàn công nghệ lớn và chờ đợi phản hồi. Mô hình vận hành tập trung này đã giúp phổ cập nhanh chóng sức mạnh của các mô hình ngôn ngữ lớn (LLM). Tuy nhiên, bước sang năm 2026, thế giới công nghệ đang chứng kiến một cuộc chuyển dịch mang tính lịch sử: Kỷ nguyên của các Tác nhân AI trên thiết bị (On-Device AI Agents). Sự bùng nổ này được thúc đẩy bởi sự kết hợp hoàn hảo giữa hai yếu tố: **Sự hoàn thiện của chip xử lý AI (NPU)** và **Sự ra đời của các mô hình ngôn ngữ nhỏ (Small Language Models - SLMs) hiệu năng cao**. Thay vì hoạt động như một ứng dụng web thụ động, AI giờ đây đã trở thành các tác nhân tự trị (Agents), vận hành độc lập ngay trên chiếc laptop, điện thoại thông minh hoặc thiết bị đeo của cá nhân mà không cần kết nối Internet. Theo báo cáo phân tích thị trường mới nhất của hãng nghiên cứu Canalys, thị phần máy tính AI PC (các máy tính tích hợp nhân xử lý NPU chuyên dụng) đang bùng nổ với tốc độ chưa từng có, dự kiến chiếm đến **60% tổng lượng PC xuất xưởng toàn cầu vào năm 2026**. Trí thông minh nhân tạo bản địa (native AI) chạy trực tiếp trên phần cứng của người dùng không còn là một ý tưởng lý thuyết, mà đã chính thức trở thành tiêu chuẩn công nghệ mới của kỷ nguyên điện toán cá nhân. 2. Triệt tiêu độ trễ: Sức mạnh bứt phá của NPU so với API đám mây Một trong những rào cản lớn nhất của AI đám mây truyền thống là độ trễ (latency). Khi tương tác với các mô hình đám mây qua cổng API, yêu cầu của bạn phải đi qua nhiều tầng trung gian: mạng internet -> hàng đợi trên server -> quá trình xử lý suy luận -> truyền ngược kết quả lại thiết bị. Quy trình phức tạp này khiến độ trễ phản hồi trung bình dao động từ **1.5 đến 2.5 giây (1500ms - 2500ms)**. Đối với các tác vụ thông thường như viết blog hay dịch thuật, vài giây chờ đợi có thể chấp nhận được. Tuy nhiên, đối với các tác nhân AI tự trị (AI Agents) thực hiện các quy trình đa bước phức tạp (như tự động kiểm thử phần mềm liên tục, điều khiển giao diện hệ điều hành hoặc hỗ trợ giọng nói thời gian thực), độ trễ hàng giây sẽ phá vỡ hoàn toàn trải nghiệm người dùng và làm giảm hiệu suất vận hành. On-Device AI giải quyết bài toán độ trễ thế nào? Đáp ứng tức thì dưới 50ms - 100ms: Nhờ nhân xử lý AI chuyên dụng – **NPU (Neural Processing Unit)** đạt tiêu chuẩn hiệu năng phần cứng năm 2026 từ **45 đến 55 TOPS** (Trillion Operations Per Second) trên các thiết bị PC và di động – các mô hình ngôn ngữ nhỏ (SLM) có thể thực hiện suy luận cục bộ siêu tốc. Thời gian phản hồi được rút ngắn xuống dưới **50ms - 100ms** (nhanh hơn từ 15 đến 25 lần so với đám mây), tạo ra trải nghiệm tương tác tự nhiên, mượt mà và tức thì. Tiết kiệm năng lượng cực đoan: Chip NPU được thiết kế tối ưu hóa riêng cho các phép toán ma trận của mạng nơ-ron, giúp tiêu thụ điện năng chỉ bằng **1/10 đến 1/20** so với việc chạy GPU truyền thống trên thiết bị, giúp kéo dài thời lượng pin của thiết bị di động lên đáng kể. Độ tin cậy tuyệt đối: Hệ thống vận hành hoàn hảo ngay cả trong môi trường không có kết nối internet như trên máy bay, các vùng sâu vùng xa hoặc các phòng thí nghiệm bảo mật cao bị cách ly hoàn toàn. 3. Tự chủ bộ nhớ dài hạn cục bộ (Long-Term Memory Autonomy) Một trong những điểm đột phá lớn nhất của On-Device AI Agents thế hệ mới năm 2026 chính là khả năng tự chủ quản lý bộ nhớ dài hạn (Long-Term Memory) mà không phụ thuộc vào lưu trữ đám mây. Khác với các mô hình trước đây vốn "quên" ngữ cảnh ngay khi kết thúc phiên chat, các tác nhân AI cục bộ tự xây dựng và vận hành một hệ cơ sở dữ liệu vector cá nhân (Local Vector Database) siêu tối giản trực tiếp trên ổ cứng thiết bị. Cách thức vận hành của bộ nhớ dài hạn tự trị: Ghi nhớ thói quen và ngữ cảnh sử dụng: Hệ thống tự động ghi nhận các tài liệu bạn thường đọc, cấu trúc viết code ưa thích, hoặc phong cách viết email hàng ngày để tạo thành các file vector nhúng (vector embeddings) cục bộ. Truy xuất ngữ cảnh tức thời dưới 10ms: Khi bạn bắt đầu một công việc mới, AI Agent sẽ tự động thực hiện tìm kiếm ngữ nghĩa trên Vector DB cục bộ để tải lại các thông tin liên quan chỉ trong chưa đầy **10ms**, giúp Agent hiểu ngay bạn muốn làm gì mà không cần bạn phải nhập lại bối cảnh từ đầu. Bảo vệ quyền riêng tư tuyệt đối: Toàn bộ dữ liệu bộ nhớ dài hạn của bạn được lưu trữ vật lý 100% trên thiết bị cá nhân và được mã hóa bằng thuật toán cấp quân sự của hệ điều hành. Theo khảo sát bảo mật từ Cisco, **65% tổ chức doanh nghiệp** đã cấm nhân viên gửi dữ liệu nhạy cảm lên đám mây công cộng; vì thế, bộ nhớ dài hạn cục bộ là giải pháp duy nhất giúp doanh nghiệp vừa khai thác được sức mạnh AI cá nhân hóa vừa bảo mật tuyệt đối tài sản trí tuệ. 4. Sức mạnh của SLMs lượng tử hóa: Trọng tâm của cuộc cách mạng cục bộ Để một mô hình AI có thể chạy mượt mà ngay trên các thiết bị cá nhân có cấu hình giới hạn mà không làm nghẽn RAM, công nghệ lượng tử hóa mô hình (Model Quantization) đã đóng vai trò là chiếc chìa khóa vàng. Lượng tử hóa 4-bit (4-bit quantization) là kỹ thuật nén thông minh, chuyển đổi các trọng số của mô hình từ dạng số thực 16-bit phức tạp xuống dạng số nguyên 4-bit siêu gọn nhẹ: Tối ưu hóa dung lượng RAM: Một mô hình ngôn ngữ nhỏ (SLM) với khoảng 7 đến 8 tỷ tham số (7B/8B) thông thường cần khoảng 16 GB bộ nhớ RAM để vận hành. Sau khi lượng tử hóa xuống mức 4-bit, dung lượng mô hình giảm mạnh chỉ còn khoảng **4.5 GB đến 5 GB RAM**, giúp thiết bị dễ dàng chạy song song AI Agent cùng các ứng dụng văn phòng khác mà không gây giật lag. Bảo toàn 95% năng lực suy luận: Mặc dù kích thước mô hình giảm đi đáng kể, các nghiên cứu thực nghiệm năm 2026 chứng minh các mô hình SLM lượng tử hóa vẫn giữ được tới **95% năng lực suy luận logic** và độ chính xác so với mô hình gốc chưa nén. Tích hợp sâu vào hệ điều hành: Microsoft Copilot Runtime và Apple Intelligence đang tích hợp sâu các mô hình SLMs này trực tiếp vào lõi hệ điều hành, cho phép các lập trình viên gọi trực tiếp API cục bộ của thiết bị để xây dựng các ứng dụng thông minh mà không cần tự duy trì hạ tầng mô hình riêng. 5. Lời kết: Tương lai tự trị nằm ngay trên bàn làm việc của bạn Kỷ nguyên AI Agents trên thiết bị đánh dấu sự trưởng thành vượt bậc của cả phần cứng lẫn thuật toán học máy. Chúng ta đang chứng kiến sự kết thúc của thời kỳ phụ thuộc hoàn toàn vào các siêu đám mây tập trung, mở đầu cho kỷ nguyên dân chủ hóa trí tuệ nhân tạo, nơi mỗi cá nhân đều sở hữu một trợ lý AI thông minh, độc quyền, bảo mật tuyệt đối và phản hồi tức thì. Với sức mạnh xử lý vượt trội của chip NPU thế hệ mới cùng sự tối ưu hóa cực đoan của các mô hình SLMs lượng tử hóa và bộ nhớ dài hạn tự trị, rào cản về chi phí API và mối lo ngại rò rỉ dữ liệu đã chính thức bị phá bỏ. Tương lai của trí tuệ nhân tạo không còn nằm ở đâu đó xa xôi trên những cụm máy chủ đám mây khổng lồ; tương lai ấy đang vận hành âm thầm, mạnh mẽ và an toàn ngay trong chính lòng bàn tay và trên bàn làm việc của bạn.

Tự Hào Học Viên Võ Nguyên Khang Xuất Sắc Tranh Tài Tại Bán Kết Hội Thi Tin Học Trẻ TP.HCM Lần Thứ 35
1. Tự Hào Võ Nguyên Khang – Đại Diện Xuất Sắc Lọt Vào Vòng Bán Kết Tin Học Trẻ TP.HCM Lần Thứ 35 Sáng ngày 05/6/2026, bầu không khí tại Trường Tiểu học Long Liên (xã Long Điền, Thành phố Hồ Chí Minh) đã diễn ra một sự kiện vô cùng ý nghĩa và đầy tự hào. Em Võ Nguyên Khang, học sinh lớp 5C, đã chính thức bước vào cuộc tranh tài tại vòng Bán kết Hội thi Tin học trẻ Thành phố Hồ Chí Minh lần thứ 35 – năm 2026. Đây là một sân chơi công nghệ quy mô, uy tín bậc nhất dành cho lứa tuổi học sinh nhằm cụ thể hóa tinh thần Nghị quyết số 57-NQ/TW của Bộ Chính trị về phát triển khoa học công nghệ và chuyển đổi số quốc gia, đồng thời tìm kiếm những nhân tố xuất sắc nhất gia nhập đội tuyển thành phố dự thi cấp quốc gia. Hội thi năm nay thu hút hàng ngàn thí sinh đăng ký tranh tài ở các bảng đấu lập trình và sản phẩm sáng tạo. Vượt qua các vòng sơ tuyển gắt gao cấp trường và cấp quận, em Võ Nguyên Khang đã xuất sắc lọt vào danh sách các thí sinh tiểu học đại diện tranh tài tại vòng Bán kết cấp Thành phố (Bảng A - Kỹ năng lập trình Scratch dành cho học sinh Tiểu học). Đối với tập thể sư phạm Trường Tiểu học Long Liên và đặc biệt là đội ngũ giáo viên hướng dẫn tại Trung tâm Ngoại Ngữ Tin Học Nguyễn Minh, đây là quả ngọt vô cùng xứng đáng cho trí thông minh, tinh thần ham học hỏi và ý chí kiên trì vượt khó của cậu học trò nhỏ. 2. Nghị Lực Vượt Bậc: Ôn Luyện Cấp Tốc 1 Tháng Song Song Kỳ Thi Học Kỳ Hành trình đến với vòng Bán kết Tin học trẻ năm nay của Võ Nguyên Khang là một câu chuyện truyền cảm hứng lớn cho các bạn học viên tại Ngoại Ngữ Tin Học Nguyễn Minh. Khác với các thí sinh có thời gian chuẩn bị dài hơi từ đầu năm học, khóa học bồi dưỡng chuyên sâu của Khang tại trung tâm chỉ diễn ra vỏn vẹn trong 1 tháng (30 ngày) trước kỳ thi chính thức. Khó khăn càng thêm chồng chất khi khoảng thời gian ôn luyện Tin học trẻ cao độ này lại trùng khớp hoàn toàn với lịch thi học kỳ cuối năm tại trường tiểu học của Khang. Đây là thời điểm em phải đối mặt với áp lực học tập gấp đôi: vừa phải hoàn thành tốt các bài kiểm tra văn hóa trên lớp để duy trì học lực giỏi, vừa phải miệt mài giải quyết các bài toán lập trình hóc búa tại trung tâm. Thầy và trò tại Ngoại Ngữ Tin Học Nguyễn Minh đã phải làm việc với 200% nỗ lực. Lộ trình ôn tập được thiết kế linh hoạt, khoa học nhằm tối ưu hóa quỹ thời gian eo hẹp của em. Không phụ lòng mong mỏi của thầy cô, trong suốt 1 tháng qua, Khang đã tự mình vượt qua hơn 50 thử thách thuật toán lập trình Scratch, rèn luyện thuần thục kỹ năng vẽ hình hình học nâng cao, xử lý biến số phức tạp và tối ưu cấu trúc vòng lặp dưới sự đồng hành sát sao của đội ngũ giáo viên giàu kinh nghiệm. 3. Sự Bình Tĩnh Và Bản Lĩnh Trong Phòng Thi Bán Kết Trực Tuyến Vòng Bán kết Hội thi Tin học trẻ TP.HCM lần thứ 35 được tổ chức theo hình thức trực tuyến (online) để đảm bảo tính tiếp cận rộng rãi cho học sinh các khu vực. Tuy nhiên, Ban tổ chức vẫn áp dụng các quy chuẩn giám sát cực kỳ nghiêm ngặt. Buổi thi diễn ra ngay tại phòng máy của Trường Tiểu học Long Liên dưới sự giám sát trực tiếp của giám thị coi thi và hệ thống camera kết nối trực tuyến với Hội đồng thi Thành phố nhằm bảo đảm tính khách quan, minh bạch và đúng quy chế. Đề thi Bảng A năm nay được đánh giá là có cấu trúc phân hóa mạnh, đòi hỏi tư duy thuật toán cao. Với giới hạn thời gian làm bài, thí sinh phải vừa thể hiện được kỹ năng lập trình Scratch trôi chảy, vừa phải tối ưu hóa mã nguồn để bài thi đạt điểm tuyệt đối trên hệ thống tự động. Dù đối mặt với áp lực lớn từ phòng thi và khối lượng kiến thức học kỳ vừa trải qua, em Võ Nguyên Khang đã thể hiện một bản lĩnh thi đấu tuyệt vời. Em tập trung cao độ, chấp hành tốt mọi quy chế phòng thi và nỗ lực hoàn thành bài thi một cách trọn vẹn, chỉn chu nhất cho đến giây phút cuối cùng. 4. Đồng Hành Và Phát Triển Tài Năng Trẻ Tại Ngoại Ngữ Tin Học Nguyễn Minh Thành công bước đầu của em Võ Nguyên Khang tại Hội thi Tin học trẻ cấp Thành phố lần thứ 35 là niềm tự hào chung của gia đình, nhà trường và tập thể thầy cô giáo tại Ngoại Ngữ Tin Học Nguyễn Minh. Đây cũng là minh chứng rõ nét cho chất lượng đào tạo và phương pháp giảng dạy lấy học viên làm trung tâm của Nguyễn Minh. Tại đây, các khóa học Tin học trẻ được thiết kế bài bản để rèn luyện tư duy logic, tư duy giải quyết vấn đề và năng lực ứng dụng công nghệ thông tin vào thực tiễn cuộc sống cho các em ngay từ lứa tuổi tiểu học. Chúng tôi luôn nỗ lực tạo dựng một môi trường học tập hiện đại, khơi gợi sự sáng tạo tự nhiên của học sinh, giúp các em không chỉ làm chủ công nghệ mà còn tự tin thể hiện mình tại các cuộc thi khoa học kỹ thuật cấp quận, thành phố và quốc gia. Trung tâm Ngoại Ngữ Tin Học Nguyễn Minh xin gửi lời chúc mừng nồng nhiệt nhất đến em Võ Nguyên Khang! Cảm ơn em vì sự nỗ lực phi thường, kiên cường vượt qua áp lực mùa thi học kỳ để hoàn thành xuất sắc vòng thi Bán kết Tin học trẻ Thành phố 2026. Chúc em sẽ gặt hái được kết quả thật cao và xuất sắc bước tiếp vào vòng Chung kết Hội thi Tin học trẻ toàn quốc lần thứ XXXII. Dù kết quả thế nào, sự cố gắng bền bỉ của em trong 1 tháng qua đã là một chiến thắng vô cùng rực rỡ và là niềm tự hào to lớn của toàn thể trung tâm!

Kỷ nguyên AI Agents trên thiết bị (On-Device Agents): Sự dịch chuyển từ Cloud AI sang Local AI nhờ NPU và SLMs nhằm bảo vệ quyền riêng tư và triệt tiêu độ trễ
1. Cuộc dịch chuyển lịch sử từ những đám mây xa xôi về phần cứng cục bộ Trong giai đoạn đầu bùng nổ của trí tuệ nhân tạo (2023 - 2025), việc vận hành AI gắn liền với khái niệm điện toán đám mây. Người dùng đã quá quen thuộc với việc gửi các yêu cầu dịch thuật, viết code, hay phân tích dữ liệu lên các máy chủ khổng lồ của các tập đoàn công nghệ lớn và chờ đợi phản hồi. Mô hình vận hành tập trung này đã giúp phổ cập nhanh chóng sức mạnh của các mô hình ngôn ngữ lớn (LLM). Tuy nhiên, bước sang năm 2026, thế giới công nghệ đang chứng kiến một cuộc chuyển dịch mang tính lịch sử: Kỷ nguyên của các Tác nhân AI trên thiết bị (On-Device AI Agents). Sự bùng nổ này được thúc đẩy bởi sự kết hợp hoàn hảo giữa hai yếu tố: **Sự hoàn thiện của chip xử lý AI (NPU)** và **Sự ra đời của các mô hình ngôn ngữ nhỏ (Small Language Models - SLMs) hiệu năng cao**. Thay vì hoạt động như một ứng dụng web thụ động, AI giờ đây đã trở thành các tác nhân tự trị (Agents), vận hành độc lập ngay trên chiếc laptop, điện thoại thông minh hoặc thiết bị đeo của cá nhân mà không cần kết nối Internet. Theo báo cáo phân tích thị trường mới nhất của hãng nghiên cứu Canalys, thị phần máy tính AI PC (các máy tính tích hợp nhân xử lý NPU chuyên dụng) đang bùng nổ với tốc độ chưa từng có, dự kiến chiếm đến **60% tổng lượng PC xuất xưởng toàn cầu vào năm 2026**. Trí thông minh nhân tạo bản địa (native AI) chạy trực tiếp trên phần cứng của người dùng không còn là một ý tưởng lý thuyết, mà đã chính thức trở thành tiêu chuẩn công nghệ mới của kỷ nguyên điện toán cá nhân. 2. Triệt tiêu độ trễ: Sức mạnh bứt phá của NPU so với API đám mây Một trong những rào cản lớn nhất của AI đám mây truyền thống là độ trễ (latency). Khi tương tác với các mô hình đám mây qua cổng API, yêu cầu của bạn phải đi qua nhiều tầng trung gian: mạng internet -> hàng đợi trên server -> quá trình xử lý suy luận -> truyền ngược kết quả lại thiết bị. Quy trình phức tạp này khiến độ trễ phản hồi trung bình dao động từ **1.5 đến 2.5 giây (1500ms - 2500ms)**. Đối với các tác vụ thông thường như viết blog hay dịch thuật, vài giây chờ đợi có thể chấp nhận được. Tuy nhiên, đối với các tác nhân AI tự trị (AI Agents) thực hiện các quy trình đa bước phức tạp (như tự động kiểm thử phần mềm liên tục, điều khiển giao diện hệ điều hành hoặc hỗ trợ giọng nói thời gian thực), độ trễ hàng giây sẽ phá vỡ hoàn toàn trải nghiệm người dùng và làm giảm hiệu suất vận hành. On-Device AI giải quyết bài toán độ trễ thế nào? Đáp ứng tức thì dưới 50ms - 100ms: Nhờ nhân xử lý AI chuyên dụng – **NPU (Neural Processing Unit)** đạt tiêu chuẩn hiệu năng phần cứng năm 2026 từ **45 đến 55 TOPS** (Trillion Operations Per Second) trên các thiết bị PC và di động – các mô hình ngôn ngữ nhỏ (SLM) có thể thực hiện suy luận cục bộ siêu tốc. Thời gian phản hồi được rút ngắn xuống dưới **50ms - 100ms** (nhanh hơn từ 15 đến 25 lần so với đám mây), tạo ra trải nghiệm tương tác tự nhiên, mượt mà và tức thì. Tiết kiệm năng lượng cực đoan: Chip NPU được thiết kế tối ưu hóa riêng cho các phép toán ma trận của mạng nơ-ron, giúp tiêu thụ điện năng chỉ bằng **1/10 đến 1/20** so với việc chạy GPU truyền thống trên thiết bị, giúp kéo dài thời lượng pin của thiết bị di động lên đáng kể. Độ tin cậy tuyệt đối: Hệ thống vận hành hoàn hảo ngay cả trong môi trường không có kết nối internet như trên máy bay, các vùng sâu vùng xa hoặc các phòng thí nghiệm bảo mật cao bị cách ly hoàn toàn. 3. Bảo vệ quyền riêng tư tuyệt đối: Lá chắn dữ liệu nội bộ vững chắc Bên cạnh độ trễ, quyền riêng tư và an toàn thông tin là mối quan tâm hàng đầu của cả cá nhân và các tổ chức doanh nghiệp. Mỗi khi dữ liệu nhạy cảm – từ mã nguồn phần mềm, báo cáo tài chính doanh nghiệp, đến tin nhắn trò chuyện cá nhân – được gửi lên đám mây của bên thứ ba, nguy cơ rò rỉ dữ liệu hoặc việc thông tin bị sử dụng để huấn luyện các mô hình công cộng luôn hiện hữu. Khảo sát bảo mật toàn cầu mới nhất từ Cisco cho thấy **65% tổ chức doanh nghiệp** đã ban hành quy định nghiêm ngặt cấm nhân viên chia sẻ thông tin nhạy cảm của công ty lên các chatbot AI đám mây công cộng. Điều này vô tình làm hạn chế khả năng ứng dụng AI để tăng năng suất làm việc của nhân sự. Cơ chế bảo mật bản địa của On-Device AI: Không bao giờ rời khỏi thiết bị: Với On-Device AI, toàn bộ quá trình phân tích ngữ cảnh, lưu trữ lịch sử tương tác và suy luận của AI Agent đều diễn ra vật lý 100% bên trong ranh giới phần cứng của bạn. Dữ liệu của bạn không bao giờ phải tải lên bất kỳ máy chủ nào. Tự chủ bảo mật tuyệt đối: Doanh nghiệp có thể tự tin tích hợp AI Agents vào các cơ sở dữ liệu nội bộ nhạy cảm nhất mà không sợ vi phạm các tiêu chuẩn an toàn thông tin khắt khe như GDPR hay HIPAA. Khóa mã hóa cá nhân: Toàn bộ dữ liệu bộ nhớ dài hạn của Agent (như Vector Cache lưu trữ thói quen làm việc) được mã hóa bằng mã khóa của riêng hệ điều hành trên thiết bị, ngăn chặn hoàn toàn các cuộc tấn công đánh cắp danh tính từ bên ngoài. 4. Sức mạnh của SLMs lượng tử hóa: Trọng tâm của cuộc cách mạng cục bộ Để một mô hình AI có thể chạy mượt mà ngay trên các thiết bị cá nhân có cấu hình giới hạn mà không làm nghẽn RAM, công nghệ lượng tử hóa mô hình (Model Quantization) đã đóng vai trò là chiếc chìa khóa vàng. Lượng tử hóa 4-bit (4-bit quantization) là kỹ thuật nén thông minh, chuyển đổi các trọng số của mô hình từ dạng số thực 16-bit phức tạp xuống dạng số nguyên 4-bit siêu gọn nhẹ: Tối ưu hóa dung lượng RAM: Một mô hình ngôn ngữ nhỏ (SLM) với khoảng 7 đến 8 tỷ tham số (7B/8B) thông thường cần khoảng 16 GB bộ nhớ RAM để vận hành. Sau khi lượng tử hóa xuống mức 4-bit, dung lượng mô hình giảm mạnh chỉ còn khoảng **4.5 GB đến 5 GB RAM**, giúp thiết bị dễ dàng chạy song song AI Agent cùng các ứng dụng văn phòng khác mà không gây giật lag. Bảo toàn 95% năng lực suy luận: Mặc dù kích thước mô hình giảm đi đáng kể, các nghiên cứu thực nghiệm năm 2026 chứng minh các mô hình SLM lượng tử hóa vẫn giữ được tới **95% năng lực suy luận logic** và độ chính xác so với mô hình gốc chưa nén. Tích hợp sâu vào hệ điều hành: Microsoft Copilot Runtime và Apple Intelligence đang tích hợp sâu các mô hình SLMs này trực tiếp vào lõi hệ điều hành, cho phép các lập trình viên gọi trực tiếp API cục bộ của thiết bị để xây dựng các ứng dụng thông minh mà không cần tự duy trì hạ tầng mô hình riêng. 5. Lời kết: Tương lai tự trị nằm ngay trên bàn làm việc của bạn Kỷ nguyên AI Agents trên thiết bị đánh dấu sự trưởng thành vượt bậc của cả phần cứng lẫn thuật toán học máy. Chúng ta đang chứng kiến sự kết thúc của thời kỳ phụ thuộc hoàn toàn vào các siêu đám mây tập trung, mở đầu cho kỷ nguyên dân chủ hóa trí tuệ nhân tạo, nơi mỗi cá nhân đều sở hữu một trợ lý AI thông minh, độc quyền, bảo mật tuyệt đối và phản hồi tức thì. Với sức mạnh xử lý vượt trội của chip NPU thế hệ mới cùng sự tối ưu hóa cực đoan của các mô hình SLMs lượng tử hóa, rào cản về chi phí API và mối lo ngại rò rỉ dữ liệu đã chính thức bị phá bỏ. Tương lai của trí tuệ nhân tạo không còn nằm ở đâu đó xa xôi trên những cụm máy chủ đám mây khổng lồ; tương lai ấy đang vận hành âm thầm, mạnh mẽ và an toàn ngay trong chính lòng bàn tay và trên bàn làm việc của bạn.

Sự bùng nổ của Mô hình Hybrid-LLM và AI Economics: Lối đi tối ưu chi phí 70% cho doanh nghiệp SMEs
1. Cơn sốt AI và Thực tế nghiệt ngã của "AI Economics" đối với doanh nghiệp SMEs Trong suốt hai năm qua, trí tuệ nhân tạo (AI) và các mô hình ngôn ngữ lớn (LLM) đã trở thành tâm điểm của mọi chiến lược chuyển đổi số doanh nghiệp. Từ các chatbot chăm sóc khách hàng, hệ thống tóm tắt tài liệu tự động, đến các trợ lý lập trình chuyên sâu, AI đang chứng minh năng lực thay đổi năng suất lao động vượt bậc. Tuy nhiên, khi bước vào giai đoạn triển khai thực tế trên diện rộng, các doanh nghiệp vừa và nhỏ (SMEs) đang phải đối mặt với một thực tế vô cùng nghiệt ngã: Bài toán kinh tế học AI (AI Economics). Việc vận hành hệ thống AI dựa hoàn toàn trên các mô hình đám mây thương mại hàng đầu (như GPT-4o hay Claude 3.5 Sonnet) thông qua cổng API đang tạo ra những gánh nặng tài chính khổng lồ. Đối với một doanh nghiệp SME vận hành hệ thống AI chăm sóc khách hàng quy mô trung bình (khoảng vài chục ngàn yêu cầu mỗi ngày), chi phí điện toán đám mây có thể dễ dàng tiêu tốn từ $5,000 đến $15,000 mỗi tháng. Con số này tăng lũy tiến theo số lượng người dùng và độ dài ngữ cảnh tương tác (tokens), khiến lợi nhuận thu về không đủ bù đắp chi phí vận hành. Theo một khảo sát thực tế diện rộng của tập đoàn tư vấn chiến lược McKinsey đầu năm 2026, có đến **82% doanh nghiệp SMEs** xếp hạng "chi phí vận hành lâu dài" và "tính bất định của hóa đơn API" là những mối quan ngại lớn nhất, cản trở họ tích hợp sâu AI vào quy trình nghiệp vụ cốt lõi. Các doanh nghiệp đang đứng trước thế tiến thoái lưỡng nan: hoặc chịu chi phí vận hành khổng lồ để sở hữu trí tuệ nhân tạo thông minh nhất, hoặc từ bỏ cuộc đua công nghệ để bảo toàn dòng tiền. Để giải quyết triệt để nút thắt cổ chai này, một xu hướng công nghệ mang tính cách mạng đã bùng nổ: Kiến trúc Mô hình lai (Hybrid-LLM). Đây được xem là chiếc phao cứu sinh giúp các doanh nghiệp tối ưu hóa đến 70% chi phí AI mà vẫn duy trì hiệu năng xử lý ở mức tối đa. 2. Mô hình Hybrid-LLM: Giải pháp lai ghép thông minh phá vỡ thế độc tôn đám mây Về cơ bản, kiến trúc **Hybrid-LLM (Mô hình ngôn ngữ lớn dạng lai)** là sự phối hợp nhịp nhàng giữa hai thế giới: các mô hình ngôn ngữ nhỏ (Small Language Models - SLMs) chạy cục bộ trên cơ sở hạ tầng nội bộ của doanh nghiệp (hoặc máy chủ đám mây giá rẻ) và các mô hình ngôn ngữ lớn (LLMs) khổng lồ chạy trên đám mây thương mại đắt tiền. Triết lý cốt lõi của Hybrid-LLM rất đơn giản: Không dùng dao mổ trâu để giết gà. Trong thực tế vận hành doanh nghiệp, có đến 70% - 80% các câu hỏi hoặc tác vụ của người dùng có cấu trúc đơn giản, lặp đi lặp lại và mang tính phân loại cao (ví dụ: tra cứu trạng thái đơn hàng, tóm tắt các văn bản ngắn, phân tích cảm xúc phản hồi của khách hàng, hoặc trả lời các câu hỏi FAQ cơ bản). Những tác vụ này hoàn toàn có thể được xử lý xuất sắc bởi các mô hình ngôn ngữ nhỏ (SLMs) có kích thước dưới 8 tỷ tham số (như Llama 3.2 3B, Phi-3.5 hoặc Gemma 2B) mà không cần đến sức mạnh của các siêu mô hình đám mây đắt đỏ. Chỉ khi gặp những tác vụ cực kỳ phức tạp đòi hỏi khả năng suy luận logic đa tầng, lập kế hoạch phức tạp, phân tích dữ liệu đa nguồn quy mô lớn, hệ thống mới tự động chuyển hướng (routing) yêu cầu lên các mô hình Cloud LLM cao cấp. Nhờ sự phân phối tải thông minh này, doanh nghiệp có thể cắt giảm lượng token gửi lên đám mây một cách cực đoan, giúp giảm trung bình **70% chi phí gọi API** tổng thể mà người dùng cuối không hề nhận ra sự thay đổi trong chất lượng dịch vụ. 3. Trái tim của hệ thống: Bộ định tuyến ngữ nghĩa (Semantic Router) điều phối thông minh Để vận hành trơn tru kiến trúc Hybrid-LLM, thành phần quan trọng nhất chính là **Bộ định tuyến ngữ nghĩa (Semantic Router)** hay AI Router. Bộ định tuyến này hoạt động như một cảnh sát giao thông thông minh đứng ở cổng tiếp nhận yêu cầu đầu vào của người dùng. Quy trình xử lý diễn ra như sau: Khi người dùng nhập một câu hỏi, AI Router (sử dụng một mô hình phân loại siêu nhẹ hoặc cơ chế Vector Embedding tương tự như Semantic Router mã nguồn mở) sẽ đánh giá độ phức tạp và ý định (intent) của câu hỏi đó trong vòng vài mili-giây. Nếu yêu cầu đơn giản (ví dụ: "Hãy định dạng lại đoạn văn bản này thành JSON" hoặc "Cửa hàng mở cửa lúc mấy giờ?"), AI Router sẽ lập tức chuyển hướng (route) yêu cầu này tới mô hình SLM cục bộ đang chạy trên máy chủ nội bộ. Nếu yêu cầu phức tạp (ví dụ: "Hãy viết một kế hoạch tài chính chi tiết dựa trên 5 bảng dữ liệu CSV đính kèm này và so sánh xu hướng thị trường"), AI Router sẽ chuyển hướng yêu cầu lên Cloud LLM đắt tiền hơn. Hiệu năng ấn tượng trong thực tế: Các báo cáo kiểm thử hệ thống định tuyến thông minh năm 2026 cho thấy bộ định tuyến AI đạt **độ chính xác phân phối tác vụ lên đến 98.2%**. Điều này đảm bảo trải nghiệm người dùng hoàn toàn tương đương với việc sử dụng 100% mô hình Cloud đắt tiền. Bên cạnh đó, nhờ việc xử lý cục bộ các tác vụ đơn giản, thời gian phản hồi (Time to First Token - TTFT) trung bình giảm mạnh từ 1.8 giây của đám mây xuống chỉ còn **0.3 giây** (nhanh hơn gấp 6 lần), giúp ứng dụng hoạt động cực kỳ mượt mà. 4. Tối ưu hóa phần cứng nội bộ: Công nghệ lượng tử hóa (Quantization) và Kỷ nguyên AI PC Một trong những rào cản lớn nhất khiến các doanh nghiệp SMEs e ngại việc triển khai mô hình nội bộ là chi phí đầu tư phần cứng (GPU chuyên dụng như NVIDIA H100 hay A100 có giá lên tới hàng chục ngàn USD). Tuy nhiên, sự phát triển vượt bậc của kỹ thuật tối ưu hóa phần mềm năm 2026 đã đập tan rào cản này. Thông qua phương pháp **Lượng tử hóa mô hình (Model Quantization)** – cụ thể là chuyển đổi trọng số mô hình từ định dạng 16-bit float (FP16) truyền thống xuống định dạng 4-bit integer (INT4) – dung lượng của các mô hình ngôn ngữ nhỏ (SLM) đã được thu nhỏ một cách kinh ngạc: Một mô hình ngôn ngữ 8 tỷ tham số (8B) tiêu chuẩn ban đầu đòi hỏi hơn 16 GB bộ nhớ đồ họa để vận hành. Nhưng sau khi được lượng tử hóa xuống mức 4-bit, nó chỉ cần tiêu tốn khoảng **4.8 GB đến 5.5 GB RAM/VRAM** để chạy mượt mà. Điều này đồng nghĩa với việc doanh nghiệp hoàn toàn có thể tận dụng các dòng máy tính văn phòng tiêu chuẩn thế hệ mới – được gọi là **AI PC** tích hợp sẵn chip xử lý NPU chuyên dụng (như Snapdragon X Elite, Intel Core Ultra) để chạy các mô hình SLM cục bộ cực kỳ nhanh chóng mà **không tốn thêm một đồng chi phí phần cứng máy chủ đắt đỏ nào**. SMEs có thể tự chủ hoàn toàn hạ tầng AI cục bộ, tận dụng các tài nguyên phần cứng sẵn có để tạo nên một hệ thống tự trị, bảo mật dữ liệu tuyệt đối và hoạt động 24/7 với chi phí điện năng không đáng kể. 5. Lời khuyên triển khai thực chiến dành cho doanh nghiệp SMEs Để bắt đầu chuyển dịch sang kiến trúc Hybrid-LLM và tối ưu hóa chi phí vận hành AI, doanh nghiệp SMEs nên đi theo lộ trình 3 bước vững chắc: Đánh giá và phân loại tác vụ (Task Audit): Hãy thống kê lại toàn bộ lịch sử sử dụng API đám mây hiện tại của doanh nghiệp. Phân loại xem đâu là các tác vụ đơn giản chiếm tỷ lệ cao và đâu là các tác vụ phức tạp thực sự cần đến Cloud LLM. Triển khai SLM cục bộ làm nền tảng: Lựa chọn các mô hình mã nguồn mở hàng đầu hiện nay như Llama-3 8B hoặc Phi-3.5 lượng tử hóa, chạy thử nghiệm trên phần cứng máy tính sẵn có bằng các công cụ thân thiện như Ollama, LM Studio hoặc vLLM. Xây dựng lớp điều phối AI Router: Sử dụng các framework mã nguồn mở để thiết lập một bộ định tuyến thông minh phân chia ngữ cảnh câu hỏi trước khi gọi API. Kỷ nguyên của việc "đốt tiền" cho các dịch vụ AI đám mây một cách vô tội vạ đã kết thúc. Sự bứt phá của kiến trúc Hybrid-LLM và các nguyên lý tối ưu AI Economics đang mở ra một chương mới đầy hứa hẹn, giúp các doanh nghiệp vừa và nhỏ (SMEs) sở hữu những hệ thống trí tuệ nhân tạo cực kỳ mạnh mẽ, siêu bảo mật, với mức chi phí tiết kiệm đến 70%. Việc nắm bắt và làm chủ công nghệ mô hình lai chính là chìa khóa vàng giúp doanh nghiệp của bạn nâng cao năng lực cạnh tranh bền vững trong tương lai số.

Kỹ năng quản trị thông tin cá nhân: Xây dựng bộ lọc tin tức tự động chống quá tải thông tin với RSS và AI
1. Bẫy quá tải thông tin và Sự suy tàn của các thuật toán mạng xã hội Chúng ta đang sống trong một kỷ nguyên mà thông tin không còn thiếu thốn, ngược lại, nó đang nhấn chìm khả năng xử lý của não bộ mỗi giây. Bước sang năm 2026, khối lượng dữ liệu được tạo ra toàn cầu dự kiến sẽ đạt mức kỷ lục **175 Zettabytes** (theo báo cáo xu hướng dữ liệu của Seagate/IDC). Sự bùng nổ kinh hoàng của các bài viết do AI tạo ra (AI-generated content) cùng các mô hình sáng tạo nội dung hàng loạt đã đẩy loài người vào một hội chứng tâm lý mới: Hội chứng kiệt quệ thông tin. Phần lớn chúng ta thu thập tin tức thông qua bảng tin (feeds) của các mạng xã hội như Facebook, X, LinkedIn hoặc các ứng dụng tin tức tổng hợp. Tuy nhiên, các nền tảng này vận hành dựa trên thuật toán gây nghiện chủ động (Push Algorithms). Mục tiêu duy nhất của chúng là giữ chân bạn càng lâu càng tốt bằng cách phân phối những tiêu đề giật gân, những tranh cãi vô bổ và thông tin lá cải có tính kích thích cao. Kết quả là, chúng ta rơi vào trạng thái tiêu thụ thụ động những "thức ăn rác cho tâm trí" mà không thực sự tiếp thu được tri thức hữu ích nào. Hậu quả của việc này đối với hiệu suất làm việc là vô cùng nặng nề: Lãng phí thời gian khổng lồ: Thống kê từ tập đoàn dữ liệu quốc tế IDC cho thấy trung bình một tri thức văn phòng (knowledge worker) tiêu tốn đến **2.5 giờ mỗi ngày** (tương đương 30% thời gian làm việc chính thức) chỉ để tìm kiếm và sàng lọc giữa hàng ngàn luồng thông tin nhiễu để thấy tài liệu cần thiết. Đánh mất khả năng tập trung sâu: Nghiên cứu kinh điển của Đại học California, Irvine chỉ ra rằng sau khi bị ngắt quãng bởi một thông báo tin tức hoặc một email không liên quan, bộ não con người phải mất trung bình **23 phút và 15 giây** chỉ để thiết lập lại sự tập trung cao độ ban đầu vào công việc cốt lõi. 2. RSS - Quay lại gốc rễ của cơ chế thu thập thông tin chủ động (Information Pull) Để giải thoát bản thân khỏi mê cung thuật toán của các gã khổng lồ công nghệ, bước đi chiến lược đầu tiên là chuyển đổi từ tư duy **nhận thông tin thụ động (Information Push)** sang **chủ động kéo thông tin (Information Pull)**. Công cụ đắc lực nhất làm nền tảng cho triết lý này chính là một công nghệ "cổ điển" nhưng chưa bao giờ lỗi thời: RSS (Really Simple Syndication). RSS cho phép bạn đăng ký trực tiếp nguồn tin từ các trang blog công nghệ uy tín, tạp chí khoa học, hoặc các chuyên mục cụ thể của các tờ báo lớn. Thay vì truy cập vào 20 trang web khác nhau mỗi ngày hoặc lướt mạng xã hội để mong chờ thuật toán phân phối bài viết, tất cả các bài viết mới nhất sẽ được gom tụ về một ứng dụng đọc tin RSS duy nhất của bạn ngay khi chúng được xuất bản. Bạn hoàn toàn làm chủ nguồn đầu vào sạch, không quảng cáo, không clickbait gợi ý, không có bình luận độc hại của cộng đồng. Tuy nhiên, RSS nguyên bản vẫn tồn tại một nhược điểm chí mạng: Thống kê thực tế: Việc ứng dụng RSS cổ điển giúp giảm thời gian duyệt web vô bổ lên tới **60%**. Thế nhưng, tỷ lệ nhiễu thông tin (noise rate) trong các nguồn tin RSS chất lượng vẫn dao động ở mức **70% đến 80%**. Nghĩa là trong 100 bài viết từ các trang blog yêu thích của bạn, chỉ có khoảng 20 bài thực sự phù hợp với dự án, nghiên cứu hoặc mối quan tâm sâu sắc tại thời điểm hiện tại của bạn. Nếu bạn đăng ký khoảng 50 nguồn RSS khác nhau, mỗi ngày bạn vẫn phải đối mặt với **300 - 500 bài viết mới**, dẫn đến tình trạng quá tải hộp thư đọc và tạo ra tâm lý lo âu bỏ lỡ thông tin (FOMO). 3. Sự kết hợp đột phá: AI Agent đóng vai trò bộ lọc ngữ nghĩa thông minh Đây chính là thời điểm mà trí tuệ nhân tạo (AI) bước vào để hoàn thiện mảnh ghép còn thiếu của RSS. Bằng cách tích hợp một tác nhân AI (AI Agent) siêu nhẹ đóng vai trò **Bộ lọc ngữ nghĩa thông minh (Semantic Filter)** đứng giữa luồng RSS đầu vào và hộp thư đọc cuối cùng của bạn, chúng ta có thể triệt tiêu hoàn toàn lượng thông tin rác. Thay vì lọc tin bằng các từ khóa cứng nhắc (Keyword filtering) vốn rất dễ bỏ sót hoặc lấy thừa thông tin, AI Agent sử dụng các mô hình ngôn ngữ lớn (LLM) hoặc mô hình ngôn ngữ nhỏ cục bộ (SLM) để hiểu sâu sắc ngữ cảnh và ý định của người đọc: Đọc hiểu nội dung toàn diện: AI sẽ tự động phân tích tiêu đề, mô tả ngắn và thậm chí là toàn bộ nội dung bài viết để trích xuất các thực thể cốt lõi (Named Entity Recognition - NER) và chủ đề thực tế của bài viết. Đánh giá mức độ liên quan theo thời gian thực: Bạn có thể cấu hình cho AI Agent hiểu rõ vai trò và sở thích hiện tại của bạn. Ví dụ: "Tôi là lập trình viên Backend, hiện đang nghiên cứu về tối ưu hóa cơ sở dữ liệu PostgreSQL và kiến trúc Microservices. Hãy lọc các bài viết liên quan sâu đến chủ đề này". Tự động tóm tắt dạng Bullet-Points: Thay vì bắt bạn đọc một bài phân tích dài 3.000 từ, AI Agent sẽ tự động trích xuất **3-5 luận điểm cốt lõi nhất** cùng các dữ liệu thực chứng quan trọng để bạn nắm bắt chỉ trong 15 giây. Hiệu quả vượt trội: Các thử nghiệm thực tế cho thấy hệ thống lọc kết hợp RSS và AI giúp đạt **độ chính xác từ 92% đến 95%** trong việc phân phối đúng tri thức chất lượng cao đến người dùng. Tỷ lệ nhiễu thông tin được kéo giảm từ 80% xuống còn dưới **5%**, giúp tiết kiệm hàng giờ đồng hồ đọc lướt vô nghĩa mỗi ngày. 4. Hướng dẫn 3 bước xây dựng bộ lọc tự trị chống quá tải thông tin Bạn không cần phải là một chuyên gia AI lão luyện để tự xây dựng hệ thống này. Dưới đây là kiến trúc phân lớp tối giản mà bất kỳ ai cũng có thể triển khai trong vòng 30 phút: Bước 1: Thu thập nguồn tin tinh khiết (The Aggregation Layer) Sử dụng các công cụ quản lý RSS miễn phí hoặc mã nguồn mở như Feedly, Inoreader, hoặc Miniflux. Hãy lập danh sách khoảng 20-30 nguồn tin chất lượng cao nhất thuộc lĩnh vực của bạn. Lấy đường dẫn API hoặc RSS OPML feed tổng hợp từ các công cụ này. Bước 2: Thiết lập bộ lọc AI tự động (The Filtering & Summarization Layer) Bạn có thể sử dụng các nền tảng tự động hóa không code (No-code Automation) như Make.com hoặc Zapier, hoặc viết một script Python đơn giản chạy trên máy cá nhân: Kết nối trigger nhận bài viết mới từ RSS. Gửi tiêu đề và nội dung tóm tắt của bài viết sang API của OpenAI (GPT-4o mini) hoặc Gemini 1.5 Flash (hoặc chạy mô hình SLM cục bộ như Llama-3 8B để bảo mật dữ liệu tuyệt đối). Sử dụng Prompt hệ thống chuẩn hóa: "Bạn là trợ lý quản trị thông tin cá nhân. Hãy đánh giá độ liên quan của bài viết sau với hồ sơ quan tâm của tôi (độ liên quan từ 1 đến 10). Nếu độ liên quan lớn hơn hoặc bằng 8, hãy viết tóm tắt 3 dòng dưới dạng gạch đầu dòng. Nếu dưới 8, hãy bỏ qua bài viết." Bước 3: Kênh tiếp nhận tinh gọn (The Delivery Layer) Đầu ra của những bài viết đạt chất lượng (điểm liên quan >= 8) kèm bản tóm tắt gọn gàng của AI sẽ được tự động đẩy về một kênh tiếp nhận duy nhất do bạn chọn: một nhóm chat Telegram riêng tư, một máy chủ Discord cá nhân, hoặc tự động lưu vào trang cơ sở dữ liệu trên **Notion/Obsidian Dashboard** để bạn lưu trữ lâu dài. 5. Lời kết: Thiết lập "Chế độ ăn kiêng thông tin" lành mạnh Sức mạnh của tư duy không nằm ở việc bạn biết nhiều thông tin đến đâu, mà nằm ở việc bạn có khả năng lọc bỏ đi bao nhiêu thông tin không giá trị để giữ lại những hạt cát vàng tri thức thực sự sâu sắc. Quản trị thông tin cá nhân bằng RSS và AI không chỉ đơn giản là một mẹo công nghệ (productivity hack), nó là một kỹ năng sinh tồn thiết yếu trong kỷ nguyên số. Hãy giải phóng bộ não của bạn khỏi sự thao túng của các thuật toán mạng xã hội. Hãy trao quyền lọc tin tức cho AI Agent để bảo vệ sự tập trung sâu sắc của chính mình. Chỉ khi bạn làm chủ được nguồn dinh dưỡng tinh thần đi vào tâm trí mỗi ngày, bạn mới có thể bứt phá năng lực tư duy, sáng tạo ra những giá trị khác biệt và tiến xa hơn trên hành trình phát triển sự nghiệp bền vững.

Kỷ nguyên AI Agents trên thiết bị (On-Device Agents): Tự chủ bộ nhớ dài hạn và Triệt tiêu độ trễ
1. Sự chuyển dịch lịch sử từ Đám mây về Thiết bị phần cứng cục bộ Trong giai đoạn 2023 - 2025, thế giới công nghệ bị thống trị bởi các mô hình ngôn ngữ lớn (LLM) vận hành trên nền tảng điện toán đám mây khổng lồ như GPT-4 hay Gemini Pro. Người dùng đã quen với việc gửi các yêu cầu lên mây và chờ phản hồi. Tuy nhiên, bước sang năm 2026, một xu hướng công nghệ mang tính cách mạng đang định hình lại hoàn toàn cách chúng ta tương tác với trí tuệ nhân tạo: Kỷ nguyên của các Tác nhân AI trên thiết bị (On-Device AI Agents). Việc phụ thuộc hoàn toàn vào đám mây đang bộc lộ những giới hạn nghiêm trọng về bảo mật dữ liệu, chi phí vận hành API đắt đỏ và đặc biệt là **độ trễ đường truyền**. Để giải quyết triệt để bài toán này, các nhà sản xuất phần cứng và phần mềm toàn cầu đang ráo riết chuyển dịch trí thông minh nhân tạo trực tiếp về chip xử lý cục bộ trên laptop, điện thoại thông minh và các thiết bị IoT. Theo báo cáo dự báo mới nhất của Gartner công bố đầu năm 2026, **hơn 60% điện thoại thông minh cao cấp** bán ra trong năm nay và **45% số lượng máy tính cá nhân doanh nghiệp mới** sẽ được tích hợp sâu các mô hình ngôn ngữ nhỏ (Small Language Models - SLMs) có khả năng tự trị hoàn toàn trên thiết bị mà không cần kết nối Internet. AI giờ đây không còn là một dịch vụ web xa xôi, mà đã thực sự trở thành một thành phần bản địa gắn liền với phần cứng của bạn. 2. Triệt tiêu độ trễ: Sức mạnh bứt phá của NPU cục bộ so với API đám mây Độ trễ (Latency) chính là kẻ thù số một của trải nghiệm người dùng chuyên nghiệp và các tác vụ tự động hóa thời gian thực. Khi sử dụng các mô hình AI đám mây thông qua API, luồng dữ liệu phải trải qua hành trình phức tạp: mã hóa dữ liệu -> gửi qua internet lên server -> xếp hàng chờ xử lý -> LLM tính toán -> gửi phản hồi ngược lại thiết bị. Quy trình này thường tốn từ **1.5 đến 3 giây (1500ms - 3000ms)** cho mỗi lượt tương tác. Độ trễ vài giây này khiến việc xây dựng các trợ lý AI tương tác giọng nói thời gian thực hoặc các tác nhân tự trị liên tục (Continuous Agents) giám sát luồng công việc trở nên vô cùng chậm chạp và khó chịu. On-Device AI thay đổi cuộc chơi thế nào? Phản hồi siêu tốc dưới 100ms: Nhờ các chip xử lý AI chuyên dụng – **NPU (Neural Processing Unit)** đạt tiêu chuẩn hiệu năng trung bình từ **40 đến 50 TOPS** (Trillion Operations Per Second) trên các dòng máy tính AI PC năm 2026 – các mô hình ngôn ngữ nhỏ cục bộ có thể trả về câu trả lời gần như lập tức trong vòng **dưới 100ms** (tốc độ nhanh hơn gấp 20 đến 30 lần so với đám mây). Triệt tiêu chi phí API: Với các luồng công việc tự động hóa (Agentic Workflows) đòi hỏi hàng ngàn lượt gọi mô hình mỗi ngày, việc chạy cục bộ giúp doanh nghiệp tiết kiệm từ **70% đến 80% chi phí vận hành API** đám mây đắt đỏ. Hoạt động ngoại tuyến 100%: AI Agent trên thiết bị vận hành hoàn hảo ngay cả khi bạn đang ngồi trên máy bay, ở khu vực mất sóng hoặc trong các mạng nội bộ bảo mật cao cách ly hoàn toàn với Internet. 3. Tự chủ bộ nhớ dài hạn (Long-Term Memory): Chìa khóa tạo nên sự thấu hiểu cá nhân hóa Một AI Agent chạy trên thiết bị sẽ không bao giờ phát huy được tối đa sức mạnh nếu mỗi lần khởi động lại, nó đều quên đi bạn là ai và bạn đã làm gì. Để biến một mô hình ngôn ngữ nhỏ (SLM) cục bộ thành một cộng sự đắc lực thực thụ, công nghệ AI năm 2026 đã tích hợp cơ chế **Tự chủ bộ nhớ dài hạn (Long-Term Memory State Management)** ngay trên phần cứng cục bộ. Bộ nhớ dài hạn cục bộ được vận hành thông qua các cấu trúc kỹ thuật tiên tiến sau: Cơ sở dữ liệu Vector cục bộ (Local Vector Cache): Hệ thống tự động mã hóa lịch sử tương tác, thói quen viết code, phong cách viết email và các tài liệu cá nhân của bạn thành các vector nhúng và lưu trữ an toàn trong một Vector DB siêu nhẹ chạy cục bộ (như LanceDB hoặc SQLite với extension vector). Quản lý trạng thái ngữ cảnh (Context State Tracker): AI Agent liên tục cập nhật và duy trì trạng thái làm việc của người dùng thời gian thực. Khi bạn chuyển đổi giữa các tab công việc từ viết code, kiểm thử đến soạn thảo văn bản, AI Agent nắm giữ ngữ cảnh xuyên suốt để đưa ra các gợi ý chính xác tuyệt đối mà không cần người dùng phải giải thích lại từ đầu. Triệt tiêu rủi ro rò rỉ dữ liệu (Zero Data Leakage): Theo khảo sát thực tế, **hơn 75% doanh nghiệp** coi việc rò rỉ thông tin nội bộ khi nhân viên paste dữ liệu lên các Chatbot đám mây là mối nguy cơ an ninh hàng đầu. Với On-Device AI, mọi thông tin nhạy cảm, mã nguồn dự án hay báo cáo tài chính đều được xử lý vật lý 100% bên trong thiết bị của bạn, loại bỏ hoàn toàn nguy cơ bị bên thứ ba thu thập hoặc dùng để huấn luyện mô hình công cộng. 4. Kiến trúc phân lớp của một On-Device AI Agent hoàn chỉnh Để vận hành trơn tru một tác nhân thông minh ngay trên phần cứng cá nhân, các nhà phát triển đã xây dựng một kiến trúc phân lớp chuẩn hóa gồm 4 thành phần cốt lõi: Lớp Phần cứng (Hardware Layer): Nền tảng là chip NPU hiệu năng cao cùng cơ chế chia sẻ bộ nhớ thông minh (Unified Memory) giữa CPU, GPU và NPU, cho phép truy xuất trọng số mô hình với băng thông cực cao. Lớp Mô hình lõi (Model Layer): Sử dụng các mô hình ngôn ngữ nhỏ được tối ưu hóa cực đoan (như Llama 3.2 3B, Phi-3.5 Mini hay Gemma 2B) thông qua các kỹ thuật lượng tử hóa (Quantization) xuống mức 4-bit hoặc 8-bit để giảm dung lượng bộ nhớ RAM tiêu thụ xuống dưới 2GB - 3GB mà vẫn giữ nguyên **95% năng lực suy luận** so với mô hình gốc. Lớp Quản lý tri thức cục bộ (Local Knowledge Layer): Kết hợp công nghệ RAG cục bộ và Vector Cache để lưu trữ và truy xuất tức thì các tài liệu, sơ đồ dự án và thói quen cá nhân của người dùng. Lớp Tác nhân tự trị (Agentic Orchestrator): Bộ định tuyến logic nhận yêu cầu, tự động lập kế hoạch đa bước, gọi các công cụ phần mềm cục bộ (như trình duyệt web, terminal, file system) và giám sát kết quả thực thi thời gian thực dưới cơ chế bảo mật nghiêm ngặt của hệ điều hành. 5. Lời kết: Tương lai nằm trong tầm tay của bạn Kỷ nguyên AI Agents trên thiết bị đang mở ra một trang mới cho lịch sử điện toán cá nhân. Chúng ta đang dịch chuyển từ thời đại sử dụng các trợ lý AI đám mây chung chung sang thời đại sở hữu những "bộ não số" độc quyền, được cá nhân hóa sâu sắc, chạy trực tiếp trên thiết bị của mỗi cá nhân với độ bảo mật tuyệt đối và tốc độ phản hồi tức thì. Sự trưởng thành của các mô hình ngôn ngữ nhỏ (SLMs) kết hợp sức mạnh vượt trội của chip NPU thế hệ mới đã chính thức đập tan rào cản về độ trễ và chi phí vận hành. Tương lai của trí tuệ nhân tạo không còn nằm trên các đám mây xa xôi của các tập đoàn khổng lồ; tương lai đó đang vận hành lặng lẽ, an toàn và mạnh mẽ ngay trong chính chiếc laptop và điện thoại thông minh nằm trên bàn làm việc của bạn.

AI Việt Nam - khoảng cách giữa hào hứng bề nổi và chiều sâu công nghệ
1. Cơn sốt Trí tuệ nhân tạo tại Việt Nam: Sự hào hứng đến từ bề nổi Chưa bao giờ thuật ngữ AI (Trí tuệ nhân tạo) lại được nhắc đến nhiều như hiện nay trong cộng đồng công nghệ và giới doanh nghiệp Việt Nam. Từ các hội thảo quy mô lớn, các bài phát biểu chiến lược cho đến làn sóng khởi nghiệp (startups) công nghệ mới, AI được tôn vinh như chiếc chìa khóa vạn năng để mở cánh cửa chuyển đổi số và bứt phá năng suất. Cộng đồng công nghệ trong nước đang đón nhận làn sóng này với một sự hào hứng vô cùng lớn. Tuy nhiên, đằng sau bức tranh rực rỡ và những tuyên bố đầy tham vọng đó, các chuyên gia công nghệ hàng đầu thế giới đã đưa ra những cảnh báo vô cùng thẳng thắn về một thực trạng đáng suy ngẫm: **khoảng cách sâu sắc giữa sự hào hứng bề nổi và chiều sâu thực tế của công nghệ**. Phần lớn các hoạt động ứng dụng AI trong nước hiện nay vẫn chỉ dừng lại ở việc khai thác phần ngọn – tức là sử dụng các công cụ có sẵn hoặc đóng gói lại các mô hình nguồn mở của nước ngoài – mà hoàn toàn thiếu vắng các nghiên cứu nền tảng sâu sắc. Tại một diễn đàn công nghệ quốc tế diễn ra vào cuối tháng 5 năm 2026, **TS. Lương Minh Thắng**, Giám đốc nghiên cứu tại Google DeepMind kiêm đồng sáng lập NTI, đã thẳng thắn nhận định: "Cộng đồng công nghệ Việt Nam vô cùng hào hứng với AI, nhưng chúng ta đang thiếu đi chiều sâu cần thiết để tự chủ và bứt phá thực sự trên bản đồ công nghệ thế giới." Nhận định này đã chạm đúng vào điểm cốt lõi của bài toán phát triển AI bền vững tại Việt Nam. 2. Sự khác biệt giữa "Mì ăn liền" API Wrappers và Công nghệ lõi (Deep Tech) Để hiểu rõ khoảng cách mà TS. Lương Minh Thắng đề cập, chúng ta cần phân biệt rõ ràng hai hướng tiếp cận trong phát triển ứng dụng trí tuệ nhân tạo hiện nay: Hướng tiếp cận "API Wrappers" (Ứng dụng bề nổi): Đây là mô hình hoạt động của hơn 85% các dự án AI Startups tại Việt Nam hiện nay. Họ xây dựng ứng dụng bằng cách viết một giao diện người dùng đơn giản (wrapper) và gửi các câu lệnh (prompts) thông qua API kết nối trực tiếp đến các mô hình ngôn ngữ lớn (LLM) nước ngoài như OpenAI GPT-4, Google Gemini hay Anthropic Claude. Hướng đi này giúp sản phẩm ra mắt cực kỳ nhanh, nhưng doanh nghiệp hoàn toàn không làm chủ công nghệ lõi và rất dễ bị thay thế khi các nhà cung cấp API nâng cấp tính năng. Hướng tiếp cận "Deep Tech" (Công nghệ chuyên sâu): Đây là khâu nghiên cứu cơ bản, xây dựng các kiến trúc mô hình mới, tối ưu hóa thuật toán huấn luyện và phát triển các mô hình ngôn ngữ lớn (LLM) hoặc mô hình đa phương thức (Multimodal) chuyên biệt từ gốc. Hướng đi này đòi hỏi đầu tư R&D dài hạn cực kỳ tốn kém và nguồn nhân lực trình độ cao, nhưng lại chiếm chưa đầy **5%** số lượng doanh nghiệp công nghệ trong nước quan tâm đầu tư. Việc phụ thuộc hoàn toàn vào hạ tầng API nước ngoài khiến hệ sinh thái AI Việt Nam dễ bị tổn thương trước các thay đổi về mặt chính sách bảo mật dữ liệu, chủ quyền dữ liệu số và chi phí vận hành API đắt đỏ từ các tập đoàn Big Tech toàn cầu. 3. Ba nút thắt cổ chai cản bước AI Việt Nam tiến vào chiều sâu Theo phân tích của TS. Lương Minh Thắng và các chuyên gia công nghệ, sự thiếu hụt chiều sâu của AI Việt Nam xuất phát từ 3 nút thắt cổ chai cốt lõi cần phải tháo gỡ: 3.1. Rào cản nghiêm trọng về Hạ tầng tính toán (Infrastructure) Để huấn luyện các mô hình AI chuyên sâu, tài nguyên quan trọng nhất không phải là mã nguồn mà là **năng lực tính toán (compute power)**. Các phòng thí nghiệm quốc tế hàng đầu sở hữu các cụm siêu máy tính với hàng chục ngàn chip đồ họa NVIDIA H100 hoặc A100 có giá trị hàng triệu USD. Trong khi đó, tại Việt Nam, tổng năng lực tính toán của các phòng thí nghiệm nghiên cứu trong nước cộng lại vẫn chỉ đạt chưa đầy **5% đến 10%** công suất của một phòng nghiên cứu tầm trung ở thung lũng Silicon. Sự thiếu thốn phần cứng nghiêm trọng này khiến các kỹ sư trong nước hoàn toàn không có cơ hội thử nghiệm các mô hình lớn. 3.2. Sự thiếu vắng Nghiên cứu căn bản (Fundamental Research) Đa số các doanh nghiệp công nghệ trong nước chỉ tập trung vào việc tạo ra dòng tiền ngắn hạn, ngại đầu tư vào các nghiên cứu căn bản (fundamental research) vì thời gian thu hồi vốn lâu và rủi ro thất bại cao. Điều này khiến Việt Nam luôn ở vị thế "người theo sau", đi học hỏi và ứng dụng các công nghệ do nước ngoài phát minh ra thay vì tự mình kiến tạo các đột phá công nghệ mới. 3.3. Hệ sinh thái thiếu tính liên kết và tư duy dài hạn Mặc dù chúng ta có nhiều hội thảo bóng bẩy, nhưng hệ sinh thái AI trong nước vẫn còn khá phân mảnh. Sự liên kết giữa ba trụ cột: **Chính phủ (Chính sách) - Trường đại học (Nghiên cứu) - Doanh nghiệp (Thương mại hóa)** vẫn còn rất lỏng lẻo. Thiếu đi một cơ chế tài trợ nghiên cứu dài hạn, không có các sandbox thử nghiệm công nghệ đột phá khiến các ý tưởng nghiên cứu xuất sắc của sinh viên thường bị bỏ dở hoặc chỉ nằm trên giấy. 4. Con người: Lợi thế lớn nhất nhưng cũng là thách thức lớn nhất Mặc dù đối mặt với nhiều khó khăn, Việt Nam sở hữu một vũ khí cực kỳ mạnh mẽ mà mọi quốc gia phát triển đều thèm khát: **nguồn nhân tài toán học và lập trình xuất sắc**. Người Việt Nam rất thông minh, nhạy bén và có khả năng học hỏi công nghệ mới cực kỳ nhanh chóng. Rất nhiều nhà khoa học AI người Việt đang giữ các vị trí nghiên cứu cốt lõi tại các tập đoàn hàng đầu thế giới như Google DeepMind, OpenAI, Meta AI, hay giảng dạy tại các trường đại học danh tiếng như MIT, Stanford. Tuy nhiên, thách thức lớn nhất hiện nay là tình trạng **chảy máu chất xám (brain drain)**. Do môi trường trong nước thiếu thốn hạ tầng nghiên cứu chuyên sâu, thiếu các bài toán lớn xứng tầm và chế độ đãi ngộ chưa tương xứng, các nhân tài xuất sắc nhất thường chọn ở lại nước ngoài cống hiến. Việt Nam đang rơi vào tình thế đào tạo ra nhân tài nhưng lại không có "đất dụng võ" để họ đóng góp sâu rộng cho sự phát triển của nước nhà. Để giải quyết bài toán này, TS. Lương Minh Thắng đề xuất Việt Nam cần chuyển dịch mạnh mẽ từ tư duy "học hỏi, tiếp cận" sang tư duy "làm chủ công nghệ" trong vòng **5 đến 10 năm tới**. Chúng ta cần xây dựng các chính sách thu hút nhân tài thực chất, bắc những cây cầu tri thức để các chuyên gia quốc tế có thể tham gia vào việc tư vấn chính sách, thiết kế định hướng phát triển dài hạn và kết nối chuyển giao công nghệ lõi về nước. 5. Kết luận: Bước qua hào quang bề nổi để xây dựng tương lai bền vững Làn sóng hào hứng với AI tại Việt Nam là một tín hiệu vô cùng đáng mừng, tạo động lực tâm lý mạnh mẽ cho toàn xã hội. Nhưng nếu chỉ dừng lại ở sự hào hứng bề nổi đó, chúng ta sẽ nhanh chóng bị tụt hậu khi cơn sốt AI bão hòa và thế giới dịch chuyển sang các thế hệ AI tự trị chuyên sâu hơn. Đã đến lúc hệ sinh thái công nghệ Việt Nam phải bước qua những tiếng vỗ tay của các hội thảo bóng bẩy để bắt tay vào những hành động thực chất: Đầu tư bài bản vào giáo dục STEM dài hạn, xây dựng hạ tầng tính toán dùng chung ở cấp quốc gia, tài trợ cho các nhóm nghiên cứu công nghệ lõi (Deep Tech) và thiết lập cơ chế giữ chân nhân tài xuất sắc. Chỉ khi dám dấn thân vào chiều sâu công nghệ, dám đối mặt với các bài toán khó từ gốc rễ, AI Việt Nam mới có thể tự tin khẳng định vị thế chủ quyền công nghệ số và thực sự bứt phá vươn tầm thế giới.

Lịch công bố điểm thi, điểm chuẩn lớp 10 năm 2026 của các tỉnh, thành toàn quốc
1. Điểm nóng Tuyển sinh lớp 10 năm học 2026-2027 trên cả nước Kỳ thi tuyển sinh vào lớp 10 THPT công lập luôn được đánh giá là một trong những kỳ thi căng thẳng và có mức độ cạnh tranh gay gắt nhất trong hệ thống giáo dục Việt Nam, thậm chí vượt qua cả kỳ thi tốt nghiệp THPT quốc gia tại các thành phố lớn. Khi các phòng thi chính thức khép lại vào cuối tháng 5 và đầu tháng 6 năm 2026, sự lo âu của hàng triệu học sinh và phụ huynh lập tức đổ dồn về **lịch công bố điểm thi và điểm chuẩn tuyển sinh** của các địa phương. Để giúp các bậc phụ huynh và các em học sinh chủ động nắm bắt mốc thời gian quan trọng này nhằm chuẩn bị hồ sơ nhập học hoặc phúc khảo bài thi, chúng tôi đã tổng hợp chi tiết lịch công bố điểm thi tuyển sinh lớp 10 của các tỉnh, thành trên cả nước dựa trên kế hoạch chính thức từ các Sở Giáo dục và Đào tạo (GD&ĐT). Nhìn chung, công tác chấm thi đang được diễn ra khẩn trương với sự hỗ trợ của các công nghệ quét bài và nhập điểm số hóa, đảm bảo tính công bằng và chính xác tuyệt đối. "Theo quy định chung của Bộ Giáo dục và Đào tạo, toàn bộ các địa phương trên cả nước bắt buộc phải hoàn thành công tác chấm thi, công bố kết quả tuyển sinh đầu cấp trước ngày 31/7/2026 để chuẩn bị cho việc khai giảng năm học mới." 2. Tiến độ chấm thi và Lịch công bố điểm thi lớp 10 dự kiến Tiến độ công bố điểm thi phụ thuộc hoàn toàn vào lịch tổ chức thi của từng địa phương. Phần lớn các tỉnh, thành phố tổ chức thi vào đầu tháng 6 sẽ công bố kết quả thi vào **giữa và cuối tháng 6/2026**. Một số ít tỉnh tổ chức thi muộn hơn hoặc có số lượng thí sinh dự thi cực kỳ lớn (như Hà Nội) sẽ kéo dài tiến độ chấm thi đến **đầu hoặc giữa tháng 7/2026**. Nghệ An là địa phương dự kiến công bố điểm thi sớm nhất cả nước vào ngày **4/6/2026**, ngay sau đó là Quảng Trị (6/6) và Lai Châu (7/6). Trong khi đó, Hà Nội dự kiến sẽ công bố điểm thi chính thức trong khoảng từ ngày **19/6 đến 22/6/2026**. Sau khi biết điểm thi, Sở GD&ĐT các tỉnh sẽ tiến hành họp bàn, phê duyệt và công bố điểm chuẩn trúng tuyển vào các trường THPT không chuyên và THPT chuyên trong vòng từ 1 đến 3 ngày. 3. Bảng tổng hợp lịch công bố điểm thi của các tỉnh, thành phố tiêu biểu Dưới đây là bảng tổng hợp chi tiết lịch dự kiến công bố điểm thi tuyển sinh vào lớp 10 năm học 2026-2027 của 27 địa phương tiêu biểu cập nhật trực tiếp theo dữ liệu từ hệ thống Sở GD&ĐT tính đến ngày 28/5/2026: STT Tỉnh / Thành phố Thời gian công bố điểm thi (Dự kiến) 1 Nghệ An Ngày 04/06/2026 2 Quảng Trị Ngày 06/06/2026 3 Lai Châu Ngày 07/06/2026 4 Ninh Bình Chậm nhất ngày 08/06/2026 5 Hưng Yên Trước ngày 10/06/2026 6 Lào Cai Trước ngày 10/06/2026 7 Đà Nẵng Chậm nhất ngày 10/06/2026 8 Đồng Nai Ngày 10/06/2026 9 Hà Tĩnh Trước ngày 11/06/2026 10 Bắc Ninh Trước ngày 15/06/2026 11 Điện Biên Từ 16/06 đến 18/06/2026 12 Hà Nội Từ 19/06 đến 22/06/2026 13 Hải Phòng Chậm nhất ngày 19/06/2026 14 Quảng Ngãi Trước ngày 20/06/2026 15 Đắk Lắk Trước ngày 25/06/2026 16 Khánh Hòa Trước ngày 30/06/2026 17 Thái Nguyên Trước ngày 02/07/2026 18 Gia Lai Ngày 06/07/2026 19 Cà Mau Từ 06/07 đến 27/07/2026 20 Cần Thơ Từ 14/07 đến 17/07/2026 21 An Giang Ngày 18/07/2026 22 Tây Ninh Ngày 20/07/2026 23 Quảng Ninh Ngày 25/07/2026 24 Đồng Tháp Trước ngày 31/07/2026 25 Lâm Đồng Trước ngày 31/07/2026 26 Phú Thọ Trước ngày 31/07/2026 27 Thanh Hóa Trước ngày 31/07/2026 * Lưu ý: Lịch công bố điểm trên đây mang tính dự kiến và hoàn toàn có thể được điều chỉnh sớm hơn hoặc muộn hơn tùy theo tiến độ chấm bài thi thực tế của Hội đồng thi từng địa phương. Phụ huynh nên truy cập trực tiếp vào Cổng thông tin Sở GD&ĐT của địa phương mình để tra cứu kết quả nhanh nhất. 4. Hướng dẫn 3 cách tra cứu điểm thi lớp 10 nhanh và chính xác nhất Để tránh tình trạng nghẽn mạng do lượng truy cập tăng đột biến cùng một thời điểm, phụ huynh và học sinh có thể lưu lại 3 phương pháp tra cứu điểm chính thống sau: Cách 1: Tra cứu trực tuyến tại Cổng thông tin của Sở GD&ĐT Đây là phương thức chính xác tuyệt đối và hoàn toàn miễn phí. Người dùng truy cập trực tiếp vào website tra cứu điểm thi chính thức của Sở GD&ĐT tỉnh/thành phố nơi đăng ký dự thi (ví dụ: Hà Nội tra cứu tại tsdaucap.hanoi.gov.vn hoặc hanoi.edu.vn). Thí sinh tiến hành nhập chính xác Số báo danh (SBD) và mã xác nhận để hiển thị bảng điểm chi tiết các môn Toán, Văn, Ngoại ngữ và môn Chuyên (nếu có). Cách 2: Sử dụng các Cổng thông tin báo chí lớn và uy tín Các trang báo lớn như VnExpress, VTV News thường phối hợp với Sở GD&ĐT để mở trang tra cứu điểm thi lớp 10 miễn phí. Bạn chỉ cần truy cập chuyên mục Giáo dục của VnExpress, chọn Tỉnh/Thành và nhập SBD. Giao diện tối ưu hóa và máy chủ chịu tải tốt sẽ giúp kết quả trả về tức thì mà không lo bị nghẽn mạng. Cách 3: Gọi tổng đài giải đáp thông tin giáo dục Trong trường hợp không có kết nối internet hoặc website bị quá tải nghiêm trọng, phụ huynh có thể gọi điện trực tiếp đến các tổng đài giải đáp thông tin tuyển sinh bằng cách bấm: [Mã vùng tỉnh] + 1080 hoặc [Mã vùng tỉnh] + 80115678 để được các điện thoại viên hỗ trợ đọc điểm thi trực tiếp. 5. Những mốc thời gian quan trọng sau khi biết điểm thi học sinh cần lưu ý Sau khi có điểm thi, hành trình tuyển sinh lớp 10 vẫn chưa khép lại. Phụ huynh và học sinh cần ghi nhớ các cột mốc cực kỳ quan trọng sau để tránh bỏ lỡ cơ hội trúng tuyển đáng tiếc: Thời hạn nộp đơn phúc khảo: Thông thường, các Sở GD&ĐT sẽ tiếp nhận đơn xin phúc khảo bài thi trong vòng từ **3 đến 5 ngày** kể từ ngày công bố điểm thi. Nếu nhận thấy điểm số nhận về chênh lệch nhiều so với tự chấm thi, học sinh nên nhanh chóng làm đơn nộp tại trường THCS nơi học lớp 9. Công bố điểm chuẩn chính thức: Điểm chuẩn trúng tuyển thường được Sở GD&ĐT công bố sau khi công bố điểm thi từ 2 đến 5 ngày. Học sinh cần đối chiếu chính xác điểm xét tuyển (đã cộng điểm ưu tiên) của mình với điểm chuẩn của các nguyện vọng đăng ký. Hoàn tất thủ tục xác nhận nhập học: Đây là bước bắt buộc. Học sinh trúng tuyển phải thực hiện xác nhận nhập học (trực tuyến hoặc trực tiếp tại trường THPT trúng tuyển) trong thời hạn quy định (thường từ 3 đến 7 ngày). **Quá thời hạn quy định, học sinh không xác nhận nhập học sẽ bị coi như từ bỏ quyền trúng tuyển** và trường sẽ dành chỉ tiêu cho các thí sinh đợt bổ sung hoặc năm sau. Kỳ thi tuyển sinh lớp 10 là một dấu mốc trưởng thành quan trọng đầu tiên của các em học sinh. Chúc tất cả các sĩ tử trên khắp 34 tỉnh, thành đạt được kết quả như ý nguyện và trúng tuyển vào ngôi trường THPT mong ước!

Bí quyết chuyển hóa Tiếng Anh từ 'nghe hiểu thụ động' sang 'giao tiếp phản xạ chuyên nghiệp' trong 3 tháng nhờ kỹ thuật Shadowing và AI Feedback
1. Bẫy tư duy của việc "Nghe hiểu thụ động" và Lối thoát cho người học Tiếng Anh Một trong những nghịch lý phổ biến nhất của người học tiếng Anh tại Việt Nam chính là: nghe hiểu rất tốt, đọc tài liệu chuyên ngành trôi chảy nhưng hoàn toàn bất lực khi phải mở miệng giao tiếp. Khi đối mặt với người nước ngoài hoặc tham gia các cuộc họp quốc tế, bộ não của họ rơi vào trạng thái đóng băng, vắt óc dịch từng từ từ tiếng Việt sang tiếng Anh, lo sợ sai ngữ pháp và cuối cùng chỉ có thể trả lời bằng những câu từ vụn vặt. Họ rơi vào chiếc bẫy mang tên "Nghe hiểu thụ động" (Passive Comprehension). Nhiều người tin rằng chỉ cần nghe podcast thụ động khi ngủ, xem phim có phụ đề hay nghe nhạc tiếng Anh thật nhiều là tự động có thể nói giỏi. Tuy nhiên, nghiên cứu khoa học thần kinh chỉ ra rằng, việc nghe hiểu thụ động chỉ kích hoạt **Vùng Wernicke** trong não bộ (chịu trách nhiệm giải mã ngôn ngữ đầu vào), nhưng hoàn toàn bỏ quên **Vùng Broca** (chịu trách nhiệm điều khiển các cơ quan phát âm để sản xuất ngôn ngữ đầu ra). Theo báo cáo thống kê nghiên cứu phương pháp giảng dạy ngôn ngữ của British Council và Cambridge English, một người học trung bình cần tới hơn 1,200 giờ nghe thụ động để có thể đạt được khả năng phản xạ nói tự nhiên ở mức B2/C1. Trong khi đó, nếu sử dụng các kỹ thuật kích hoạt cơ phát âm chủ động như **Shadowing** kết hợp với hệ thống **AI Feedback (Phản hồi từ trí tuệ nhân tạo)**, thời gian này có thể được tối ưu hóa nén gọn lại chỉ dưới **360 giờ** – tức là tiết kiệm tới hơn 3 lần thời gian và năng lượng học tập. 2. Kỹ thuật Shadowing: Kích hoạt vùng cơ Broca và Xây dựng Muscle Memory Được phát triển bởi giáo sư ngôn ngữ nổi tiếng Alexander Arguelles, **Shadowing (Nói đuổi)** là kỹ thuật bắt chước gần như đồng thời (chậm hơn chỉ khoảng 0.5 đến 1 giây) theo giọng nói của người bản xứ. Người học không đợi nghe hết cả câu rồi mới lặp lại, mà phải nói "đuổi theo" người nói ngay khi họ đang phát âm, bắt chước chính xác từ ngữ điệu, cách nhấn âm, nối âm cho đến nhịp điệu của câu. Tại sao Shadowing lại mang lại hiệu quả vượt trội đến vậy? Chuyển hóa tri thức từ thụ động sang chủ động: Khi nghe thụ động, não bộ của chúng ta chỉ lưu giữ được tối đa khoảng **20%** các cấu trúc câu và từ vựng. Tuy nhiên, việc ép các cơ quan phát âm (lưỡi, môi, hàm) hoạt động liên tục thông qua Shadowing giúp nâng tỷ lệ ghi nhớ và phản xạ tự nhiên của não bộ lên tới **75% - 85%** nhờ việc xây dựng **Trí nhớ cơ bắp (Muscle Memory)**. Triệt tiêu thói quen dịch nhẩm: Do tốc độ nói đuổi cực kỳ nhanh, bộ não của bạn không có thời gian để thực hiện quy trình dịch nhẩm từ Việt sang Anh. Điều này buộc não bộ phải hình thành các liên kết neuron trực tiếp giữa ý nghĩ và ngôn ngữ nói tiếng Anh, giúp hình thành phản xạ giao tiếp tự nhiên. Chỉnh sửa ngữ điệu bản xứ tự động: Việc liên tục nói đè lên giọng người bản xứ tạo ra một cơ chế tự so sánh và điều chỉnh (self-correction) trong tai người học, giúp giọng nói của bạn tự động có ngữ điệu trầm bổng, ngắt nghỉ tự nhiên như người bản xứ. Để đạt hiệu quả tối đa, bạn nên bắt đầu với các đoạn hội thoại ngắn, có phụ đề (transcript), nói với tốc độ vừa phải (khoảng 100 - 120 từ/phút) và tăng dần độ khó theo thời gian. 3. AI Feedback: Người thầy tư nhân thông minh sửa lỗi phát âm tức thì Điểm yếu lớn nhất của việc tự học Shadowing truyền thống là bạn **không biết mình phát âm sai ở đâu**. Nếu bạn phát âm sai một từ lặp đi lặp lại nhiều lần mà không được sửa đổi, não bộ sẽ ghi nhận sai lầm đó thành thói quen lâu dài (fossilization) cực kỳ khó sửa. Sự trỗi dậy của công nghệ trí tuệ nhân tạo vào năm 2026 đã giải quyết triệt để bài toán này thông qua hệ thống **AI Feedback (Phản hồi phát âm thời gian thực)**. Sử dụng các mô hình nhận dạng giọng nói nâng cao (như OpenAI Whisper), AI giờ đây có khả năng phân tích giọng nói của bạn với những thông số kỹ thuật chuẩn xác: "Các mô hình AI Feedback thế hệ mới sở hữu tỷ lệ lỗi từ (Word Error Rate - WER) cực thấp chỉ dưới 3% - 5%, tương đương với năng lực thẩm âm của các giáo viên bản xứ chuyên nghiệp, nhưng trả về kết quả sửa lỗi chi tiết chỉ trong vòng 2 giây với mức chi phí chỉ bằng 1/10." Hệ thống AI Feedback cung cấp các chỉ số đánh giá toàn diện giúp người học tiến bộ vượt bậc: Độ chính xác âm đơn (Pronunciation Accuracy): Phát hiện chính xác bạn đang bị mất âm đuôi (ending sounds) nào (như /s/, /t/, /d/), hoặc phát hiện các lỗi phát âm sai nguyên âm phổ biến. Nhịp điệu và Trọng âm (Fluency & Word Stress): Chỉ ra bạn đã nhấn đúng trọng âm của từ hay chưa, và liệu ngữ điệu câu có tự nhiên hay đang bị đều đều (monotone). Độ lưu loát (Speech Rate): Đo lường tốc độ nói của bạn (words per minute) để đảm bảo bạn không nói quá nhanh dẫn đến nuốt chữ, hoặc nói quá chậm gây cảm giác ngập ngừng. Sự kết hợp giữa Shadowing (luyện tập đầu ra) và AI Feedback (đo lường và sửa sai) tạo nên một **vòng lặp phản hồi tích cực (positive feedback loop)** cực kỳ mạnh mẽ, giúp người học tiến bộ thần tốc sau từng ngày luyện tập. 4. Lộ trình 3 tháng (90 ngày) bứt phá phản xạ giao tiếp chuyên nghiệp Chỉ cần cam kết dành ra từ **30 đến 45 phút mỗi ngày**, lộ trình 90 ngày được thiết kế khoa học dưới đây sẽ giúp bạn lột xác hoàn toàn khả năng giao tiếp tiếng Anh: Tháng 1 (Ngày 1 - 30): Kích hoạt vùng cơ Broca và Chuẩn hóa Ngữ âm Dành 100% sự tập trung vào việc chuẩn hóa các âm tiết cơ bản trong tiếng Anh (IPA) và luyện Shadowing ở mức độ chậm. Mục tiêu lớn nhất của giai đoạn này là giúp các cơ quan phát âm (lưỡi, môi) quen với việc uốn dẻo theo các luồng hơi tiếng Anh. Sử dụng các app AI Feedback hàng ngày để sửa triệt để các lỗi phát âm sai của từng từ đơn lẻ. Thời lượng: 30 phút Shadowing + 10 phút AI Feedback. Tháng 2 (Ngày 31 - 60): Làm quen với tốc độ tự nhiên và Cụm từ (Chunking) Chuyển sang Shadowing các đoạn hội thoại có tốc độ tự nhiên của người bản xứ (140 - 160 từ/phút). Tập trung vào kỹ thuật **Chunking (Ngắt cụm nghĩa)** – tức là học cách dừng nghỉ đúng chỗ theo cụm từ thay vì đọc từng từ rời rạc. Tập trung bắt chước các hiện tượng nuốt âm, nối âm (linking sounds) và giảm âm (weak forms). Sử dụng AI để đánh giá độ lưu loát (Fluency Score) của cả đoạn hội thoại dài. Tháng 3 (Ngày 61 - 90): Tự do ngôn luận và Phản xạ Spontaneous Giai đoạn này, bạn sẽ gập transcript lại. Thực hiện Shadowing hoàn toàn bằng tai (Blind Shadowing) – chỉ nghe và lặp lại ngay lập tức mà không nhìn chữ. Đồng thời, áp dụng phương pháp tự trò chuyện với AI đối thoại (AI Voice Assistants) theo các chủ đề công việc thực tế (như phỏng vấn xin việc, thuyết trình dự án, thương lượng giá cả). AI sẽ cung cấp các phản hồi về ngữ pháp và từ vựng thay thế chuyên nghiệp hơn để bạn hoàn thiện phong cách giao tiếp. 5. Lời kết: Kiên trì là chìa khóa mở cánh cửa tự tin toàn cầu Sự khác biệt lớn nhất giữa một người nói tiếng Anh trôi chảy và một người mãi mãi dừng lại ở mức nghe hiểu thụ động không nằm ở năng khiếu bẩm sinh, mà nằm ở sự kiên trì luyện tập đầu ra chủ động hàng ngày. Kỹ thuật Shadowing có thể khiến bạn cảm thấy mệt mỏi và đau cơ miệng trong vài tuần đầu tiên – đó là dấu hiệu tốt cho thấy vùng não bộ Broca của bạn đang tái cấu trúc vật lý để thích nghi với một ngôn ngữ mới. Hãy ngừng việc nghe thụ động vô ích. Hãy bắt đầu ngay hôm nay bằng cách mở một đoạn hội thoại bản xứ, mở mic lên, nói đuổi theo họ và để AI chỉ ra cho bạn những điểm cần hoàn thiện. Sau 3 tháng kiên trì bền bỉ, bạn sẽ tự tin bước vào mọi phòng họp quốc tế với một phong thái giao tiếp phản xạ tiếng Anh chuyên nghiệp, tự nhiên và đầy bản lĩnh.

Công nghệ AI định hình World Cup 2026: Giải đấu thông minh nhất lịch sử
1. Kỷ nguyên mới của Bóng đá: Sự giao thoa giữa Thể thao và Trí tuệ nhân tạo World Cup 2026 đánh dấu một cột mốc lịch sử chưa từng có của ngày hội bóng đá lớn nhất hành tinh. Không chỉ là giải đấu đầu tiên mở rộng quy mô lên tới **48 đội bóng** tham dự, tổ chức tại **16 sân vận động** thuộc **3 quốc gia** đồng chủ nhà (Mỹ, Canada và Mexico), World Cup 2026 còn chính thức ghi nhận bước chuyển mình vĩ đại: trở thành giải đấu được định hình sâu sắc và toàn diện nhất bởi Trí tuệ nhân tạo (AI) trong lịch sử thể thao nhân loại. Với sự hợp tác công nghệ chiến lược cùng đối tác chính thức Lenovo, FIFA đã đưa AI len lỏi vào từng khía cạnh của giải đấu: từ việc hỗ trợ ban huấn luyện phân tích chiến thuật, giúp các trọng tài ra quyết định chính xác tuyệt đối, cho đến việc tối ưu hóa luồng giao thông đám đông và cá nhân hóa trải nghiệm xem của hàng tỷ người hâm mộ trên khắp thế giới. Sự xuất hiện của AI không còn là những thử nghiệm quảng cáo, mà đã thực sự trở thành "bộ não" trung tâm định vị tiêu chuẩn mới cho thể thao chuyên nghiệp thế hệ mới. "Công nghệ AI tại World Cup 2026 không chỉ làm tăng tính hấp dẫn của trận đấu, mà quan trọng hơn là kiến tạo một môi trường cạnh tranh công bằng, minh bạch và an toàn tuyệt đối cho mọi đội bóng và khán giả tham gia." 2. Football AI Pro: Dân chủ hóa dữ liệu và Cách mạng hóa chiến thuật Lần đầu tiên trong lịch sử bóng đá thế giới, FIFA cung cấp một nền tảng phân tích dữ liệu chuyên sâu ứng dụng AI mang tên Football AI Pro cho toàn bộ 48 đội tuyển tham dự, không phân biệt quốc gia lớn hay nhỏ. Bước đi mang tính cách mạng này đã giúp xóa bỏ khoảng cách về tài nguyên công nghệ, tạo nên một sân chơi công bằng thực sự giữa các đội bóng nghèo và các siêu thế lực bóng đá thế giới. Hệ thống Football AI Pro sở hữu những năng lực tính toán vượt trội định hình lại hoàn toàn công tác huấn luyện: Xử lý hàng trăm triệu điểm dữ liệu thời gian thực: Trong mỗi giây của trận đấu, AI phân tích song song luồng di chuyển của toàn bộ cầu thủ và bóng, theo dõi hơn 2,000 chỉ số chuyên môn chi tiết bao gồm: cự ly đội hình, áp lực pressing, tốc độ chuyển đổi trạng thái (transition) và hướng chuyền bóng khả thi. Mô phỏng chiến thuật 3D trực quan: Ban huấn luyện có thể kiểm thử các phương án thay đổi nhân sự ngay trên tablet thông qua các mô hình giả lập 3D do AI dự đoán kết quả dựa trên dữ liệu thi đấu lịch sử của đối thủ. Cá nhân hóa báo cáo hiệu năng: Ngay sau khi tiếng còi kết thúc trận đấu vang lên, hệ thống sẽ tự động tổng hợp và gửi báo cáo phân tích chi tiết về điểm mạnh, điểm yếu và các tình huống cần cải thiện riêng biệt cho từng cầu thủ qua ứng dụng nội bộ. Nhờ Football AI Pro, các đội tuyển được đánh giá thấp hơn có thể nhanh chóng bóc tách lối chơi của đối phương, thiết lập các khối phòng ngự khoa học và khai thác chính xác các kẽ hở chiến thuật dựa trên số liệu thực chứng thay vì chỉ dựa vào cảm tính của con người. 3. Avatar 3D và Công nghệ việt vị bán tự động SAOT thế hệ mới Một trong những điểm đen lớn nhất của bóng đá thế giới là những tranh cãi không ngớt xung quanh các quyết định việt vị của trọng tài, ngay cả khi có sự hỗ trợ của công nghệ VAR đời đầu. Tại World Cup 2026, FIFA đã nâng cấp toàn diện hệ thống **Việt vị bán tự động (Semi-Automated Offside Technology - SAOT)** kết hợp với công nghệ **quét Avatar 3D cầu thủ** cực kỳ chính xác. Cách thức vận hành và các con số ấn tượng của hệ thống SAOT nâng cao: Quét kỹ thuật số siêu tốc trong 1 giây: Trước giải đấu, mọi cầu thủ đều được quét kỹ thuật số toàn thân để xây dựng một mô hình Avatar 3D chính xác đến từng khớp xương. Hệ thống camera chuyên dụng trên sân có thể xác định chính xác vị trí của 29 điểm dữ liệu cơ thể cầu thủ với tần số quét 50 lần mỗi giây. Giảm 85% thời gian ra quyết định: Thay vì bắt trọng tài VAR phải kẻ các đường thẳng thủ công mất từ 2 đến 3 phút, AI của SAOT tự động xác định thời điểm bóng rời chân người chuyền và vị trí của cầu thủ nhận bóng, đưa ra cảnh báo việt vị chính xác trong vòng **dưới 15 giây** (giảm 85% thời gian chờ đợi). Trực quan hóa 3D cho khán giả truyền hình: Ngay sau khi trọng tài đưa ra quyết định, hệ thống tự động sinh một video mô phỏng 3D thể hiện góc nhìn chính diện của tình huống việt vị và phát sóng trực tiếp cho hàng triệu khán giả truyền hình, loại bỏ hoàn toàn mọi sự mơ hồ và hoài nghi. Bên cạnh đó, việc tích hợp góc quay **"Referee View"** ứng dụng thuật toán ổn định hình ảnh bằng AI cho phép người xem trải nghiệm trận đấu thông qua góc nhìn chân thực của chính trọng tài trên sân, tăng cường tối đa tính kết nối cảm xúc giữa khán giả và giải đấu. 4. Digital Twins và Vận hành sân vận động thông minh Với 48 đội tuyển và dự kiến hàng triệu cổ động viên đổ về 16 thành phố chủ nhà trên khắp Bắc Mỹ, bài toán an ninh, logistics và quản lý đám đông là một thách thức cực kỳ khủng khiếp đối với Ban tổ chức World Cup 2026. Để giải quyết vấn đề này, các kỹ sư công nghệ đã xây dựng hệ thống **Bản sao kỹ thuật số (Digital Twins)** của toàn bộ các sân vận động lớn. Hệ thống vận hành thông minh này mang lại những hiệu quả thực chứng vượt trội: Trung tâm chỉ huy thông minh thời gian thực: AI liên tục thu thập dữ liệu từ hàng ngàn camera an ninh, thiết bị cảm biến nhiệt độ và các luồng thông tin giao thông để vẽ nên một bức tranh toàn cảnh sống động về luồng di chuyển của hàng vạn khán giả. Dự báo nguy cơ mất an toàn trước 10 phút: Thuật toán AI có thể phân tích mật độ đám đông và dự báo các khu vực có nguy cơ ùn tắc nghiêm trọng hoặc mất kiểm soát an ninh trước **10 phút** khi sự việc thực tế xảy ra, cho phép lực lượng điều phối can thiệp kịp thời. Tối ưu hóa năng lượng và phát thải: Việc quản lý hệ thống chiếu sáng, điều hòa không khí tại các siêu sân vận động (như sân vận động MetLife hay Azteca) bằng AI giúp cắt giảm trung bình **25% lượng điện năng tiêu thụ**, trực tiếp đóng góp vào mục tiêu tổ chức một kỳ World Cup xanh, thân thiện với môi trường của FIFA. 5. Kỷ nguyên của Trải nghiệm Bóng đá Số hóa và Cá nhân hóa World Cup 2026 không chỉ diễn ra trên sân cỏ Bắc Mỹ, nó diễn ra trên màn hình thiết bị di động của hàng tỷ người hâm mộ khắp hành tinh. Việc ứng dụng Generative AI (như các mô hình ngôn ngữ lớn Google Gemini) đã cho phép các đội tuyển lớn (như Argentina) tạo ra các cổng thông tin tương tác thông minh cho người hâm mộ. Cổ động viên có thể trò chuyện với các trợ lý AI để hỏi đáp lịch sử đội bóng, dịch thuật trực tiếp ngôn ngữ tại nước chủ nhà và thậm chí tự tạo ra các hình ảnh, video cổ vũ độc quyền mang đậm dấu ấn cá nhân để chia sẻ lên mạng xã hội. Tóm lại, World Cup 2026 là minh chứng rõ nét nhất cho thấy Trí tuệ nhân tạo đã vượt ra ngoài ranh giới của các phòng thí nghiệm để bước vào và làm thay đổi hoàn toàn bộ mặt của môn thể thao vua. AI không làm mất đi tính nhân văn hay cảm xúc tự nhiên của bóng đá; ngược lại, nó đóng vai trò là một bệ đỡ công nghệ vững chắc, giúp các trận đấu diễn ra nhanh hơn, chính xác hơn, công bằng hơn và đưa hàng triệu con tim yêu bóng đá xích lại gần nhau hơn trong một kỷ nguyên số hóa toàn diện.

Phương pháp học siêu tốc (Ultralearning): Cách chinh phục một kỹ năng lập trình khó trong 100 giờ với Active Recall và Spaced Repetition
1. Cơn ác mộng "Địa ngục hướng dẫn" (Tutorial Hell) và Giải pháp Ultralearning Trong kỷ nguyên số bùng nổ năm 2026, ngành phát triển phần mềm liên tục chứng kiến sự ra đời của các framework, thư viện và kiến trúc mới. Đối với các lập trình viên, việc phải liên tục học hỏi các kỹ năng mới không còn là lựa chọn mà là sinh mệnh nghề nghiệp. Tuy nhiên, hầu hết chúng ta đều rơi vào một chiếc bẫy tâm lý phổ biến mang tên: "Địa ngục hướng dẫn" (Tutorial Hell). Lập trình viên dành hàng chục giờ đồng hồ thụ động xem các video khóa học trên Udemy, YouTube hay đọc các tài liệu dài dằng dặc, gật gù tâm đắc vì cảm thấy mình đã hiểu hoàn toàn. Nhưng ngay khi tắt video đi, đối mặt với một màn hình code trống không (blank editor), họ hoàn toàn đóng băng và không biết gõ dòng code đầu tiên thế nào. Đây là hội chứng "Ảo tưởng về năng lực" (Illusion of Competence), khi não bộ nhầm lẫn giữa khả năng "nhận diện thông tin" (recognition) với khả năng "tự tái tạo tri thức" (recall). Để đập tan giới hạn này, phương pháp **Ultralearning (Học siêu tốc)** – được phổ biến bởi tác giả Scott Young qua thử thách hoàn thành chương trình khoa học máy tính 4 năm của MIT chỉ trong vòng 12 tháng – đã trở thành kim chỉ nam cho giới công nghệ. Bằng việc kết hợp hai cơ chế khoa học não bộ cốt lõi là **Active Recall (Chủ động truy xuất)** và **Spaced Repetition (Lặp lại ngắt quãng)**, bạn hoàn toàn có thể làm chủ một kỹ năng lập trình khó (như lập trình bất đồng bộ nâng cao, viết REST API phức tạp, hay tối ưu hóa truy vấn Database) chỉ trong vòng **100 giờ thực chiến** có chủ đích. 2. Trụ cột 1: Active Recall - Ép não bộ truy xuất thông tin thay vì nạp thụ động Active Recall là kỹ thuật ép buộc não bộ phải chủ động lục tìm và tái tạo lại thông tin từ sâu trong bộ nhớ mà không nhìn vào tài liệu tham khảo. Phương pháp học truyền thống (đọc lại code cũ, xem video hướng dẫn) là phương pháp nạp thụ động (passive review). Nghiên cứu khoa học thần kinh chỉ ra rằng, não bộ chỉ thực sự hình thành các kết nối neuron bền vững khi nó phải nỗ lực truy xuất dữ liệu ra ngoài chứ không phải khi nạp thông tin vào. Một nghiên cứu thực nghiệm mang tính bước ngoặt của hai nhà khoa học **Karpicke & Blunt (2011)** được xuất bản trên tạp chí uy tín hàng đầu thế giới Science đã chứng minh sức mạnh của phương pháp này. Họ chia các sinh viên thành nhiều nhóm học tập bằng các cách khác nhau. Kết quả cho thấy nhóm sinh viên sử dụng phương pháp **Active Recall (Retrieval Practice)** đạt điểm số kiểm tra khái niệm cao hơn tới **50%** so với nhóm sinh viên học bằng phương pháp đọc lại tài liệu thụ động nhiều lần (rereading), bất chấp việc nhóm đọc lại dành nhiều thời gian học tập hơn. Áp dụng Active Recall vào việc học lập trình thế nào để bứt phá? Phương pháp "Đóng sách gõ code" (Close the book and code): Sau khi đọc hiểu một thuật toán hoặc xem hướng dẫn xây dựng một chức năng phần mềm, hãy ngay lập tức tắt tài liệu đi. Tự mình gõ lại toàn bộ đoạn code đó từ bộ nhớ của mình. Nếu gặp lỗi, hãy cố gắng tự gỡ lỗi (debug) trước khi mở tài liệu ra xem lại phần bị quên. Feynman Technique ứng dụng: Hãy thử tự giải thích cơ chế hoạt động của một dòng code phức tạp (ví dụ: Closure trong Javascript hay Decorator trong Python) cho một lập trình viên ảo hoặc một chú vịt cao su (Rubber Duck Debugging) bằng ngôn ngữ giản dị nhất. Nếu bạn vấp ở đoạn nào, đó chính là lỗ hổng tri thức bạn cần vá ngay lập tức. Đặt câu hỏi trước khi học: Trước khi đọc một chương tài liệu kỹ thuật, hãy đọc các câu hỏi ôn tập hoặc tự dự đoán xem công nghệ này giải quyết bài toán gì. Việc tạo ra các "móc treo câu hỏi" giúp não bộ chủ động neo đậu thông tin hiệu quả hơn. 3. Trụ cột 2: Spaced Repetition - Bẻ gãy đường cong quên lãng của Ebbinghaus Lý do lớn nhất khiến chúng ta học lập trình trước quên sau là do cơ chế sinh học tự nhiên của não bộ để tránh quá tải thông tin. Nhà tâm lý học người Đức **Hermann Ebbinghaus** đã chứng minh điều này qua nghiên cứu nổi tiếng về **Đường cong quên lãng (Forgetting Curve)**. Theo số liệu thực nghiệm của ông: "Không có sự củng cố chủ động, một người bình thường sẽ quên đi khoảng 50% thông tin mới chỉ sau 1 giờ, 70% sau 24 giờ và tới hơn 80% sau 30 ngày." Để bẻ gãy đường cong dốc đứng này, chúng ta cần áp dụng kỹ thuật **Spaced Repetition (Lặp lại ngắt quãng)**. Bằng cách ôn tập lại kiến thức vào đúng thời điểm chuẩn bị quên, bạn sẽ reset lại đường cong quên lãng và giúp thông tin di chuyển dần từ trí nhớ ngắn hạn sang **trí nhớ dài hạn vĩnh viễn**. Nghiên cứu của giáo sư Harry Bahrick về trí nhớ dài hạn đã chứng minh việc giãn cách các chu kỳ ôn tập một cách thông minh có thể giúp tăng hiệu quả ghi nhớ lâu dài lên từ **200% đến 300%** so với việc nhồi nhét học liên tục (cramming) trong cùng một tổng quỹ thời gian học tập. Quy trình triển khai Spaced Repetition tối ưu cho lập trình viên: Xây dựng bộ thẻ ghi nhớ (Flashcards) kỹ thuật: Sử dụng phần mềm Anki để tạo ra các thẻ ghi nhớ dạng câu hỏi/trả lời. Mặt trước chứa câu hỏi cốt lõi (ví dụ: "Cách khai báo một Generic Class trong TypeScript?"), mặt sau chứa đoạn code chuẩn tối giản. Thiết lập chu kỳ ôn tập ngắt quãng: Luyện tập gõ lại đoạn code cốt lõi hoặc giải nghĩa các nguyên lý lập trình theo chu kỳ giãn cách: **1 ngày -> 3 ngày -> 7 ngày -> 14 ngày -> 30 ngày**. Anki sẽ tự động sử dụng thuật toán SM-2 để tính toán và nhắc nhở bạn ôn tập chính xác vào ngày bộ não sắp sửa quên kiến thức đó. Dự án mini lặp lại: Đừng chỉ ôn tập lý thuyết suông. Hãy lập kế hoạch viết lại một dự án siêu nhỏ (ví dụ: To-Do App có kết nối database) 3 lần, mỗi lần cách nhau 1 tuần. Lần thứ nhất bạn nhìn tài liệu, lần thứ hai chỉ nhìn sơ đồ, lần thứ ba hoàn toàn code chay từ bộ nhớ. 4. Lộ trình 100 giờ thực chiến: Từ con số 0 đến làm chủ kỹ năng khó Malcolm Gladwell từng đưa ra quy tắc 10,000 giờ để trở thành chuyên gia xuất chúng. Tuy nhiên, nghiên cứu của giáo sư Anders Ericsson về "Luyện tập có chủ đích" (Deliberate Practice) chỉ ra rằng chất lượng luyện tập quan trọng hơn số lượng giờ học rất nhiều. Tác giả Josh Kaufman cũng chứng minh chỉ cần **20 giờ** luyện tập tập trung cao độ là bạn đã vượt qua rào cản ban đầu để sử dụng được kỹ năng. Và nếu bạn đầu tư **100 giờ học tập siêu tốc (Ultralearning)** có cấu trúc khoa học, bạn sẽ lọt vào nhóm **25% chuyên gia xuất sắc nhất** trong phân khúc kỹ năng đó. Dưới đây là sơ đồ lộ trình phân bổ 100 giờ thực chiến được thiết kế hoàn hảo cho lập trình viên: Giai đoạn 1: Metalearning - Học cách học (Giờ 1 - 10) Dành 10% quỹ thời gian để nghiên cứu bản đồ kỹ năng. Hãy trả lời 3 câu hỏi: **Tại sao học? Học cái gì? Học như thế nào?** Tải về các mã nguồn chuẩn, tìm kiếm các lộ trình uy tín và chia nhỏ kỹ năng lớn thành các phần siêu nhỏ. Ví dụ: Thay vì nói học "Backend", hãy đặt mục tiêu cụ thể là "Làm chủ REST API với Node.js/Express và PostgreSQL trong 100 giờ". Giai đoạn 2: Tiếp thu lý thuyết tối thiểu - Minimal Theory (Giờ 11 - 30) Sai lầm lớn nhất là đọc sách lý thuyết quá lâu. Hãy chỉ học lượng lý thuyết tối thiểu vừa đủ để bắt tay vào làm việc. Áp dụng quy tắc **20/80**: 20% kiến thức cốt lõi sẽ giải quyết 80% công việc thực tế. Ngay lập tức tạo ra các thẻ flashcard Anki đầu tiên để ghi nhớ cú pháp và các khái niệm nền tảng bằng Active Recall. Giai đoạn 3: Thực hành có chủ đích qua dự án - Active Projects (Giờ 31 - 75) Đây là giai đoạn tốn năng lượng nhất, chiếm 45% tổng thời gian. Bạn sẽ tự tay xây dựng 2-3 dự án thực tế có độ khó tăng dần từ đầu đến cuối mà không có sự trợ giúp trực tiếp của các tutorial từng bước. Bạn bắt buộc phải tự suy nghĩ, tự tra cứu tài liệu API chính thức (official docs), tự phát hiện lỗi và sửa lỗi. Mỗi lần code chạy lỗi và bạn phải vắt óc suy nghĩ để sửa, não bộ của bạn đang phát triển các liên kết neuron mạnh mẽ nhất. Giai đoạn 4: Vòng lặp phản hồi & Ôn tập ngắt quãng - Feedback & Spaced Repetition (Giờ 76 - 100) Dành 25% thời gian cuối cùng để tinh lọc tri thức. Đưa code của bạn lên các diễn đàn nhờ code review, hoặc so sánh trực tiếp code của bạn với mã nguồn của các lập trình viên chuyên nghiệp trên GitHub. Chạy các bài test hiệu năng, viết testcase để kiểm thử độ bền vững của ứng dụng. Đồng thời, liên tục ôn tập các flashcards kỹ thuật trên Anki để đóng băng kiến thức vĩnh viễn vào bộ não. 5. Kết luận: Hãy ngừng xem hướng dẫn, hãy bắt đầu hành động Phương pháp học siêu tốc (Ultralearning) không đòi hỏi bạn phải có một trí thông minh thiên tài bẩm sinh. Nó chỉ yêu cầu một sự dũng cảm bước ra khỏi vùng an toàn của việc học thụ động. Xem video hướng dẫn tạo cho chúng ta cảm giác an toàn giả tạo, nhưng chỉ có việc đối mặt với lỗi code, việc nỗ lực tự nhớ lại cú pháp và việc liên tục ôn tập ngắt quãng mới thực sự biến kiến thức đó thành tài sản vô giá của bạn. Hãy chọn ra một kỹ năng lập trình bạn luôn muốn chinh phục nhưng chưa làm được, lên kế hoạch cho 100 giờ tiếp theo theo đúng lộ trình khoa học này, gập video hướng dẫn lại và bắt đầu gõ dòng code đầu tiên bằng chính bộ óc của mình. Thành quả nhận về sau 100 giờ sẽ khiến bạn phải kinh ngạc vì năng lực bứt phá của chính bản thân.

Từ RAG đến GraphRAG: Cách các AI Agent truy xuất kiến thức doanh nghiệp chuyên sâu với độ chính xác 98%
1. Thách thức lớn nhất của AI Agent trong môi trường doanh nghiệp chuyên sâu Trong xu thế chuyển dịch mạnh mẽ sang kỷ nguyên tự trị năm 2026, các doanh nghiệp không còn hài lòng với những chatbot Q&A thông thường. Kỳ vọng hiện nay đặt vào các AI Agent (Tác nhân trí tuệ nhân tạo tự trị) có năng lực tự xử lý các luồng công việc nghiệp vụ phức tạp từ pháp lý, tài chính cho đến hỗ trợ kỹ thuật chuyên sâu. Tuy nhiên, rào cản lớn nhất cản bước AI Agent bước vào vận hành thực tế chính là: sự ảo giác (hallucination) và độ chính xác thông tin. Khi đối mặt với cơ sở dữ liệu khổng lồ của doanh nghiệp bao gồm các báo cáo tài chính hàng trăm trang, quy trình vận hành kỹ thuật (SOP), tài liệu pháp lý phức tạp, các mô hình ngôn ngữ lớn (LLM) đơn thuần thường xuyên gặp lỗi. Theo nghiên cứu thực nghiệm được công bố bởi McKinsey trong quý I/2026, các ứng dụng LLM không sử dụng cơ chế kiểm soát dữ liệu nền tảng có tỷ lệ ảo giác lên tới 25% - 35% đối với các câu hỏi đòi hỏi suy luận logic phức tạp. Đây là mức sai số hoàn toàn không thể chấp nhận trong các nghiệp vụ trọng yếu của doanh nghiệp như kiểm toán, y tế hay vận hành kỹ thuật. Để giải quyết bài toán này, kỹ thuật RAG truyền thống (Retrieval-Augmented Generation) đã được sinh ra. Tuy nhiên, trong thực tế triển khai ở các tập đoàn lớn, Naive RAG (RAG truyền thống) nhanh chóng bộc lộ những giới hạn chết người, thúc đẩy sự trỗi dậy của một bước tiến công nghệ đột phá hơn: GraphRAG (Retrieval-Augmented Generation kết hợp Đồ thị tri thức), mở ra kỷ nguyên truy xuất thông tin với độ chính xác thực chứng vượt trội lên tới 98%. 2. Bẫy hiệu năng của Naive RAG và Sự xuất hiện của GraphRAG Phương pháp Naive RAG hoạt động theo một quy trình tuyến tính tương đối đơn giản: chia nhỏ tài liệu thành các đoạn văn bản (chunks) có kích thước cố định (ví dụ 500 tokens), chuyển đổi chúng thành các vector nhúng (embeddings) và lưu trữ vào Vector Database. Khi người dùng đưa ra câu hỏi, hệ thống sẽ thực hiện tìm kiếm tương đồng vector (Cosine Similarity) để lấy ra top-k đoạn văn bản liên quan nhất và đưa vào ngữ cảnh (context) cho LLM tổng hợp câu trả lời. Mặc dù giải pháp này hoạt động tốt với các câu hỏi tra cứu thông tin cục bộ đơn giản (như "Chính sách nghỉ phép của công ty năm nay là gì?"), Naive RAG hoàn toàn thất bại trước hai dạng bài toán doanh nghiệp cực kỳ phổ biến sau: Câu hỏi suy luận liên kết (Multi-hop Reasoning): Các câu hỏi đòi hỏi phải kết nối nhiều thông tin nằm rải rác ở các tệp tin hoặc chương sách khác nhau. Ví dụ: "So sánh điều khoản chấm dứt hợp đồng của Đối tác A và Đối tác B, hợp đồng nào có mức phạt cao hơn?". Naive RAG sẽ lấy ra các đoạn văn bản rời rạc nhưng không thể hiểu được mối quan hệ logic xuyên suốt giữa chúng, dẫn đến tỷ lệ trả lời sai hoặc thiếu sót lên đến 45%. Câu hỏi tóm tắt vĩ mô (Global Query Summarization): Các câu hỏi mang tính khái quát cao như: "Những chủ đề rủi ro pháp lý chính được đề cập trong toàn bộ 50 hợp đồng thương mại của quý này là gì?". Vì Naive RAG chỉ truy xuất dựa trên độ tương đồng từ khóa/ngữ nghĩa của các đoạn nhỏ, nó hoàn toàn bỏ qua bức tranh toàn cảnh, dẫn đến câu trả lời phiến diện và bỏ sót các rủi ro hệ thống. GraphRAG là gì? Được giới thiệu lần đầu qua các nghiên cứu đột phá của Microsoft Research và nhanh chóng trở thành tiêu chuẩn vàng của doanh nghiệp vào năm 2026, GraphRAG giải quyết triệt để các điểm yếu của Naive RAG bằng cách xây dựng một Đồ thị tri thức (Knowledge Graph) trực tiếp từ dữ liệu thô. Thay vì lưu trữ các đoạn văn bản cô lập, GraphRAG sử dụng LLM để trích xuất các Thực thể (Entities - như con người, tổ chức, thiết bị, khái niệm) và các Mối quan hệ giữa các thực thể đó (Relationships). Kết quả là tạo ra một mạng lưới tri thức liên kết đa chiều, nơi mọi thông tin đều được cấu trúc hóa rõ ràng. 3. Nguyên lý vận hành: Leiden Communities và Cách GraphRAG đạt độ chính xác 98% Điểm làm nên sức mạnh vượt trội của GraphRAG nằm ở sự kết hợp hoàn hảo giữa cấu trúc đồ thị tri thức và thuật toán phân cụm mạng lưới nâng cao: Leiden Community Detection. Quy trình này diễn ra qua 3 bước cốt lõi: Bước 1: Trích xuất thực thể và quan hệ (Entity-Relation Extraction) LLM quét qua toàn bộ tài liệu doanh nghiệp để trích xuất các thực thể và phân loại chúng, đồng thời xác định các mối quan hệ (ví dụ: "Thiết bị A" -> "Được bảo trì bởi" -> "Nhân viên B"). Mối liên kết này được gắn trọng số dựa trên tần suất xuất hiện và độ tin cậy của thông tin. Bước 2: Phân cụm cộng đồng Leiden (Leiden Clustering) Hệ thống áp dụng thuật toán Leiden để tự động nhóm các thực thể có mối liên kết chặt chẽ với nhau thành các "cộng đồng tri thức" (Leiden Communities) ở các cấp độ phân cấp khác nhau (từ chi tiết đến tổng quát). Ví dụ, các thực thể liên quan đến quy trình kiểm thử phần mềm sẽ được gom thành một cộng đồng riêng, tách biệt với cộng đồng phát triển mã nguồn. Bước 3: Tóm tắt cộng đồng phân cấp (Hierarchical Summarization) Đây là phát kiến vĩ đại nhất: LLM sẽ tiến hành viết các bản tóm tắt chi tiết (Community Reports) cho từng phân cụm tri thức này từ trước (offline). Khi người dùng đưa ra câu hỏi mang tính toàn cục, AI Agent không cần phải tìm kiếm tương đồng vector trên hàng triệu đoạn văn bản nhỏ nữa. Thay vào đó, nó sẽ truy cập trực tiếp vào các bản tóm tắt cộng đồng cấp cao phù hợp nhất để trả lời, đảm bảo tính bao quát 100% ngữ cảnh tài liệu. "Bằng việc chuyển đổi dữ liệu phi cấu trúc thành một mạng lưới tóm tắt phân cấp, GraphRAG cho phép AI Agent suy luận đa chiều như một chuyên gia thực thụ có trí nhớ hoàn hảo." Nhờ cơ chế này, các báo cáo đo lường chất lượng hệ thống của các tổ chức công nghệ hàng đầu năm 2026 đã đưa ra những số liệu vô cùng ấn tượng: Độ chính xác truy xuất thực tế đạt 98%: Trong các bài kiểm thử khắt khe về câu hỏi suy luận đa bước (multi-hop) trên tập dữ liệu y tế và tài chính doanh nghiệp phức tạp, GraphRAG đạt độ chính xác trung bình lên tới 98%, so với mức chỉ 62% của Naive RAG thông thường. Giảm 85% tỷ lệ ảo giác: Sự liên kết chặt chẽ của các node đồ thị giúp định vị chính xác nguồn gốc thông tin (provenance), loại bỏ hoàn toàn hiện tượng AI tự bịa đặt dữ liệu không có trong tài liệu nguồn. Tiết kiệm tới 3 lần chi phí Token: Với các câu hỏi tổng quát vĩ mô, việc truy cập vào các báo cáo cộng đồng Leiden giúp giảm thiểu lượng context rác đưa vào prompt, tối ưu hóa dung lượng token và tiết kiệm chi phí vận hành API lên tới 68% so với phương pháp map-reduce truyền thống trên vector chunks. 4. Kiến trúc triển khai "Bộ Não Doanh Nghiệp" (Corporate Brain Architecture) Để xây dựng một hệ thống AI Agent có độ chính xác 98% trong thực tế, các doanh nghiệp cần thiết lập một kiến trúc công nghệ bài bản gồm 5 lớp chức năng đồng bộ: Lớp nạp dữ liệu (Ingestion & ETL): Tự động thu thập dữ liệu từ nhiều nguồn khác nhau của doanh nghiệp (tài liệu PDF, SQL Database, Slack/Teams, hệ thống ERP) và tiến hành làm sạch văn bản thời gian thực. Lớp trích xuất & Tạo đồ thị (Graph Construction): Sử dụng các mô hình ngôn ngữ lớn chuyên dụng (như Llama 3.1 70B hoặc GPT-4o) để trích xuất entities, relationships và đẩy vào cơ sở dữ liệu đồ thị (Graph Database) như Neo4j hoặc Memgraph. Lớp phân cụm & Tổng hợp (Leiden Community Generator): Chạy các pipeline phân cụm Leiden định kỳ để cập nhật cấu trúc cộng đồng tri thức và tự động tạo các Community Reports mới khi dữ liệu doanh nghiệp thay đổi. Lớp truy vấn hỗn hợp (Hybrid Search Engine): Kết hợp linh hoạt giữa tìm kiếm tương đồng vector (để bắt các sắc thái ngữ nghĩa tinh tế) và truy vấn đồ thị Cypher Query (để duyệt qua các mối quan hệ logic chính xác tuyệt đối). Lớp Tác nhân tự trị (Agentic Orchestrator): Đây là lớp tương tác cuối cùng, nơi AI Agent (được xây dựng trên các khung phát triển như LangGraph hoặc AutoGen) nhận yêu cầu của người dùng, tự lập kế hoạch phân tách câu hỏi, định tuyến truy vấn đến GraphRAG, kiểm tra tính đúng đắn của dữ liệu đầu ra và phản hồi cho người dùng. Mô hình kiến trúc này tạo nên một "Bộ não doanh nghiệp" tập trung, nhất quán và có khả năng tự tiến hóa theo thời gian. Mọi phòng ban từ Nhân sự, Pháp chế, Kỹ thuật cho đến Chăm sóc khách hàng đều có thể cắm các AI Agent chuyên biệt của mình vào bộ não trung tâm này để khai thác thông tin với sự an tâm tuyệt đối về mặt chính xác. 5. Lời kết và Hướng đi cho tương lai Trong cuộc đua chuyển đổi số hiện nay, dữ liệu chính là tài sản quý giá nhất của doanh nghiệp. Tuy nhiên, dữ liệu chỉ thực sự tạo ra giá trị thặng dư khi nó được kết nối, truy xuất và ứng dụng một cách chính xác. Sự kết hợp giữa các AI Agent tự trị và công nghệ GraphRAG chính là chiếc chìa khóa vạn năng giúp doanh nghiệp giải quyết triệt để bài toán tin cậy thông tin, khai phóng 100% tiềm năng của trí tuệ nhân tạo. Việc đầu tư xây dựng hệ thống GraphRAG cục bộ không chỉ giúp doanh nghiệp bảo vệ chủ quyền dữ liệu số an toàn tuyệt đối, mà còn trực tiếp tạo dựng nên một lợi thế cạnh tranh vượt trội, giúp tăng tốc độ ra quyết định chiến lược lên gấp nhiều lần. Kỷ nguyên của những câu trả lời AI mơ hồ đã kết thúc; tương lai thuộc về các tác nhân tự trị vận hành trên nền tảng tri thức được kết nối chính xác và thực chứng.

Toàn cảnh Thị trường Generative AI & AI Agent 2026: Bước chuyển mình từ Trợ lý ảo sang Tác nhân tự trị
1. 2026 - Điểm bùng phát của Kỷ nguyên Tác nhân Tự trị (AI Agent Era) Nếu như giai đoạn 2023 - 2024 được thống trị bởi các trợ lý ảo dạng hội thoại (Conversational AI) như ChatGPT, Gemini đời đầu hay Claude – những mô hình đòi hỏi người dùng phải liên tục đưa ra câu lệnh (prompting) và chỉ có thể thực hiện các nhiệm vụ đơn lẻ – thì năm 2026 đánh dấu một bước chuyển dịch mang tính lịch sử: Kỷ nguyên của các Tác nhân Tự trị (AI Agents). AI Agent không còn dừng lại ở mức trả lời các câu hỏi. Chúng là những thực thể phần mềm thông minh có khả năng tự lập kế hoạch đa bước (Multi-step Reasoning), tự tương tác với môi trường hệ điều hành (Computer Use), sử dụng các công cụ phần mềm, truy vấn database và đặc biệt là tự phát hiện và sửa sai (Self-healing) khi gặp lỗi trong quá trình thực thi nhiệm vụ. "Sự tiến hóa lớn nhất của trí tuệ nhân tạo không nằm ở việc tăng kích thước mô hình ngôn ngữ lớn, mà nằm ở kiến trúc luồng công việc tự trị (Agentic Workflows), nơi AI được trao quyền để suy luận, hành động và chịu trách nhiệm về kết quả cuối cùng." Theo báo cáo khảo sát mới nhất của Gartner vào đầu năm 2026, hơn 45% tổng số dự án phần mềm doanh nghiệp mới đã tích hợp sâu các tác nhân AI tự trị để xử lý các luồng công việc phức tạp từ đầu đến cuối mà không cần có sự giám sát liên tục của con người. Điều này chứng minh AI đang nhanh chóng dịch chuyển từ một công cụ hỗ trợ gõ phím đơn thuần trở thành những "cộng sự" đáng tin cậy thực thụ. 2. Những con số biết nói về Quy mô và Tốc độ tăng trưởng toàn cầu Sự trỗi dậy của AI Agent đã mở ra những hiệu quả kinh tế khổng lồ cho các tập đoàn đa quốc gia và nền kinh tế số toàn cầu. Các báo cáo phân tích tài chính từ McKinsey và Bloomberg trong quý I năm 2026 đã đưa ra những số liệu thống kê vô cùng thực tế: Quy mô thị trường bùng nổ: Thị trường Generative AI và AI Agent toàn cầu dự kiến sẽ cán mốc 232 tỷ USD vào cuối năm 2026, duy trì tốc độ tăng trưởng kép hàng năm (CAGR) ấn tượng lên tới 41.5% kể từ năm 2023. Tỷ lệ ứng dụng thực tế trong doanh nghiệp: Khoảng 74% các doanh nghiệp tiên phong trong lĩnh vực Công nghệ, Tài chính - Ngân hàng và Logistics đã chính thức triển khai ít nhất một hệ thống AI Agent trong môi trường sản xuất (production). Tối ưu hóa chi phí vận hành vượt trội: Việc áp dụng AI Agent vào quy trình tự động hóa dịch vụ khách hàng và quản trị chuỗi cung ứng đã giúp doanh nghiệp cắt giảm trung bình 30% đến 35% chi phí vận hành, đồng thời tăng tốc độ xử lý yêu cầu lên gấp 5 lần so với quy trình thủ công truyền thống. Bứt phá năng suất lập trình: Trong lĩnh vực phát triển phần mềm, các công cụ lập trình tự trị (như hệ sinh thái Antigravity 2.0) giúp các nhà phát triển hoàn thành dự án nhanh hơn 48%, giảm thời gian gỡ lỗi xuống 60% nhờ cơ chế tự động chạy thử nghiệm và sửa mã nguồn thời gian thực. Những số liệu thống kê thực tế này đã đập tan những hoài nghi về việc AI chỉ là một trào lưu thổi phồng. AI Agents đang trực tiếp tạo ra dòng tiền và giá trị thặng dư thực tế cho các doanh nghiệp biết nắm bắt thời cơ. 3. Các Xu hướng Công nghệ Cốt lõi định hình năm 2026 Sự phát triển vượt bậc của các Tác nhân Tự trị trong năm nay được thúc đẩy mạnh mẽ bởi 3 trụ cột công nghệ đột phá: 3.1. Tác nhân đa phương thức hoàn chỉnh (Fully Multi-modal Agents) AI Agent giờ đây không chỉ làm việc với văn bản thô. Chúng có khả năng đọc hiểu mã nguồn, phân tích hình ảnh cấu trúc thiết kế UI/UX, theo dõi video và tương tác trực quan với các ứng dụng desktop thông qua API giả lập hành vi chuột/bàn phím. Điều này cho phép AI vận hành các phần mềm nghiệp vụ giống như một nhân viên thực sự. 3.2. Cơ chế Suy luận đa bước & Tự sửa sai (Self-healing Loop) Thay vì trả về kết quả lỗi khi gặp chướng ngại vật, AI Agent năm 2026 vận hành theo chu trình kín: Lập kế hoạch (Plan) -> Thực thi (Execute) -> Kiểm thử (Test/Verify) -> Phát hiện lỗi (Catch Error) -> Điều chỉnh kế hoạch và Sửa lỗi (Refine). Cơ chế này giúp tỷ lệ hoàn thành nhiệm vụ phức tạp của AI tăng từ 15% (ở thế hệ GPT-4 cũ) lên hơn 87% với các mô hình chuyên sâu hiện nay. 3.3. Phối hợp Đa Tác nhân (Multi-Agent Systems) Xu hướng thiết kế hệ thống hiện nay là tạo ra một "phòng ban ảo" gồm nhiều AI Agent chuyên biệt cộng tác với nhau. Ví dụ: Một Agent đóng vai trò Quản lý dự án (PM) phân tích yêu cầu, một Agent lập trình viết code, một Agent QA viết testcase và chạy thử nghiệm, và một Agent Devops phụ trách đóng gói, deploy. Sự phối hợp nhịp nhàng này mang lại độ chính xác cực cao và tốc độ vận hành đáng kinh ngạc. 4. Cơ hội và Thách thức cho các Doanh nghiệp Việt Nam Đứng trước làn sóng cách mạng công nghệ này, các doanh nghiệp Việt Nam đang nắm giữ những cơ hội vô giá nhưng cũng phải đối mặt với không ít rào cản: Về mặt cơ hội: AI Agents giúp các doanh nghiệp vừa và nhỏ (SMEs) của Việt Nam san bằng khoảng cách về nguồn lực nhân sự với các tập đoàn lớn. Một đội ngũ lập trình chỉ 2-3 người có thể vận hành hiệu quả tương đương một phòng ban 15 người nếu biết cách áp dụng tối đa sức mạnh của các trợ lý Agentic như Antigravity 2.0. Về mặt thách thức: Rào cản lớn nhất nằm ở vấn đề bảo mật dữ liệu doanh nghiệp, chủ quyền dữ liệu số và chi phí hạ tầng tính toán. Để giải quyết vấn đề này, xu hướng sử dụng các mô hình ngôn ngữ lớn nguồn mở (Open-source LLMs) kết hợp với kỹ thuật RAG (Retrieval-Augmented Generation) cục bộ đang trở thành lối đi khả thi và an toàn nhất cho các doanh nghiệp trong nước. Lời kết: Năm 2026 không còn là lúc doanh nghiệp hỏi "AI có ứng dụng được không?", mà là lúc phải hành động để tích hợp AI Agents vào cốt lõi quy trình vận hành. Sự chậm trễ trong việc chuyển đổi sang mô hình làm việc tự trị (Agentic Workflow) sẽ là nguyên nhân trực tiếp khiến doanh nghiệp đánh mất năng lực cạnh tranh trong nền kinh tế số tương lai.

Bứt Phá Năng Suất Với Antigravity 2.0: Trợ Lý Lập Trình Agentic AI Định Hình Tương Lai Code
1. Antigravity 2.0 là gì? Sự chuyển dịch từ Hỗ trợ sang Tự trị (Agentic Workflow)Nếu các thế hệ trợ lý AI trước đây như ChatGPT hay Copilot cũ chỉ đóng vai trò gợi ý code theo từng dòng đơn lẻ, thì Antigravity 2.0 đại diện cho một thế hệ AI hoàn toàn mới: Agentic Coding Assistant (Trợ lý lập trình tự trị). Được phát triển bởi đội ngũ kỹ sư tối ưu hóa hàng đầu tại Google DeepMind, Antigravity 2.0 có khả năng tự suy luận, lập kế hoạch đa bước, sửa đổi tệp tin cục bộ, tự động chạy lệnh kiểm thử trên môi trường thật và giải quyết trọn vẹn các bài toán lập trình phức tạp từ đầu đến cuối mà không cần bạn phải can thiệp thủ công."Khác biệt lớn nhất của Antigravity 2.0 là khả năng tự sửa sai. AI không chỉ viết code, nó chạy thử nghiệm, tự bắt lỗi phát sinh và tiếp tục sửa đổi cho đến khi đạt được kết quả hoàn hảo."Với tư duy làm việc độc lập cao, Antigravity 2.0 biến nhà phát triển phần mềm từ vai trò "người gõ phím" trở thành "kiến trúc sư trưởng" điều phối dự án.2. Ba thế mạnh cốt lõi làm nên sức mạnh vượt trội của Antigravity 2.0Điều gì làm cho Antigravity 2.0 trở thành người bạn đồng hành vô song của mọi nhà phát triển web và ứng dụng?Khả năng tích hợp sâu sắc vào môi trường làm việc: Khác với các mô hình đóng gói trong cửa sổ chat, Antigravity 2.0 được trang bị trọn bộ công cụ mạnh mẽ: xem và sửa đổi nội dung tệp bằng các thuật toán thay thế thông minh (diff-matching), tìm kiếm văn bản toàn dự án bằng ripgrep, chạy thử các script cục bộ và quản lý tiến trình nền.Tích hợp các kỹ năng chuyên sâu (Multi-Domain Skills): Antigravity 2.0 không chỉ viết code thô. Nó có khả năng phối hợp đa miền, từ việc gọi các API chuyên ngành khoa học, truy vấn dữ liệu sinh học, cho đến việc tự sinh các hình ảnh UI/UX, ảnh minh họa chất lượng cao thông qua các công cụ sinh ảnh tích hợp để làm sống động giao diện sản phẩm.Cơ chế dự phòng thông minh tuyệt đối (Robust Fallback System): Đây là điểm tựa vững chắc giúp hệ thống tự động hóa của bạn hoạt động bền bỉ. Khi một kênh dịch vụ ngoài gặp sự cố hoặc timeout, Antigravity 2.0 sẽ tự động kích hoạt các phương án dự phòng thông minh (ví dụ: tự vẽ ảnh nghệ thuật bằng Pillow khi API sinh ảnh AI offline) nhằm đảm bảo quy trình không bao giờ bị đứt gãy giữa chừng.3. Tương lai của nghề lập trình trong kỷ nguyên Agentic AISự trưởng thành vượt bậc của những công cụ như Antigravity 2.0 đang định nghĩa lại toàn bộ vòng đời phát triển phần mềm. Tốc độ đưa ý tưởng từ bản thảo thiết kế ra sản phẩm thực tế giờ đây được rút ngắn từ hàng tuần xuống chỉ còn vài phút. Đã đến lúc chúng ta học cách cộng tác nhịp nhàng với những trợ lý thông minh như Antigravity 2.0 để mở ra những giới hạn năng suất mới, kiến tạo nên những ứng dụng đột phá đóng góp cho cộng đồng!

Google Omni Là Gì? Kỷ Nguyên AI Siêu Nhạy Bén Thay Đổi Cách Chúng Ta Tương Tác Với Thế Giới
1. Google Omni là gì? Bước nhảy vọt của Trí Tuệ Nhân TạoTại sự kiện công nghệ lớn nhất trong năm, Google đã chính thức trình làng Google Omni (nền tảng của dự án Astra đầy tham vọng). Đây không chỉ là một mô hình ngôn ngữ lớn thông thường để trò chuyện bằng văn bản, mà là một AI đa phương thức bản địa (Native Multimodal). Google Omni có thể nhìn, nghe, hiểu và phản hồi lại bạn với tốc độ thời gian thực (real-time) gần như không có độ trễ – chỉ tương đương với tốc độ phản hồi của con người (dưới 300ms)."Google Omni đại diện cho tương lai nơi ranh giới giữa thế giới vật lý và thế giới số hoàn toàn bị xóa nhòa. AI giờ đây có thể trở thành đôi mắt và đôi tai thứ hai của bạn."Với khả năng hiểu bối cảnh liên tục từ camera và giọng nói, Google Omni mang đến một trải nghiệm tương tác tự nhiên chưa từng có, vượt xa các chatbot truyền thống.2. Những tính năng đột phá của Google Omni khiến giới công nghệ kinh ngạcKhông chỉ là những lời hứa hẹn, Google Omni đã chứng minh sức mạnh qua các bài kiểm tra thực tế với những khả năng đáng kinh ngạc:Hiểu hình ảnh qua camera trực tiếp: Bạn chỉ cần quét camera quanh phòng làm việc, AI có thể lập tức phát hiện bạn để kính ở đâu, giải thích sơ đồ vẽ trên bảng trắng hoặc viết một đoạn code sửa lỗi dựa trên mã nguồn hiển thị trên màn hình máy tính.Tương tác thoại siêu mượt mà: Cuộc hội thoại không còn là các lượt gửi-nhận ngắt quãng. Bạn có thể ngắt lời AI, yêu cầu nó thay đổi tông giọng (từ hào hứng sang thì thầm) hoặc mô tả các âm thanh xung quanh.Trí nhớ ngắn hạn xuất sắc: AI có thể ghi nhớ những gì nó đã nhìn thấy cách đó vài phút qua camera để trả lời chính xác các câu hỏi logic từ bạn.3. Cách trải nghiệm Google Omni ngay hôm nayGoogle hiện đang bắt đầu tích hợp các tính năng của Omni trực tiếp vào ứng dụng Gemini trên các thiết bị Android và iOS. Bạn có thể kích hoạt tính năng thoại trực tiếp để thảo luận, luyện tập tiếng Anh giao tiếp hoặc biến nó thành một người bạn đồng hành giải quyết các tác vụ phức tạp thường ngày.Kỷ nguyên của các trợ lý AI cá nhân nhạy bén và thấu hiểu bối cảnh đã thực sự bắt đầu. Hãy là người đi đầu để khai phá toàn bộ tiềm năng mà công nghệ này mang lại!

Kỷ Nguyên Trí Tuệ Nhân Tạo (AI): Hướng Dẫn Thực Tế Làm Chủ ChatGPT & Gemini Để Nhân Đôi Hiệu Suất
1. Cuộc cách mạng AI và sự chuyển dịch kỹ năng toàn cầuTrí tuệ nhân tạo (AI) không còn là khái niệm viễn tưởng trong các bộ phim khoa học. Giờ đây, các mô hình ngôn ngữ lớn như ChatGPT của OpenAI và Gemini của Google đang trực tiếp thay đổi cách chúng ta làm việc, tư duy và sáng tạo. Sự xuất hiện của AI không đồng nghĩa với việc con người bị thay thế, mà là sự ra đời của một thế hệ nhân sự mới: những người biết cộng tác với AI để đạt hiệu quả vượt trội."AI sẽ không thay thế con người. Nhưng những người biết sử dụng AI sẽ thay thế những người không biết." - Nhận định từ các chuyên gia công nghệ hàng đầu thế giới.Để tồn tại và bứt phá trong kỷ nguyên này, việc chuyển đổi từ tư duy phòng thủ (lo sợ bị thay thế) sang tư duy chủ động (tận dụng công cụ) là bước đi tiên quyết.2. Làm chủ ChatGPT & Gemini: Kỹ năng Prompt Engineering đỉnh caoChìa khóa để mở khóa toàn bộ sức mạnh của AI nằm ở cách bạn giao tiếp với nó. Đây được gọi là Prompt Engineering (Kỹ thuật đặt câu hỏi). Một Prompt tốt sẽ mang lại một câu trả lời sắc sảo; một Prompt hời hợt chỉ nhận lại những nội dung chung chung.Dưới đây là công thức Prompt chuẩn cấu trúc để bạn áp dụng ngay lập tức:Vai trò (Role): Định hình chuyên môn cho AI (Ví dụ: "Bạn là chuyên gia marketing...").Bối cảnh (Context): Cung cấp thông tin nền tảng về dự án hoặc vấn đề.Nhiệm vụ (Task): Yêu cầu rõ ràng hành động AI cần thực hiện.Định dạng đầu ra (Format): Yêu cầu dạng danh sách, bảng biểu, mã code hoặc giọng điệu cụ thể.Bằng cách tuân thủ công thức này, bạn sẽ tiết kiệm được 80% thời gian chỉnh sửa văn bản và tối ưu hóa luồng suy nghĩ của AI.3. Tương lai thuộc về những người dẫn đầu công nghệHành trình làm chủ AI đòi hỏi sự kiên trì, thử nghiệm liên tục và không ngừng học hỏi. Hãy bắt đầu từ những việc nhỏ nhất: soạn một email bằng Gemini, lên dàn ý báo cáo bằng ChatGPT hoặc tự động hóa một bảng dữ liệu Excel. Hãy biến AI thành người trợ lý đắc lực luôn đồng hành cùng sự nghiệp của bạn!

Xu Hướng Trí Tuệ Nhân Tạo (AI) Trong Giáo Dục Hiện Đại: Cách Mạng Hóa Cách Chúng Ta Học Và Dạy
Trong kỷ nguyên số hóa phát triển với tốc độ vũ bão, Trí tuệ Nhân tạo (AI) không còn là khái niệm xa vời trong các bộ phim khoa học viễn tưởng, mà đã trở thành động lực cốt lõi định hình lại mọi lĩnh vực của đời sống xã hội. Trong số đó, giáo dục là một trong những lĩnh vực chứng kiến sự chuyển mình mạnh mẽ và sâu sắc nhất nhờ sự xuất hiện của AI. Từ việc cá nhân hóa lộ trình học tập cho đến tối ưu hóa công tác quản lý của giáo viên, AI đang mở ra một chương hoàn toàn mới cho nền giáo dục hiện đại. 1. Cá Nhân Hóa Học Tập (Personalized Learning): Mỗi Học Viên Là Một Lộ Trình Riêng Một trong những hạn chế lớn nhất của giáo dục truyền thống là mô hình "một cỡ cho tất cả" (one-size-fits-all), nơi tất cả học sinh trong lớp học ở cùng một tốc độ và một phương pháp giảng dạy bất kể sự khác biệt về năng lực hay sở thích. AI đã thay đổi hoàn toàn điều này bằng công nghệ học tập thích ứng (Adaptive Learning). Hệ thống AI có khả năng theo dõi sát sao quá trình học tập của từng cá nhân: từ cách họ trả lời các câu hỏi trắc nghiệm, thời gian họ dừng lại ở mỗi phần bài học, cho đến những lỗi sai thường gặp. Từ các dữ liệu này, AI sẽ phân tích điểm mạnh, điểm yếu và tự động điều chỉnh độ khó của bài tập, gợi ý các nội dung ôn tập bổ sung hoặc thay đổi lộ trình học tập để phù hợp nhất với tốc độ tiếp thu của học viên đó. "AI không thay thế phương pháp giáo dục truyền thống, nó nâng tầm giáo dục bằng cách đảm bảo không một học sinh nào bị bỏ lại phía sau nhờ lộ trình được thiết kế may đo cho riêng mình." 2. Trợ Lý Giảng Dạy Ảo Và Gia Sư AI 24/7 Sự bùng nổ của các mô hình ngôn ngữ lớn như ChatGPT, Google Gemini hay Claude đã đưa khái niệm "gia sư cá nhân" lên một tầm cao mới. Học sinh không còn phải chờ đợi đến giờ lên lớp để được giải đáp thắc mắc. Một gia sư AI thông minh luôn túc trực 24/7 để trả lời mọi câu hỏi từ đơn giản đến phức tạp: Giải đáp kiến thức: Giải thích các bài toán khó, phân tích ngữ pháp tiếng Anh nâng cao, tóm tắt các sự kiện lịch sử phức tạp bằng ngôn từ dễ hiểu nhất. Luyện tập tương tác: Đóng vai người bản xứ để luyện giao tiếp tiếng Anh trôi chảy, mô phỏng các buổi phỏng vấn thử nghiệm hoặc cùng thảo luận chuyên sâu về các chủ đề khoa học. Phản hồi tức thì: Nhận xét bài viết luận văn, chỉ ra các lỗi lập trình ngay lập tức và đưa ra hướng dẫn cải thiện chi tiết. 3. Giải Phóng Giáo Viên Khỏi Các Tác Vụ Hành Chính Một phần lớn thời gian làm việc của các giáo viên hiện nay bị tiêu tốn vào các công việc hành chính như soạn giáo án, chấm bài, điểm danh và báo cáo tiến độ. AI đang trở thành trợ thủ đắc lực giúp giáo viên tối ưu hóa quy trình làm việc: Hệ thống chấm điểm thông minh bằng AI có thể tự động đánh giá các bài thi trắc nghiệm và thậm chí chấm cả các bài luận văn tự luận ngắn với độ chính xác cao dựa trên barem điểm sẵn có. Hơn thế nữa, AI còn hỗ trợ gợi ý ý tưởng xây dựng bài giảng sinh động, tạo nhanh các bộ câu hỏi ôn tập định kỳ chỉ bằng vài dòng lệnh đơn giản. Điều này giúp giáo viên có thêm nhiều thời gian hơn để tập trung vào việc kết nối cảm xúc, truyền cảm hứng và phát triển kỹ năng mềm cho học sinh - những giá trị cốt lõi mà công nghệ không bao giờ thế chỗ được. 4. Thực Tế Ảo (VR) Tích Hợp AI: Học Tập Qua Trải Nghiệm Trực Quan Khi AI kết hợp cùng công nghệ Thực tế ảo (VR) và Thực tế tăng cường (AR), lớp học không còn bị giới hạn bởi 4 bức tường gạch. Học sinh có thể du hành vượt không gian và thời gian để tiếp thu kiến thức một cách chân thực nhất: Du hành vào bên trong cơ thể người để khám phá cấu trúc tế bào sinh học đang hoạt động. Đứng giữa quảng trường La Mã cổ đại và chứng kiến các sự kiện lịch sử tái hiện sống động. Tương tác an toàn trong phòng thí nghiệm hóa học ảo với các phản ứng nguy hiểm mà không lo sợ rủi ro cháy nổ. 5. Những Thách Thức Cần Đối Mặt Trong Kỷ Nguyên AI Giáo Dục Bên cạnh những cơ hội khổng lồ, việc tích hợp AI vào trường học cũng đặt ra nhiều bài toán nan giải cần giải quyết: Gian lận học thuật: Sự lạm dụng AI để viết hộ bài luận, giải hộ bài tập khiến khả năng tự duy tư phản biện và tự học của học sinh có nguy cơ bị mai một nếu không có sự giám sát và phương pháp đánh giá phù hợp. Bảo mật thông tin: Việc thu thập dữ liệu học tập cá nhân của học sinh yêu cầu một hàng rào bảo mật nghiêm ngặt để tránh rò rỉ thông tin cá nhân. Khoảng cách công nghệ: Sự chênh lệch trong việc tiếp cận công nghệ AI giữa các khu vực đô thị và nông thôn có thể vô tình làm nới rộng thêm khoảng cách giáo dục. Kết Luận: Hướng Tới Tương Lai Giáo Dục Cộng Tác Nhân - Trí AI trong giáo dục hiện đại không phải là một công cụ thay thế vai trò của người thầy, mà là một chiếc "kính vạn hoa" mở rộng tầm nhìn, giúp tối ưu năng lực dạy và học. Tương lai giáo dục sẽ thuộc về mô hình Cộng tác giữa Con người và Trí tuệ nhân tạo (Human-AI Collaboration), nơi giáo viên sử dụng sức mạnh công nghệ để thấu hiểu học sinh hơn, giúp các thế hệ tương lai sẵn sàng vững bước bước vào thế giới số đầy biến động.

Cơn sốt OpenClaw: Khi AI không chỉ dừng lại ở việc "nói"
Đầu năm 2026, thế giới công nghệ chứng kiến một bước ngoặt quan trọng khi trí tuệ nhân tạo (AI) chuyển mình từ những mô hình ngôn ngữ đơn thuần sang các thực thể có khả năng hành động độc lập. Trung tâm của làn sóng này chính là OpenClaw – một khung đại lý AI tự hành (autonomous AI agent) mã nguồn mở. 1. OpenClaw là gì: Bước tiến từ Chatbot đến Agent OpenClaw không phải là một chatbot truyền thống như ChatGPT. Đây là một hệ thống đại lý AI chủ động, được thiết kế để thay mặt người dùng thực hiện các tác vụ phức tạp thay vì chỉ phản hồi bằng văn bản. Được phát triển bởi lập trình viên người Áo Peter Steinberger, OpenClaw ban đầu có tên là Clawdbot. Về bản chất, đây là một phần mềm tự lưu trữ (self-hosted), vận hành trực tiếp trên máy tính hoặc máy chủ cá nhân của người dùng, tương tác qua các ứng dụng như WhatsApp, Telegram, Discord hoặc Signal. Hệ thống AgentSkills cho phép OpenClaw thực hiện các chuỗi tác vụ phức tạp. 2. Giải mã sức hút của "Cơn sốt Tôm hùm" Sự bùng nổ của OpenClaw vào đầu năm 2026, đặc biệt tại khu vực Trung Quốc và Đông Nam Á, xuất phát từ nhiều yếu tố: Hiệu ứng "Jarvis" đời thực: Khả năng thực hiện quy trình đa bước không cần sự can thiệp từ con người. Tính phổ quát kinh ngạc: Thu hút từ giới kỹ thuật đến người dùng không chuyên tại các trung tâm công nghệ. Biểu tượng văn hóa: Trào lưu "nuôi tôm hùm" trở thành một thú cưng kỹ thuật số độc đáo. "OpenClaw không chỉ là phần mềm, nó là bản phát hành phần mềm quan trọng nhất từ trước đến nay." - Jensen Huang, CEO Nvidia. 3. Tác động kinh tế - xã hội Cơn sốt OpenClaw không chỉ thay đổi cách làm việc mà còn tạo ra những biến động lớn trên thị trường lao động. Xu hướng "Doanh nghiệp một người" (Solopreneur) đang trỗi dậy mạnh mẽ khi một cá nhân có thể điều hành cả một hệ thống với các "nhân viên kỹ thuật số". Tầm nhìn về một kỷ nguyên đại lý AI tự chủ. Tuy nhiên, thách thức về bảo mật cũng là một vấn đề nghiêm trọng. Việc cấp quyền truy cập sâu vào dữ liệu cá nhân khiến các hệ thống cấu hình sai trở thành mục tiêu của tin tặc. Chính phủ nhiều nước đã phải đưa ra các cảnh báo về an ninh mạng trong bối cảnh làn sóng triển khai ồ ạt diễn ra. 4. Tương lai của kỷ nguyên Đại lý AI Các "ông lớn" như ByteDance và Tencent đang bắt đầu tích hợp sâu công nghệ này vào hệ sinh thái của họ. Các chuyên gia nhận định rằng "khoảnh khắc OpenClaw" chính là điểm khởi đầu cho một kỷ nguyên nơi AI đóng vai trò là cộng sự hành động thực thụ. Trong tương lai gần, OpenClaw sẽ không còn là một ứng dụng cài đặt thêm, mà có thể trở thành một phần cốt lõi của hệ điều hành, thay đổi hoàn toàn giao diện tương tác giữa con người và máy tính: Từ việc ra lệnh từng bước sang việc giao phó mục tiêu.

5 TIÊU ĐIỂM CÔNG NGHỆ NỔI BẬT THÁNG 5 NĂM 2026
Tháng 5 năm 2026 đánh dấu một giai đoạn chuyển mình mạnh mẽ của thế giới công nghệ, nơi những lý thuyết về trí tuệ nhân tạo (AI) và công nghệ vũ trụ bắt đầu đi vào thực tiễn sản xuất và thay đổi diện mạo hạ tầng toàn cầu. 1. Google I/O 2026: Sự trỗi dậy của "Googlebooks" Sự kiện thường niên Google I/O 2026 đã tạo nên cơn địa chấn khi Google chính thức ra mắt dòng máy tính cá nhân hoàn toàn mới mang tên "Googlebooks". Đây không chỉ đơn thuần là thế hệ kế nhiệm của Chromebook, mà là sự hợp nhất hoàn thiện giữa tính di động của Android và sức mạnh xử lý của PC, vận hành trên nền tảng Android 17. "Điểm nổi bật nhất chính là tính năng AI-Native, nơi hệ điều hành không còn là một công cụ thụ động." 2. Công nghệ không gian: Kỷ nguyên sản xuất trên quỹ đạo Hình ảnh mô phỏng dây chuyền sản xuất vi trọng lực tại quỹ đạo Trái Đất. Tháng 5/2026 ghi nhận một bước tiến lịch sử của Varda Space Industries khi công ty này đạt được những thỏa thuận bản lề về việc sản xuất dược phẩm trong môi trường vi trọng lực. Việc tinh thể hóa các thuốc đặc trị trên quỹ đạo cho phép tạo ra các hợp chất có độ tinh khiết tuyệt đối. 3. Hạ tầng bền vững: Giải pháp "AI Xanh" từ lòng đại dương Khi nhu cầu tính toán cho AI bùng nổ, bài toán về năng lượng và làm mát trở nên cấp thiết. Đầu tháng 5/2026, startup Panthalassa đã triển khai thành công hệ thống trung tâm dữ liệu nổi trên Thái Bình Dương. Bằng cách tận dụng năng lượng sóng biển, giải pháp này giúp cắt giảm tới 40% chi phí vận hành. 4. Biến động tại OpenAI: Giữa vòng lao lý và đột phá Thế giới công nghệ trong tháng qua cũng đổ dồn sự chú ý vào các phiên tòa liên quan đến quản trị doanh nghiệp tại OpenAI. Tuy nhiên, giữa những tranh chấp pháp lý phức tạp, OpenAI vẫn chứng minh được sức sáng tạo không ngừng khi ra mắt Codex Mobile – cho phép lập trình viên viết mã nguồn ngay trên smartphone qua giọng nói. 5. Từ Chatbot đến Agent: Kỷ nguyên của AI thực thi Tháng 5/2026 chứng kiến sự chuyển dịch mang tính bước ngoặt từ các Chatbot phản hồi sang các AI thực thi (Agentic AI). Amazon Alexa+ hiện có thể tự động quản lý đơn hàng, so sánh giá và xử lý vận đơn mà không cần sự can thiệp thủ công.

CUỘC ĐUA TRÍ TUỆ NHÂN TẠO 2026: PHÂN TÍCH THẾ MẠNH CỦA CÁC "ÔNG LỚN"
Bước sang giữa năm 2026, kỷ nguyên trí tuệ nhân tạo đã chuyển mình từ giai đoạn thử nghiệm sang sự chuyên môn hóa sâu sắc. Không còn một mô hình đơn độc nào thống trị; thị trường đang chứng kiến sự phân hóa rõ rệt. Bước sang giữa năm 2026, kỷ nguyên trí tuệ nhân tạo (AI) đã chuyển mình từ giai đoạn thử nghiệm sang sự chuyên môn hóa sâu sắc. Không còn một mô hình đơn độc nào thống trị hoàn toàn thị trường; thay vào đó, người dùng đang chứng kiến sự phân hóa rõ rệt dựa trên nhu cầu cụ thể. 1. ChatGPT (OpenAI) - Hệ sinh thái đa năng ChatGPT tiếp tục giữ vững vị thế nhờ khả năng cân bằng giữa suy luận tổng quát và trải nghiệm người dùng. Với dòng mô hình GPT-4o và GPT-5, OpenAI đã đưa khả năng giao tiếp của máy tính tiệm cận với con người. Key Fact: Hiệu suất phản hồi Công nghệ Omni-model cho phép phản hồi âm thanh và hình ảnh với độ trễ chỉ 232ms, tương đương tốc độ phản xạ tự nhiên của con người. Biểu đồ so sánh hiệu năng các mô hình AI trong năm 2026. 2. Gemini (Google) - Kỷ nguyên Context Window Tận dụng lợi thế từ Google Workspace, Gemini chọn hướng đi tập trung vào khả năng xử lý dữ liệu khổng lồ. Với cửa sổ ngữ cảnh lên đến 2 triệu token, nó trở thành "trợ lý văn phòng" đắc lực nhất. 3. Claude (Anthropic) - Tư duy phản biện Claude nổi bật nhờ sự an toàn và khả năng viết lách có sắc thái vượt trội. Tính năng "Artifacts" đã thay đổi cách người dùng làm việc, cho phép hiển thị code và giao diện web trực tiếp cạnh khung chat. Các thế lực mới: Perplexity, Grok & DeepSeek Thị trường đang chia nhỏ thành các phân khúc chuyên biệt: Perplexity thống trị việc tra cứu thời gian thực, Grok dẫn đầu về tin tức "nóng", còn DeepSeek là ngôi sao về hiệu suất lập trình và tối ưu chi phí. Tóm tắt lựa chọn công cụ ChatGPT: Trợ lý tổng quát tốt nhất. Gemini: Xử lý tài liệu dài (2M+ token). Claude: Viết lách chuyên nghiệp & logic. Perplexity: Tìm kiếm xác thực. Grok: Tin tức thời gian thực. DeepSeek: Lập trình tiết kiệm.

Kỳ thi tốt nghiệp THPT 2026
Giáo dục 2026 Kỳ thi tốt nghiệp THPT 2026: Đột phá phương thức và tư duy Kỳ thi tốt nghiệp Trung học phổ thông (THPT) năm 2026 đánh dấu cột mốc quan trọng khi đây là năm thứ hai kỳ thi được tổ chức theo Chương trình Giáo dục phổ thông (GDPT) 2018. Với mục tiêu đánh giá đúng năng lực người học và giảm áp lực thi cử, kỳ thi năm nay tiếp tục có những điều chỉnh mang tính đột phá về cấu trúc đề thi và phương thức xét tuyển. Dưới đây là thông tin tổng hợp chi tiết nhất về kỳ thi tính đến tháng 5/2026. 1. Những điểm mới và thay đổi cốt lõi theo Chương trình GDPT 2018 Khác với giai đoạn trước năm 2025, kỳ thi năm 2026 tập trung mạnh mẽ vào việc kiểm tra tư duy vận dụng thay vì ghi nhớ kiến thức máy móc. Mô hình thi 2+2: Thí sinh chỉ thi 4 môn, bao gồm: 2 môn bắt buộc (Toán, Văn) và 2 môn tự chọn. Cấu trúc đề thi mới: Đề thi Ngữ văn sử dụng ngữ liệu ngoài sách giáo khoa. Định dạng trắc nghiệm: Bổ sung câu hỏi Đúng/Sai và Trả lời ngắn. 2. Lịch thi chính thức Kỳ thi tốt nghiệp THPT 2026 Ngày Buổi sáng Buổi chiều 10/06/2026 Làm thủ tục và Phổ biến quy chế 11/06/2026 Ngữ văn Toán 12/06/2026 Môn tự chọn Dự phòng 3. Công tác chuẩn bị tại TP. Hồ Chí Minh Là địa phương có số lượng thí sinh đông nhất cả nước, TP. HCM đã hoàn tất các bước chuẩn bị cuối cùng với hơn 95.000 thí sinh và 160 điểm thi. "Kỳ thi tốt nghiệp THPT 2026 không chỉ là một kỳ kiểm tra kiến thức, mà còn là cánh cửa mở ra lộ trình nghề nghiệp tương lai trong bối cảnh giáo dục hiện đại." Lời khuyên cho sĩ tử Trước thềm kỳ thi, hãy chú trọng vào việc hiểu bản chất thay vì học vẹt. Việc rèn luyện với các định dạng đề thi mới, đặc biệt là phần câu hỏi trả lời ngắn, sẽ là chìa khóa giúp các bạn đạt kết quả cao nhất. Back to Top ↑

Xu Hướng Trí Tuệ Nhân Tạo năm 2026
Công Nghệ & Tương Lai Đón Đầu 2026: 5 Xu Hướng Trí Tuệ Nhân Tạo Đang Định Hình Lại Tương Lai Nhân Loại Bước vào năm 2026, Trí tuệ Nhân tạo (AI) đã vượt qua giai đoạn bùng nổ của những "từ khóa thời thượng" để chính thức bước vào kỷ nguyên của sự hội nhập sâu rộng. Nếu những năm 2023-2024 được đánh dấu bởi sự kinh ngạc trước khả năng của AI tạo sinh, thì năm 2026 chứng kiến AI trở thành một loại "điện năng mới" – vô hình, thiết yếu và hiện diện trong mọi ngóc ngách của nền kinh tế toàn cầu. 1. Agentic AI: Từ "Công Cụ Trả Lời" Đến "Người Thực Thi Tự Chủ" Sự chuyển dịch lớn nhất trong năm 2026 là sự trỗi dậy của Agentic AI – các đặc vụ trí tuệ nhân tạo có khả năng tự chủ. Không còn giới hạn ở việc chờ đợi các câu lệnh chi tiết, Agentic AI có thể hiểu mục tiêu cuối cùng và tự phân bổ tài nguyên. "Điều này biến AI từ một trợ lý thụ động thành một quản lý dự án tự chủ hoàn hảo." 2. AI Tạo Sinh Thế Hệ Mới: Đa Phương Thức Thời Gian Thực Các mô hình ngôn ngữ lớn (LLM) năm 2026 có thể nghe, nhìn, nói và hành động trong thời gian thực với độ trễ gần như bằng không. 3. Edge AI: Sức Mạnh Tính Toán Rời Bỏ Đám Mây Năm 2026, thế giới chứng kiến sự bùng nổ của Edge AI – đưa năng lực xử lý trí tuệ nhân tạo trực tiếp vào các thiết bị đầu cuối như điện thoại thông minh, xe tự lái và thiết bị IoT, đảm bảo tính bảo mật và phản hồi tức thì. 4. AI Trong Y Tế Chuyên Sâu: Kỷ Nguyên Của Sinh Học Điện Toán Sự kết hợp giữa AI và sinh học điện toán đang rút ngắn thời gian nghiên cứu thuốc mới từ 10 năm xuống chỉ còn vài tháng. Y tế giờ đây đã chuyển dịch từ "chữa bệnh" sang "dự đoán và ngăn chặn". 5. Đạo Đức Và Quản Trị AI Toàn Cầu Khi AI trở nên quá mạnh mẽ, năm 2026 chứng kiến sự hoàn thiện của các bộ luật quản trị toàn cầu. Các công nghệ như "Watermarking" được áp dụng bắt buộc nhằm chống lại đại dịch tin giả, đưa tính minh bạch trở thành tiêu chuẩn pháp lý. Tác Động Toàn Diện Khái niệm "làm việc" được định nghĩa lại. Lực lượng lao động chuyển dịch sang mô hình: Con người + AI. Những kỹ năng mềm như tư duy phản biện và óc sáng tạo triết học lên ngôi. Kết Luận: Sự Cộng Sinh Tương lai không phải là một bộ phim khoa học viễn tưởng đen tối, mà là một kỷ nguyên của sự cộng sinh. Trí tuệ nhân tạo là tấm gương phản chiếu, khuếch đại cả năng lực kiến tạo lẫn những sai lầm của con người. Back to Top ↑

Kỳ Thi Vào Lớp 10 Năm 2026
Giáo dục & Đời sống TIÊU ĐIỂM TUYỂN SINH LỚP 10 NĂM 2026: THỬ THÁCH TỪ ĐỔI MỚI VÀ CUỘC ĐUA VÀO TRƯỜNG CÔNG LẬP Cập nhật ngày: 16/05/2026 Chỉ còn chưa đầy ba tuần nữa, kỳ thi tuyển sinh vào lớp 10 năm học 2026-2027 sẽ chính thức diễn ra trên cả nước. Đây là năm thứ hai kỳ thi được tổ chức hoàn toàn theo Chương trình Giáo dục phổ thông 2018. 1. Tình hình chung trên cả nước: Chuẩn hóa theo định hướng năng lực Năm 2026, Bộ Giáo dục và Đào tạo tiếp tục kiên trì mục tiêu giảm áp lực thi cử nhưng vẫn đảm bảo phân luồng hiệu quả sau THCS. Theo ghi nhận, hầu hết các tỉnh, thành phố vẫn duy trì phương thức thi tuyển với 3 môn bắt buộc: Toán, Ngữ văn và Ngoại ngữ. Định hướng năng lực trở thành kim chỉ nam cho đề thi năm nay. Điểm mới nổi bật trong năm nay là sự thống nhất cao trong định hướng ra đề thi. Các địa phương như Hà Nội, Đà Nẵng, Hải Phòng và Cần Thơ đều chuyển dịch mạnh mẽ từ kiểm tra kiến thức sang đánh giá năng lực giải quyết vấn đề thực tiễn. Đề thi có độ phân hóa cao, lồng ghép nhiều tình huống thực tế và các câu hỏi mang tính liên môn. 2. Tiêu điểm tại Thành phố Hồ Chí Minh: Áp lực và những điều chỉnh quyết định Tại TP.HCM, không khí ôn tập tại các trường THCS đang bước vào giai đoạn nước rút cao độ. Số lượng thí sinh và chỉ tiêu: Toàn thành phố có khoảng 116.500 học sinh tốt nghiệp THCS, trong đó có hơn 102.000 thí sinh đăng ký dự thi vào lớp 10 công lập. Dự kiến sẽ có hơn 25.000 thí sinh không có suất học vào công lập. Lịch thi chính thức: Kỳ thi sẽ diễn ra trong hai ngày 01 và 02/06/2026. Thay đổi cấu trúc: Môn Ngữ văn sử dụng ngữ liệu ngoài sách giáo khoa, Toán tăng cường bài toán thực tế, Ngoại ngữ tập trung tình huống giao tiếp. "Kỳ thi tuyển sinh lớp 10 năm 2026 không chỉ là một cuộc sát hạch kiến thức mà còn là bài kiểm tra về bản lĩnh và khả năng thích ứng của thế hệ học sinh đầu tiên tốt nghiệp theo chương trình mới." 3. Lời khuyên từ chuyên gia Đối với thí sinh, việc xây dựng thời gian biểu khoa học là vô cùng cần thiết. Hãy đảm bảo ngủ đủ giấc và luyện giải đề theo ma trận minh họa để rèn tâm lý phòng thi. Với phụ huynh, chìa khóa nằm ở việc trở thành điểm tựa tinh thần vững chắc. Việc chuẩn bị dinh dưỡng hợp lý và cùng con rà soát nguyện vọng một cách bình tĩnh sẽ giúp các em vững vàng hơn trước giờ G. Back to Top ↑