
1. Cuộc dịch chuyển lịch sử từ những đám mây xa xôi về phần cứng cục bộ
Trong giai đoạn đầu bùng nổ của trí tuệ nhân tạo (2023 - 2025), việc vận hành AI gắn liền với khái niệm điện toán đám mây. Người dùng đã quá quen thuộc với việc gửi các yêu cầu dịch thuật, viết code, hay phân tích dữ liệu lên các máy chủ khổng lồ của các tập đoàn công nghệ lớn và chờ đợi phản hồi. Mô hình vận hành tập trung này đã giúp phổ cập nhanh chóng sức mạnh của các mô hình ngôn ngữ lớn (LLM). Tuy nhiên, bước sang năm 2026, thế giới công nghệ đang chứng kiến một cuộc chuyển dịch mang tính lịch sử: Kỷ nguyên của các Tác nhân AI trên thiết bị (On-Device AI Agents).
Sự bùng nổ này được thúc đẩy bởi sự kết hợp hoàn hảo giữa hai yếu tố: **Sự hoàn thiện của chip xử lý AI (NPU)** và **Sự ra đời của các mô hình ngôn ngữ nhỏ (Small Language Models - SLMs) hiệu năng cao**. Thay vì hoạt động như một ứng dụng web thụ động, AI giờ đây đã trở thành các tác nhân tự trị (Agents), vận hành độc lập ngay trên chiếc laptop, điện thoại thông minh hoặc thiết bị đeo của cá nhân mà không cần kết nối Internet.
Theo báo cáo phân tích thị trường mới nhất của hãng nghiên cứu Canalys, thị phần máy tính AI PC (các máy tính tích hợp nhân xử lý NPU chuyên dụng) đang bùng nổ với tốc độ chưa từng có, dự kiến chiếm đến **60% tổng lượng PC xuất xưởng toàn cầu vào năm 2026**. Trí thông minh nhân tạo bản địa (native AI) chạy trực tiếp trên phần cứng của người dùng không còn là một ý tưởng lý thuyết, mà đã chính thức trở thành tiêu chuẩn công nghệ mới của kỷ nguyên điện toán cá nhân.
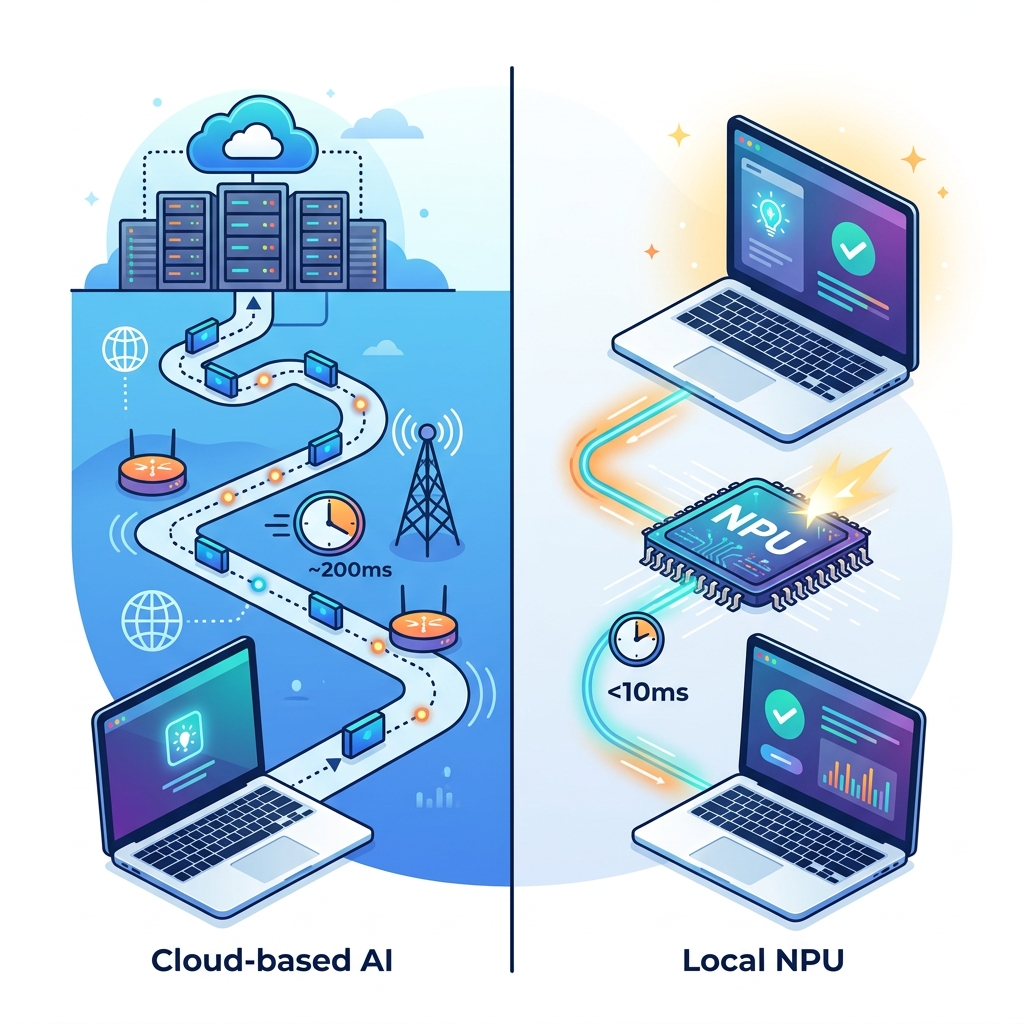
2. Triệt tiêu độ trễ: Sức mạnh bứt phá của NPU so với API đám mây
Một trong những rào cản lớn nhất của AI đám mây truyền thống là độ trễ (latency). Khi tương tác với các mô hình đám mây qua cổng API, yêu cầu của bạn phải đi qua nhiều tầng trung gian: mạng internet -> hàng đợi trên server -> quá trình xử lý suy luận -> truyền ngược kết quả lại thiết bị. Quy trình phức tạp này khiến độ trễ phản hồi trung bình dao động từ **1.5 đến 2.5 giây (1500ms - 2500ms)**.
Đối với các tác vụ thông thường như viết blog hay dịch thuật, vài giây chờ đợi có thể chấp nhận được. Tuy nhiên, đối với các tác nhân AI tự trị (AI Agents) thực hiện các quy trình đa bước phức tạp (như tự động kiểm thử phần mềm liên tục, điều khiển giao diện hệ điều hành hoặc hỗ trợ giọng nói thời gian thực), độ trễ hàng giây sẽ phá vỡ hoàn toàn trải nghiệm người dùng và làm giảm hiệu suất vận hành.
On-Device AI giải quyết bài toán độ trễ thế nào?
- Đáp ứng tức thì dưới 50ms - 100ms: Nhờ nhân xử lý AI chuyên dụng – **NPU (Neural Processing Unit)** đạt tiêu chuẩn hiệu năng phần cứng năm 2026 từ **45 đến 55 TOPS** (Trillion Operations Per Second) trên các thiết bị PC và di động – các mô hình ngôn ngữ nhỏ (SLM) có thể thực hiện suy luận cục bộ siêu tốc. Thời gian phản hồi được rút ngắn xuống dưới **50ms - 100ms** (nhanh hơn từ 15 đến 25 lần so với đám mây), tạo ra trải nghiệm tương tác tự nhiên, mượt mà và tức thì.
- Tiết kiệm năng lượng cực đoan: Chip NPU được thiết kế tối ưu hóa riêng cho các phép toán ma trận của mạng nơ-ron, giúp tiêu thụ điện năng chỉ bằng **1/10 đến 1/20** so với việc chạy GPU truyền thống trên thiết bị, giúp kéo dài thời lượng pin của thiết bị di động lên đáng kể.
- Độ tin cậy tuyệt đối: Hệ thống vận hành hoàn hảo ngay cả trong môi trường không có kết nối internet như trên máy bay, các vùng sâu vùng xa hoặc các phòng thí nghiệm bảo mật cao bị cách ly hoàn toàn.

3. Tự chủ bộ nhớ dài hạn cục bộ (Long-Term Memory Autonomy)
Một trong những điểm đột phá lớn nhất của On-Device AI Agents thế hệ mới năm 2026 chính là khả năng tự chủ quản lý bộ nhớ dài hạn (Long-Term Memory) mà không phụ thuộc vào lưu trữ đám mây. Khác với các mô hình trước đây vốn "quên" ngữ cảnh ngay khi kết thúc phiên chat, các tác nhân AI cục bộ tự xây dựng và vận hành một hệ cơ sở dữ liệu vector cá nhân (Local Vector Database) siêu tối giản trực tiếp trên ổ cứng thiết bị.
Cách thức vận hành của bộ nhớ dài hạn tự trị:
- Ghi nhớ thói quen và ngữ cảnh sử dụng: Hệ thống tự động ghi nhận các tài liệu bạn thường đọc, cấu trúc viết code ưa thích, hoặc phong cách viết email hàng ngày để tạo thành các file vector nhúng (vector embeddings) cục bộ.
- Truy xuất ngữ cảnh tức thời dưới 10ms: Khi bạn bắt đầu một công việc mới, AI Agent sẽ tự động thực hiện tìm kiếm ngữ nghĩa trên Vector DB cục bộ để tải lại các thông tin liên quan chỉ trong chưa đầy **10ms**, giúp Agent hiểu ngay bạn muốn làm gì mà không cần bạn phải nhập lại bối cảnh từ đầu.
- Bảo vệ quyền riêng tư tuyệt đối: Toàn bộ dữ liệu bộ nhớ dài hạn của bạn được lưu trữ vật lý 100% trên thiết bị cá nhân và được mã hóa bằng thuật toán cấp quân sự của hệ điều hành. Theo khảo sát bảo mật từ Cisco, **65% tổ chức doanh nghiệp** đã cấm nhân viên gửi dữ liệu nhạy cảm lên đám mây công cộng; vì thế, bộ nhớ dài hạn cục bộ là giải pháp duy nhất giúp doanh nghiệp vừa khai thác được sức mạnh AI cá nhân hóa vừa bảo mật tuyệt đối tài sản trí tuệ.
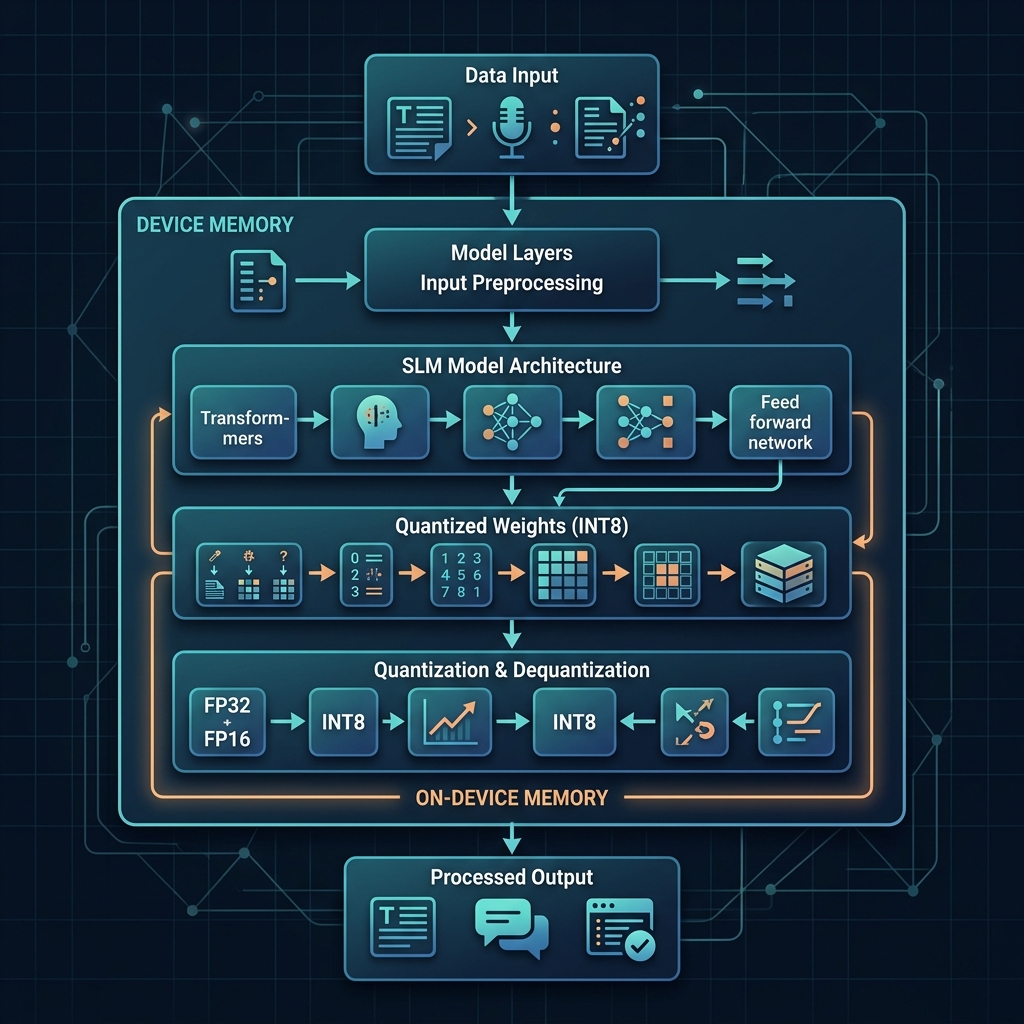
4. Sức mạnh của SLMs lượng tử hóa: Trọng tâm của cuộc cách mạng cục bộ
Để một mô hình AI có thể chạy mượt mà ngay trên các thiết bị cá nhân có cấu hình giới hạn mà không làm nghẽn RAM, công nghệ lượng tử hóa mô hình (Model Quantization) đã đóng vai trò là chiếc chìa khóa vàng.
Lượng tử hóa 4-bit (4-bit quantization) là kỹ thuật nén thông minh, chuyển đổi các trọng số của mô hình từ dạng số thực 16-bit phức tạp xuống dạng số nguyên 4-bit siêu gọn nhẹ:
- Tối ưu hóa dung lượng RAM: Một mô hình ngôn ngữ nhỏ (SLM) với khoảng 7 đến 8 tỷ tham số (7B/8B) thông thường cần khoảng 16 GB bộ nhớ RAM để vận hành. Sau khi lượng tử hóa xuống mức 4-bit, dung lượng mô hình giảm mạnh chỉ còn khoảng **4.5 GB đến 5 GB RAM**, giúp thiết bị dễ dàng chạy song song AI Agent cùng các ứng dụng văn phòng khác mà không gây giật lag.
- Bảo toàn 95% năng lực suy luận: Mặc dù kích thước mô hình giảm đi đáng kể, các nghiên cứu thực nghiệm năm 2026 chứng minh các mô hình SLM lượng tử hóa vẫn giữ được tới **95% năng lực suy luận logic** và độ chính xác so với mô hình gốc chưa nén.
- Tích hợp sâu vào hệ điều hành: Microsoft Copilot Runtime và Apple Intelligence đang tích hợp sâu các mô hình SLMs này trực tiếp vào lõi hệ điều hành, cho phép các lập trình viên gọi trực tiếp API cục bộ của thiết bị để xây dựng các ứng dụng thông minh mà không cần tự duy trì hạ tầng mô hình riêng.
5. Lời kết: Tương lai tự trị nằm ngay trên bàn làm việc của bạn
Kỷ nguyên AI Agents trên thiết bị đánh dấu sự trưởng thành vượt bậc của cả phần cứng lẫn thuật toán học máy. Chúng ta đang chứng kiến sự kết thúc của thời kỳ phụ thuộc hoàn toàn vào các siêu đám mây tập trung, mở đầu cho kỷ nguyên dân chủ hóa trí tuệ nhân tạo, nơi mỗi cá nhân đều sở hữu một trợ lý AI thông minh, độc quyền, bảo mật tuyệt đối và phản hồi tức thì.
Với sức mạnh xử lý vượt trội của chip NPU thế hệ mới cùng sự tối ưu hóa cực đoan của các mô hình SLMs lượng tử hóa và bộ nhớ dài hạn tự trị, rào cản về chi phí API và mối lo ngại rò rỉ dữ liệu đã chính thức bị phá bỏ. Tương lai của trí tuệ nhân tạo không còn nằm ở đâu đó xa xôi trên những cụm máy chủ đám mây khổng lồ; tương lai ấy đang vận hành âm thầm, mạnh mẽ và an toàn ngay trong chính lòng bàn tay và trên bàn làm việc của bạn.