
1. Sự chuyển dịch lịch sử từ Đám mây về Thiết bị phần cứng cục bộ
Trong giai đoạn 2023 - 2025, thế giới công nghệ bị thống trị bởi các mô hình ngôn ngữ lớn (LLM) vận hành trên nền tảng điện toán đám mây khổng lồ như GPT-4 hay Gemini Pro. Người dùng đã quen với việc gửi các yêu cầu lên mây và chờ phản hồi. Tuy nhiên, bước sang năm 2026, một xu hướng công nghệ mang tính cách mạng đang định hình lại hoàn toàn cách chúng ta tương tác với trí tuệ nhân tạo: Kỷ nguyên của các Tác nhân AI trên thiết bị (On-Device AI Agents).
Việc phụ thuộc hoàn toàn vào đám mây đang bộc lộ những giới hạn nghiêm trọng về bảo mật dữ liệu, chi phí vận hành API đắt đỏ và đặc biệt là **độ trễ đường truyền**. Để giải quyết triệt để bài toán này, các nhà sản xuất phần cứng và phần mềm toàn cầu đang ráo riết chuyển dịch trí thông minh nhân tạo trực tiếp về chip xử lý cục bộ trên laptop, điện thoại thông minh và các thiết bị IoT.
Theo báo cáo dự báo mới nhất của Gartner công bố đầu năm 2026, **hơn 60% điện thoại thông minh cao cấp** bán ra trong năm nay và **45% số lượng máy tính cá nhân doanh nghiệp mới** sẽ được tích hợp sâu các mô hình ngôn ngữ nhỏ (Small Language Models - SLMs) có khả năng tự trị hoàn toàn trên thiết bị mà không cần kết nối Internet. AI giờ đây không còn là một dịch vụ web xa xôi, mà đã thực sự trở thành một thành phần bản địa gắn liền với phần cứng của bạn.

2. Triệt tiêu độ trễ: Sức mạnh bứt phá của NPU cục bộ so với API đám mây
Độ trễ (Latency) chính là kẻ thù số một của trải nghiệm người dùng chuyên nghiệp và các tác vụ tự động hóa thời gian thực. Khi sử dụng các mô hình AI đám mây thông qua API, luồng dữ liệu phải trải qua hành trình phức tạp: mã hóa dữ liệu -> gửi qua internet lên server -> xếp hàng chờ xử lý -> LLM tính toán -> gửi phản hồi ngược lại thiết bị. Quy trình này thường tốn từ **1.5 đến 3 giây (1500ms - 3000ms)** cho mỗi lượt tương tác.
Độ trễ vài giây này khiến việc xây dựng các trợ lý AI tương tác giọng nói thời gian thực hoặc các tác nhân tự trị liên tục (Continuous Agents) giám sát luồng công việc trở nên vô cùng chậm chạp và khó chịu.
On-Device AI thay đổi cuộc chơi thế nào?
- Phản hồi siêu tốc dưới 100ms: Nhờ các chip xử lý AI chuyên dụng – **NPU (Neural Processing Unit)** đạt tiêu chuẩn hiệu năng trung bình từ **40 đến 50 TOPS** (Trillion Operations Per Second) trên các dòng máy tính AI PC năm 2026 – các mô hình ngôn ngữ nhỏ cục bộ có thể trả về câu trả lời gần như lập tức trong vòng **dưới 100ms** (tốc độ nhanh hơn gấp 20 đến 30 lần so với đám mây).
- Triệt tiêu chi phí API: Với các luồng công việc tự động hóa (Agentic Workflows) đòi hỏi hàng ngàn lượt gọi mô hình mỗi ngày, việc chạy cục bộ giúp doanh nghiệp tiết kiệm từ **70% đến 80% chi phí vận hành API** đám mây đắt đỏ.
- Hoạt động ngoại tuyến 100%: AI Agent trên thiết bị vận hành hoàn hảo ngay cả khi bạn đang ngồi trên máy bay, ở khu vực mất sóng hoặc trong các mạng nội bộ bảo mật cao cách ly hoàn toàn với Internet.

3. Tự chủ bộ nhớ dài hạn (Long-Term Memory): Chìa khóa tạo nên sự thấu hiểu cá nhân hóa
Một AI Agent chạy trên thiết bị sẽ không bao giờ phát huy được tối đa sức mạnh nếu mỗi lần khởi động lại, nó đều quên đi bạn là ai và bạn đã làm gì. Để biến một mô hình ngôn ngữ nhỏ (SLM) cục bộ thành một cộng sự đắc lực thực thụ, công nghệ AI năm 2026 đã tích hợp cơ chế **Tự chủ bộ nhớ dài hạn (Long-Term Memory State Management)** ngay trên phần cứng cục bộ.
Bộ nhớ dài hạn cục bộ được vận hành thông qua các cấu trúc kỹ thuật tiên tiến sau:
- Cơ sở dữ liệu Vector cục bộ (Local Vector Cache): Hệ thống tự động mã hóa lịch sử tương tác, thói quen viết code, phong cách viết email và các tài liệu cá nhân của bạn thành các vector nhúng và lưu trữ an toàn trong một Vector DB siêu nhẹ chạy cục bộ (như LanceDB hoặc SQLite với extension vector).
- Quản lý trạng thái ngữ cảnh (Context State Tracker): AI Agent liên tục cập nhật và duy trì trạng thái làm việc của người dùng thời gian thực. Khi bạn chuyển đổi giữa các tab công việc từ viết code, kiểm thử đến soạn thảo văn bản, AI Agent nắm giữ ngữ cảnh xuyên suốt để đưa ra các gợi ý chính xác tuyệt đối mà không cần người dùng phải giải thích lại từ đầu.
- Triệt tiêu rủi ro rò rỉ dữ liệu (Zero Data Leakage): Theo khảo sát thực tế, **hơn 75% doanh nghiệp** coi việc rò rỉ thông tin nội bộ khi nhân viên paste dữ liệu lên các Chatbot đám mây là mối nguy cơ an ninh hàng đầu. Với On-Device AI, mọi thông tin nhạy cảm, mã nguồn dự án hay báo cáo tài chính đều được xử lý vật lý 100% bên trong thiết bị của bạn, loại bỏ hoàn toàn nguy cơ bị bên thứ ba thu thập hoặc dùng để huấn luyện mô hình công cộng.
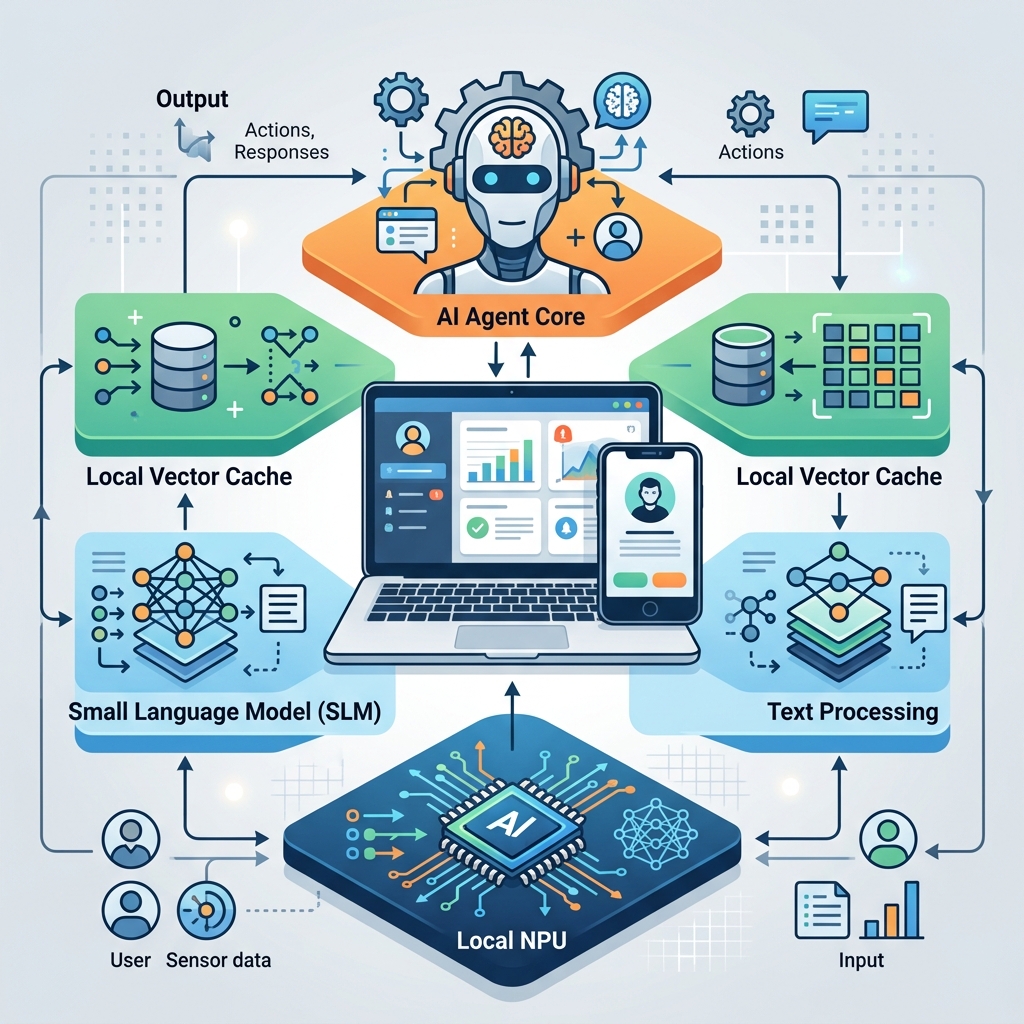
4. Kiến trúc phân lớp của một On-Device AI Agent hoàn chỉnh
Để vận hành trơn tru một tác nhân thông minh ngay trên phần cứng cá nhân, các nhà phát triển đã xây dựng một kiến trúc phân lớp chuẩn hóa gồm 4 thành phần cốt lõi:
- Lớp Phần cứng (Hardware Layer): Nền tảng là chip NPU hiệu năng cao cùng cơ chế chia sẻ bộ nhớ thông minh (Unified Memory) giữa CPU, GPU và NPU, cho phép truy xuất trọng số mô hình với băng thông cực cao.
- Lớp Mô hình lõi (Model Layer): Sử dụng các mô hình ngôn ngữ nhỏ được tối ưu hóa cực đoan (như Llama 3.2 3B, Phi-3.5 Mini hay Gemma 2B) thông qua các kỹ thuật lượng tử hóa (Quantization) xuống mức 4-bit hoặc 8-bit để giảm dung lượng bộ nhớ RAM tiêu thụ xuống dưới 2GB - 3GB mà vẫn giữ nguyên **95% năng lực suy luận** so với mô hình gốc.
- Lớp Quản lý tri thức cục bộ (Local Knowledge Layer): Kết hợp công nghệ RAG cục bộ và Vector Cache để lưu trữ và truy xuất tức thì các tài liệu, sơ đồ dự án và thói quen cá nhân của người dùng.
- Lớp Tác nhân tự trị (Agentic Orchestrator): Bộ định tuyến logic nhận yêu cầu, tự động lập kế hoạch đa bước, gọi các công cụ phần mềm cục bộ (như trình duyệt web, terminal, file system) và giám sát kết quả thực thi thời gian thực dưới cơ chế bảo mật nghiêm ngặt của hệ điều hành.
5. Lời kết: Tương lai nằm trong tầm tay của bạn
Kỷ nguyên AI Agents trên thiết bị đang mở ra một trang mới cho lịch sử điện toán cá nhân. Chúng ta đang dịch chuyển từ thời đại sử dụng các trợ lý AI đám mây chung chung sang thời đại sở hữu những "bộ não số" độc quyền, được cá nhân hóa sâu sắc, chạy trực tiếp trên thiết bị của mỗi cá nhân với độ bảo mật tuyệt đối và tốc độ phản hồi tức thì.
Sự trưởng thành của các mô hình ngôn ngữ nhỏ (SLMs) kết hợp sức mạnh vượt trội của chip NPU thế hệ mới đã chính thức đập tan rào cản về độ trễ và chi phí vận hành. Tương lai của trí tuệ nhân tạo không còn nằm trên các đám mây xa xôi của các tập đoàn khổng lồ; tương lai đó đang vận hành lặng lẽ, an toàn và mạnh mẽ ngay trong chính chiếc laptop và điện thoại thông minh nằm trên bàn làm việc của bạn.