
1. Giới hạn của cơ sở dữ liệu truyền thống trong kỷ nguyên AI
Trong hơn 4 thập kỷ qua, các cơ sở dữ liệu quan hệ (RDBMS như PostgreSQL, MySQL) và NoSQL (như MongoDB) đã thống trị thế giới phần mềm nhờ khả năng lưu trữ và truy vấn dữ liệu cấu trúc cực kỳ chính xác. Tuy nhiên, khi trí tuệ nhân tạo bùng nổ, hơn 80% dữ liệu của doanh nghiệp lại tồn tại dưới dạng phi cấu trúc (unstructured data) như văn bản tài liệu dài, hình ảnh, âm thanh và video. Các hệ thống tìm kiếm từ khóa truyền thống (keyword search dựa trên khớp chuỗi exact match) bộc lộ điểm yếu lớn: chúng hoàn toàn không hiểu được ý nghĩa ngữ nghĩa (semantic meaning) đằng sau câu hỏi của người dùng.
Ví dụ, khi người dùng tìm kiếm 'người dẫn đường cho xe hơi', công cụ tìm kiếm từ khóa cũ sẽ thất bại nếu bài viết chỉ chứa từ 'hệ thống định vị GPS'. Đây chính là lý do công nghệ **Cơ sở dữ liệu Vector (Vector Databases)** ra đời và bùng nổ mạnh mẽ, được dự báo đạt quy mô thị trường toàn cầu **4.2 tỷ USD** vào năm 2026 với tốc độ tăng trưởng hàng năm trên 28%.
2. Cơ sở dữ liệu Vector là gì và cách thức vận hành?
Cơ sở dữ liệu Vector là hệ thống lưu trữ được thiết kế chuyên biệt để quản lý và truy vấn các chuỗi số đại diện cho dữ liệu dưới dạng toán học, gọi là **Vector Embeddings** (chuỗi nhúng vector). Các mô hình AI (như OpenAI text-embedding, Cohere) biến đổi văn bản, hình ảnh thành các tọa độ điểm trong không gian đa chiều (thường từ 768 đến 1536 chiều).
Thay vì so sánh chính xác từng chữ, Vector DB sử dụng thuật toán tìm kiếm láng giềng gần nhất (Approximate Nearest Neighbor - ANN) để đo khoảng cách góc (Cosine Similarity hoặc Euclidean Distance) giữa các vector. Điều này cho phép hệ thống tìm ra các đoạn văn bản hoặc hình ảnh có ý nghĩa tương đồng nhất với câu hỏi của người dùng chỉ trong chưa đầy **15 mili-giây**, ngay cả trên tập dữ liệu khổng lồ hàng tỷ vector.
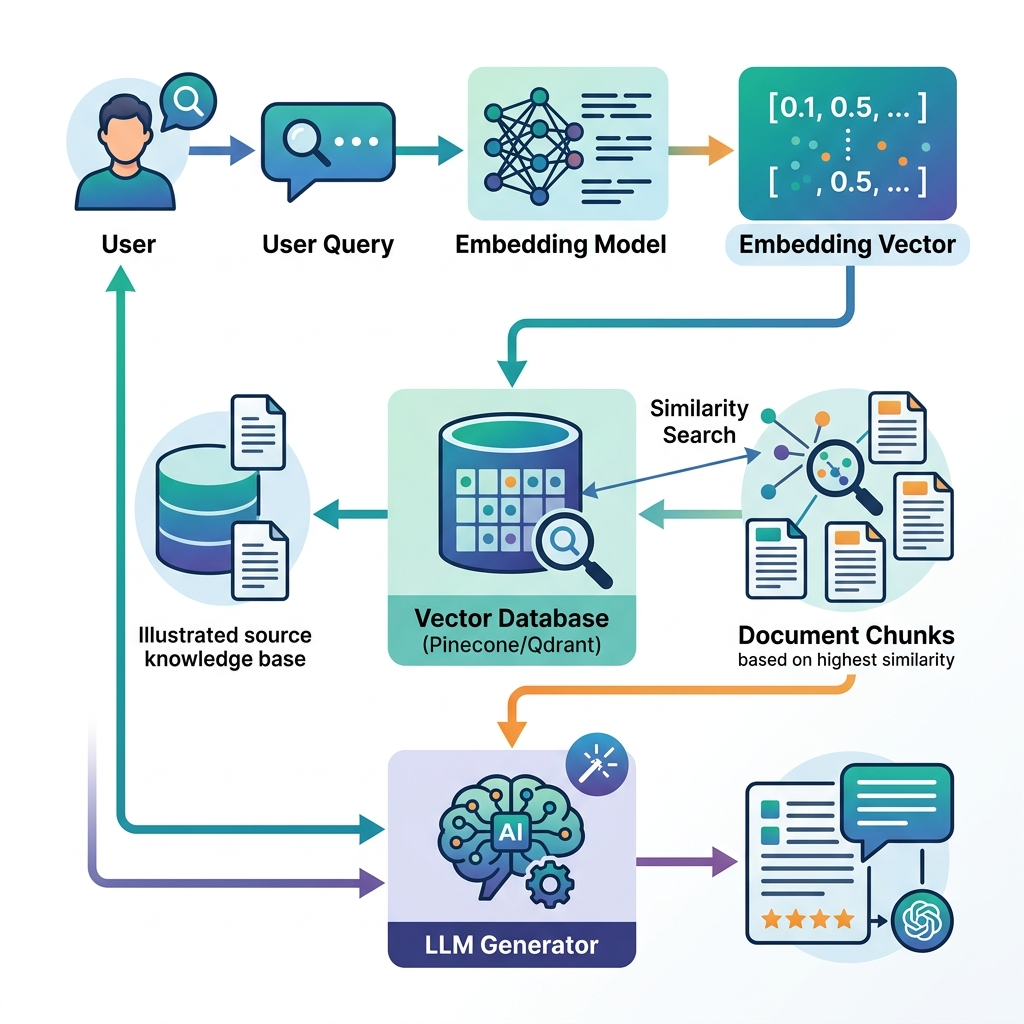
3. Ứng dụng cốt lõi: Nâng cấp RAG và triệt tiêu 'Ảo giác AI'
Ứng dụng quan trọng nhất của Vector Database hiện nay nằm ở việc xây dựng kiến trúc **Retrieval-Augmented Generation (RAG)** cho các doanh nghiệp. Mặc dù các mô hình ngôn ngữ lớn (LLM) rất thông minh, chúng thường gặp phải hội chứng 'ảo giác' (hallucination - tự bịa ra thông tin sai sự thật) hoặc không có dữ liệu nội bộ riêng tư của doanh nghiệp.
Bằng cách tích hợp các Vector DB nguồn mở và thương mại hàng đầu như Pinecone, Qdrant, Milvus hay ChromaDB vào hệ thống RAG:
- Khi người dùng đặt câu hỏi, hệ thống sẽ truy vấn Vector DB để lấy ra đúng các đoạn tài liệu nội bộ liên quan nhất.
- Gửi các đoạn tài liệu này làm bối cảnh (context) cho LLM để mô hình tổng hợp câu trả lời chính xác 100%.
- Thực nghiệm chứng minh, giải pháp này giúp giảm tỷ lệ ảo giác của LLM từ trên 25% xuống dưới **4%**, mở ra cơ hội đưa chatbot AI vào các lĩnh vực đòi hỏi độ chính xác tuyệt đối như y tế, pháp lý và tài chính.
4. Chiến lược Hybrid Search: Lối đi tối ưu hệ thống tìm kiếm doanh nghiệp
Dù Vector Search rất mạnh mẽ về mặt ngữ nghĩa, nó đôi khi lại bỏ sót các từ khóa chính xác chuyên ngành (như mã sản phẩm, mã lỗi code, tên riêng). Do đó, các kiến trúc sư phần mềm năm 2026 đang áp dụng chiến lược **Tìm kiếm lai (Hybrid Search)**—sự kết hợp hoàn hảo giữa tìm kiếm từ khóa truyền thống (BM25) và tìm kiếm ngữ nghĩa vector:
- Tăng độ chính xác kết quả tìm kiếm lên 35%: Hybrid Search kết hợp điểm số của cả hai phương pháp, đảm bảo vừa bắt được ý nghĩa tổng thể vừa không bỏ sót các từ khóa chuyên biệt.
- Tăng 50% tỷ lệ nhấp chuột (CTR): Các trang thương mại điện tử và hệ thống quản trị tri thức doanh nghiệp áp dụng Hybrid Search ghi nhận sự bứt phá lớn về trải nghiệm người dùng.
- Tối ưu hóa chi phí phần cứng: Áp dụng các kỹ thuật nén vector như Product Quantization (PQ) giúp cắt giảm chi phí lưu trữ bộ nhớ RAM của hệ thống Vector DB lên tới **75%**.
5. Kết luận
Cơ sở dữ liệu Vector không chỉ là một công nghệ lưu trữ mới, mà là thành tố hạ tầng cốt lõi trong thời đại AI. Doanh nghiệp làm chủ kiến trúc Vector Search và RAG ngay hôm nay sẽ sở hữu lợi thế cạnh tranh khổng lồ trong việc khai phá giá trị từ khối tài sản dữ liệu phi cấu trúc của mình.
Trong kỷ nguyên AI, dữ liệu không chỉ cần được lưu trữ, nó cần được hiểu theo đúng ngữ nghĩa.