1. Sự mong manh của Prompt Engineering thủ công: Rào cản lớn nhất của AI doanh nghiệp
Trong giai đoạn đầu bùng nổ của AI tạo sinh (2023 - 2025), khái niệm 'Prompt Engineering' (Kỹ nghệ viết câu lệnh) đã được ca ngợi như một kỹ năng hot nhất, mở ra cánh cửa giao tiếp với các mô hình ngôn ngữ lớn (LLM). Hàng ngàn kỹ sư đã dành hàng giờ để mày mò, thử sai (trial-and-error) từng từ, từng dấu phẩy để ép LLM đưa ra kết quả mong muốn. Tuy nhiên, khi các doanh nghiệp bắt đầu đưa AI vào môi trường sản xuất thực tế (production) trên quy mô lớn, họ nhanh chóng nhận ra một sự thật phũ phàng: Prompt viết tay thủ công cực kỳ mong manh và thiếu ổn định.
Khảo sát các kỹ sư phần mềm năm 2026 cho thấy, khoảng 80% thời gian phát triển ứng dụng AI đang bị lãng phí vào việc thử sai viết prompt. Chỉ cần một thay đổi nhỏ về từ ngữ, hoặc nghiêm trọng hơn là khi doanh nghiệp nâng cấp/chuyển đổi mô hình LLM nền tảng (ví dụ từ GPT-4 sang Gemini 1.5), hiệu năng của toàn bộ hệ thống sử dụng prompt viết tay có thể bị sụt giảm nghiêm trọng lên tới 40%. Mã nguồn phần mềm truyền thống đòi hỏi tính nhất quán và có thể kiểm thử (testable), trong khi prompt viết tay lại mang tính cảm tính, mơ hồ và không thể đo lường. Điều này tạo ra rào cản khổng lồ ngăn chặn việc xây dựng các ứng dụng doanh nghiệp đáng tin cậy.

2. Bước vào Kỷ nguyên Post-Prompting: Khái niệm và Triết lý mới
Để giải quyết triệt để sự mong manh của prompt thủ công, thế giới công nghệ năm 2026 đang chứng kiến sự chuyển dịch mang tính lịch sử sang **Kỷ nguyên Post-Prompting** (Hậu Prompt). Triết lý cốt lõi của kỷ nguyên này là: Lập trình viên không nên tự tay viết prompt nữa. Thay vào đó, prompt sẽ được coi là các tham số hệ thống cần được tối ưu hóa bằng lập trình và thuật toán tự động.
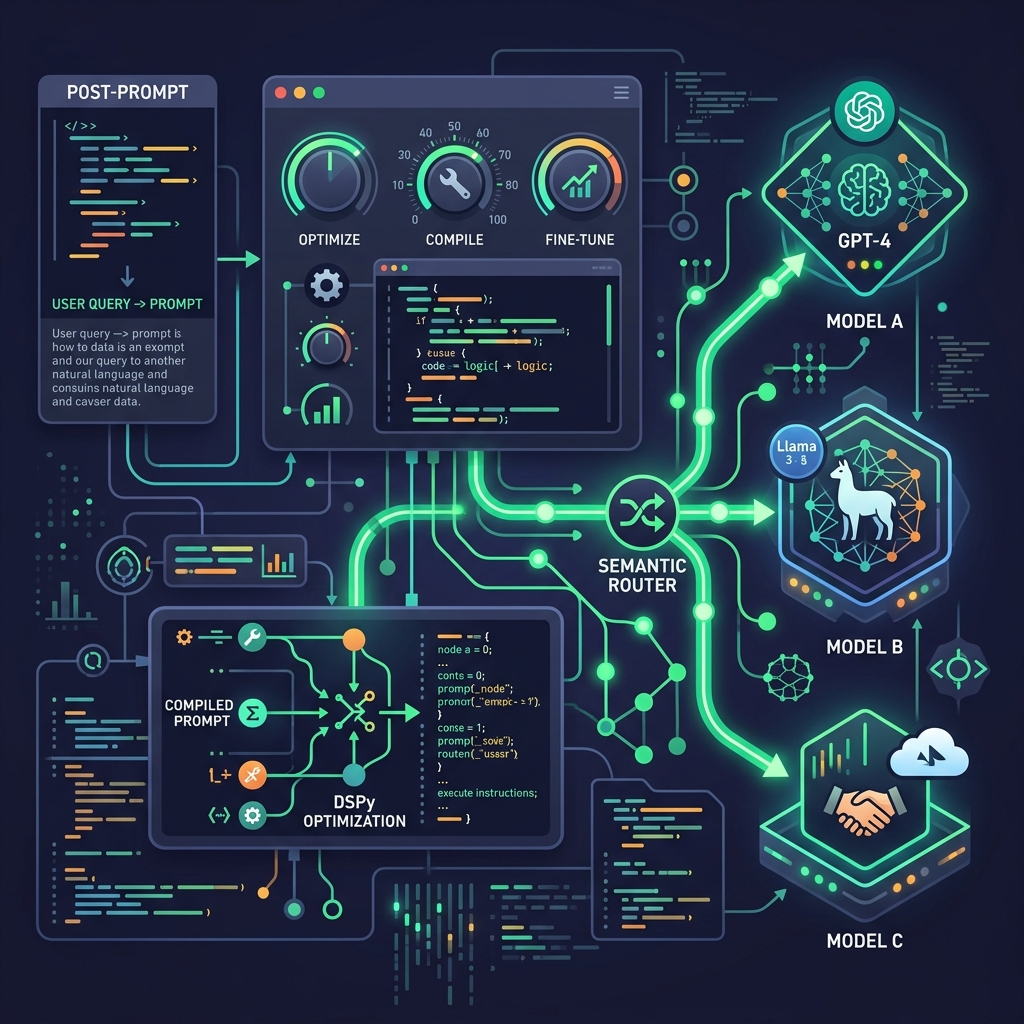
Thay vì viết các chuỗi ký tự hướng dẫn dài dòng, lập trình viên định nghĩa các luồng xử lý dữ liệu (pipelines) dưới dạng các module lập trình sạch sẽ. Hệ thống sẽ tự động tìm ra prompt tối ưu nhất, tự sinh các ví dụ mẫu (few-shot examples) chất lượng cao dựa trên tập dữ liệu kiểm thử và mục tiêu đầu ra được chỉ định trước. Hai công nghệ mũi nhọn đại diện cho cuộc cách mạng này chính là framework **DSPy của đại học Stanford** và giải pháp định tuyến ngữ nghĩa **Semantic Router**.
3. Stanford DSPy: Biên dịch và tối ưu hóa Prompt tự động bằng mã lập trình
DSPy (Declarative Self-improving Language Programs) là framework nguồn mở mang tính đột phá được phát triển bởi nhóm nghiên cứu NLP của Đại học Stanford. DSPy tách biệt hoàn toàn cấu trúc logic của chương trình (Program Architecture) ra khỏi cấu hình chi tiết của prompt (Prompt/Few-shot settings).
Cách thức hoạt động của DSPy:
- Định nghĩa Signature (Chữ ký): Lập trình viên chỉ cần mô tả đầu vào và đầu ra dưới dạng code (ví dụ: `input: tài liệu kỹ thuật -> output: mã code tối ưu`).
- Trình tối ưu hóa tự động (Teleprompter/Optimizer): DSPy sẽ tự động chạy thử nghiệm trên tập dữ liệu huấn luyện của bạn, thử nghiệm hàng chục biến thể prompt khác nhau, tự động lọc và chèn các ví dụ few-shot hiệu quả nhất.
- Biên dịch chéo mô hình (Cross-model Compilation): Khi bạn muốn chuyển đổi từ mô hình lớn đắt đỏ như GPT-4 sang mô hình nhỏ nội bộ như Llama-3-8B, bạn chỉ cần bấm nút 'Compile' (biên dịch). DSPy sẽ tự động tối ưu lại bộ prompt dành riêng cho Llama-3. Kết quả thực nghiệm chứng minh, mô hình nhỏ 8B được tối ưu bằng DSPy có khả năng đạt hiệu suất tương đương 95% so với mô hình lớn chạy prompt thủ công, giúp nâng cao độ chính xác của hệ thống thêm 30% đến 45%.

4. Semantic Router: Bộ định tuyến ngữ nghĩa siêu tốc triệt tiêu độ trễ
Song song với việc tối ưu hóa nội dung prompt của DSPy, bài toán định tuyến yêu cầu (query routing) cũng được cách mạng hóa bằng **Semantic Router** (Bộ định tuyến ngữ nghĩa). Trong các hệ thống cũ, để phân biệt xem người dùng muốn 'mua hàng' hay 'hỏi đáp kỹ thuật', lập trình viên phải gọi một LLM lớn để phân tích intent (ý định), gây ra độ trễ hàng giây và tiêu tốn chi phí API không cần thiết.
Semantic Router giải quyết bài toán này bằng cách sử dụng các mô hình nhúng vector (embedding models) siêu nhỏ và thuật toán so khớp độ tương đồng ngữ nghĩa cục bộ:
- Định tuyến siêu tốc dưới 10ms - 20ms: Thay vì gửi request lên đám mây, Semantic Router phân tích vector ngữ nghĩa của câu hỏi ngay trên máy chủ cục bộ chỉ trong vòng chưa đầy 10ms - 20ms (nhanh hơn gấp 100 lần so với dùng LLM), ngay lập tức chuyển hướng câu hỏi đến đúng module xử lý chuyên biệt.
- Tiết kiệm 60% chi phí API: Bằng cách định tuyến chính xác các câu hỏi đơn giản về cho các mô hình nhỏ (SLM) nội bộ xử lý và chỉ chuyển các câu hỏi thực sự phức tạp lên mô hình đám mây, doanh nghiệp tiết kiệm được phần lớn ngân sách vận hành hệ thống AI.

5. Lời kết: Tương lai của phát triển ứng dụng AI bền vững và có thể mở rộng
Kỷ nguyên Post-Prompting đánh dấu sự trưởng thành của ngành kỹ nghệ AI, chuyển dịch từ một bộ môn nghệ thuật 'thử sai' cảm tính sang một ngành khoa học kỹ thuật lập trình chính xác, có thể đo lường và tối ưu hóa tự động.
Bằng việc tích hợp các công cụ mạnh mẽ như DSPy và Semantic Router vào kiến trúc hệ thống, các doanh nghiệp và nhà phát triển phần mềm không chỉ giải quyết triệt để bài toán độ trễ và chi phí vận hành, mà quan trọng hơn là xây dựng được những ứng dụng AI có tính ổn định cao, sẵn sàng mở rộng quy mô phục vụ hàng triệu người dùng trong tương lai số.
Đã đến lúc ngừng viết prompt thủ công và bắt đầu biên dịch chương trình AI của bạn. Hãy đón đầu kỷ nguyên Post-Prompting ngay hôm nay!